

Transcripted Summary
I want to walk you through how to build an element classifier using AI, as this is what's used in the Appium AI plugin.
So, what you do, just like with all machinery, or typical machinery, is you get a bunch of examples, trending examples, right? We went out and grabbed a bunch of screen shots of shopping carts, all different kinds from all different types of apps and put them in, magically, a thing called a folder.

And we did that for a lot of other common things that are in the applications like search icons, tags, share buttons, so on and so forth.
Then we use this thing called TensorFlow. It's beyond the depth of this course, but we've wrapped it all up for you, so you don't have to worry about how that works. This is the machine-learning training system, it's open source and made by Google.
We took a specific instance of TensorFlow that somebody had already trained called MobileNet, which had been trained on pictures of things in mobile apps. They pre-trained it with hundreds of thousands of images. For people who have been using mobile apps extensively, they are trained to recognize what things in mobile apps look like. This works the same way - as a pre-trained brain.
And then what we do is we train it against those very specific images that we need to identify for a classifier, for picking out elements, for interacting with parts of mobile apps to automate them.
You really only use two command lines to train it to learn new images.
There's the retrain.py. You just pass the directory to the folder that has all the training image in it and you let that run.
python retrain.py --image_dir training_images/ --output_graph output/saved_model.pb --output_labels output/saved_model.pbtxt --how_many_training_steps 4000 --learning_rate 0.30 --testing_percentage 25 --validation_percentage 25 --eval_step_interval 50 --train_batch_size 2000 --test_batch_size -1 --validation_batch_size -1 --bottleneck_dir /tmp/bottleneck
Now the clean machine will take about two, three hours on a high-end MacBook pro, but it will finish, and it will produce a training model. The same model that fits in the model file for the test AI app you plug in. Just a couple of files.
And then, after that's trained you can use it (we'll talk about how it's trained in a bit).
Just call run_model.py — you give it an image and it will tell you how much confidence it has that it's a shopping cart, or whatever kind of element you're training it for.
python run_model.py cart.png
So, this is how the training works under the hood, this is what's going on when you train the classifier.
There is a training infrastructure, which is the TensorFlow code, that lets you show the AI all those different images from the folders that we have. You start with a little neural network brain that's semi-initialized with MobileNet. And then we start showing it all of our examples of application-specific things like shopping carts and so on and so forth.
Let's give it a shopping cart. Technically, the AI can't actually see; it doesn't have eyeballs. But what we can do is pass it a lot of things about the image.
- We can tell it to go across every pixel and get the average color of the pixels in this image.
- We'll can computer the number of edges
- We can also do things like stretch or shrink the icon to 128 x 128-pixel image and then pass each one of those pixels into the neural network as a feature.
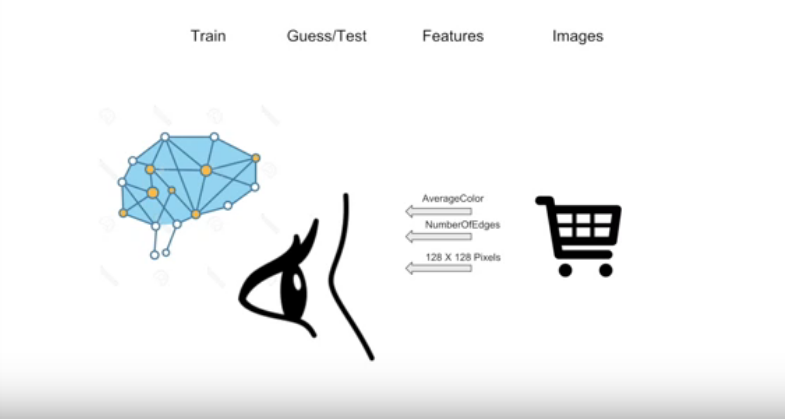
So, we give it a bunch of data which is really an array of flowing point numbers between zero and one. Just a little flat matrix of all these little bits of data about the image, and that gets passed to the "brain."
Then if you ask this brain "is this a cart?", the brain will say, "This is not a cart.". It guesses wrong because this is the first time it's ever seen a shopping cart. It hasn't been fully trained yet.
And then what happens, though - and this is where the magic happens - is back in TensorFlow under the hood, it will change the graph. The magic of that is deep in the bowels of machine learning. But we can just use it here with a little API call. So, what do we do? Ah, you guessed it. We give it another shopping cart - this one looks a little bit different. But if you think about it, it probably has a very similar average color as the last one. It probably has similar number of edges, because you know it's got wheels and a box for the cart, versus any other kind of random image on the internet. It might even share some of the pixels, or white or black, as the last shopping cart.
So, we give it this data and guess what the brain does? It says, "Oh this is a cart."
We've got a good robot, right, a good neural network. You figured it out for this one. Now it may have got it right accidentally but what we do is reinforce that. So, we go in and we say hey, whatever these connections were that decided that this thing was a shopping cart, awesome. Remember those things, this is a good configuration.
Then we pass it something that's not a shopping cart. These are anti-examples. We give it, say, a search icon, and it may have a same-average color, but it probably has a very different number of edges, though, right?
And we let the brain look at that, and it says, "Ah, is that a cart?" And we say, "No robot, you didn't do it. We thought you'd do it, and you failed us. You failed, failed, failed."
But we do this tens of thousands of times. So, it fails tens of thousands of times, and it succeeds tens of thousands of times. So, it goes back in and you guessed it, it cuts some of the network. It changes the network up, because it knows: "However I got myself configured right now, it's not very good". Let me try again, and let's pass it that original shopping cart.
So, after we've trained the model with the retrain_model.py file, we can then run the other Python file run_model.py
Very simple. All it does is loads up the TensorFlow framework and loads up our particular brain (model) that we've trained. We give it an example file, in this case called cart.png and it outputs the probability that it thinks it's a cart versus a search box, versus anything else. So, in this case it is 0.793794% sure that this is a shopping cart.
So, we've taught a machine how to kind of see images and determine whether they're a shopping cart or not.
In the open source classifier, there's a little under 100 different types of elements and applications that we've trained it on. For every one of those folders, there's a bunch of examples and then we just batch-train like we just learned how to do it—teaching the machine how to recognize these different parts of applications, these common parts of applications.
What it does have problems with though are things like arrows and share buttons and downloads and rewind. Guess why? They kind of look the same and a lot of apps will use a left arrow for rewind, for example. So, AI needs lots more examples of those types of things to be able to differentiate them.
We basically took this data and added more images, more training data in different categories based on which classifications needed more training data. All that stuff is open source, again, up on Github - all the data, all the code, the Python files (resources below). You can go there, download it, build local, and with a few command lines, you call yourself a machine learning engineer.
Resources
- Classifier Builder
- Appium Classifier Plugin on Github
- List of Identifiers
- Classifier Builder Retrain
- Appium Plugin Architecture Doc - Element Finding Plugins
