

Transcripted Summary
Learning in production is a huge topic, but it's an important aspect of automation and DevOps.
Knowing some of the concepts and terminology will help you talk to your team about it. We’ll look at ways that teams operate their production environments and respond to problems.
I'm avoiding talking about specific tools, since those change all the time. You should work together with your team to learn to use the tools your teams has in place. Or plans to have in place.
Again, going back to the State of DevOps report and what makes teams successful with continuous delivery — they found that monitoring, observability and continuous testing are key practices.

What could your team learn from production?
Pause the video here and think back to a time when you thought your team had done a thorough job of testing, but after your release, you had a terrible production failure that was a case you had not even thought about it. These “unknown, unknowns” can really get us.
Our test environments can never fully emulate production, and we can't anticipate every way customers will use our product.
It's not realistic to think that we can test everything, though in certain domains, like safety critical ones, we might need to. If we can respond quickly to production failures, then we can take advantage of technology to help us identify problems in production or we can also learn what features the customers really want and use.
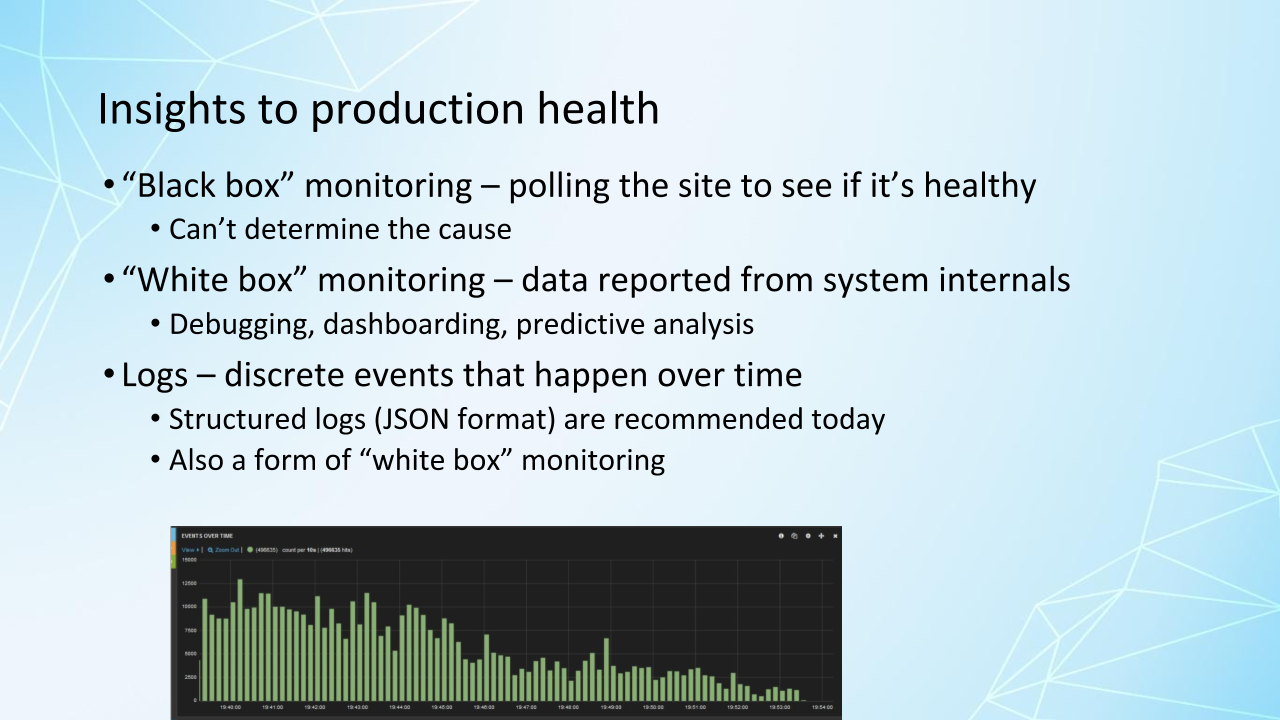
Traditionally, much of the learning was derived from black box monitoring methods — and black box monitoring refers to observing a system from the outside.
So that's useful to see the symptoms of a problem. Our site is down, but not necessarily the root cause. Our site is down because the database went down.
White box monitoring is referred to a category of monitoring tools and techniques that work with the data reported from the internals from a system.
So together with request tracing, metrics and logs, these are things that help us with observability. We'll talk about that in a minute.

Here's a quote from Chrissy Kidd, defining monitoring: "Instrumenting an application and then collecting, aggregating and analyzing metrics to improve your understanding of how the system behaves."
We can set up alerts, although we want to do that wisely. Again, this is something the whole team needs to do, to decide together.

Logging is reporting errors and related data in a centralized way, so developers can instrument the application code to log information about each event in the system. And there's other things that log information, such as application servers.
And structured logging can provide valuable insights that's usually in a JSON format. But this can be expensive.

When a problem does occur, tracing allows you to see how the problem occurred.
- Which function was going on?
- How long did that function last?
- What parameters were passed?
- How deep into the function was the user?
Tracing shows individual journeys through the application. It can be valuable in identifying bottlenecks, though the tools can be expensive, because it does take large amounts of data to process.
This is focused on the application, and not the underlying infrastructure. Today's tracing tools can deal with huge amounts of data and often use machine learning to help analyze it.

Metrics are numbers measured over intervals of time, so they are cheaper and easier to store and process than logs.
Metrics are generated by applications and operating systems, so they're a good place to start monitoring and you can know if a particular resource is up or down. Just one example of a widely used tool for metrics is Prometheus.
And speaking of widely used tools, I've heard people often use the acronym, ELK.

This is a commonly used open source tool stack.
I'm not recommending it one way or the other, just to show that this is one stack of tools that provides a database for logging data, providing a search engine. A way to get the log information from your servers to the database, and then a way to query the database and have visual dashboards and analytics to help you quickly see patterns and problems.

Observability is what's required in order to gain visibility into the behavior of applications and infrastructure. And some people have even said that it's more important, even in unit tests.
Charity Majors is one of the leaders in observability, and she says it’s about being able to ask arbitrary questions about your environment without knowing ahead of time what you want it to ask. So, for monitoring, if we want to set up alerts, we have to anticipate what problems might happen. This is more for the “unknown unknowns”.
Observability tools tell us how a system behaved in the context of production environment, unpredictable inputs, unpredictable system behavior and user behavior.
All the data and tools that we have at our disposal let us identify problems and then dig down, really fast, to see exactly what happened.

We can pinpoint it even to an individual user, so we can quickly reproduce those errors and quickly stop the customer pain by reverting the latest change or deploying a hot fix for the error that we found.
Chaos engineering is another way we do testing in production.

Like observability, it helps find the “unknown unknowns”.
There are different approaches to this, but I like the one Sarah Wells uses, where it's thoughtful and planned experiments done safely in production, or tests reveal system weaknesses. We have a hypothesis, and an evaluation. We do the test and evaluate whether what we expected to happen, did.
Chaos Monkey is a tool that Netflix produced to do their chaos engineering and that was a little bit more random and just trying different random things to see what happened. And of course, having people on hand in case it caused terrible problems. There's a lot of tooling coming out for this, a lot of products coming out for this, so it's kind of a new area to get involved with.
We can automate regression tests in production and take advantage of testing in the actual production environment if we can do it safely.
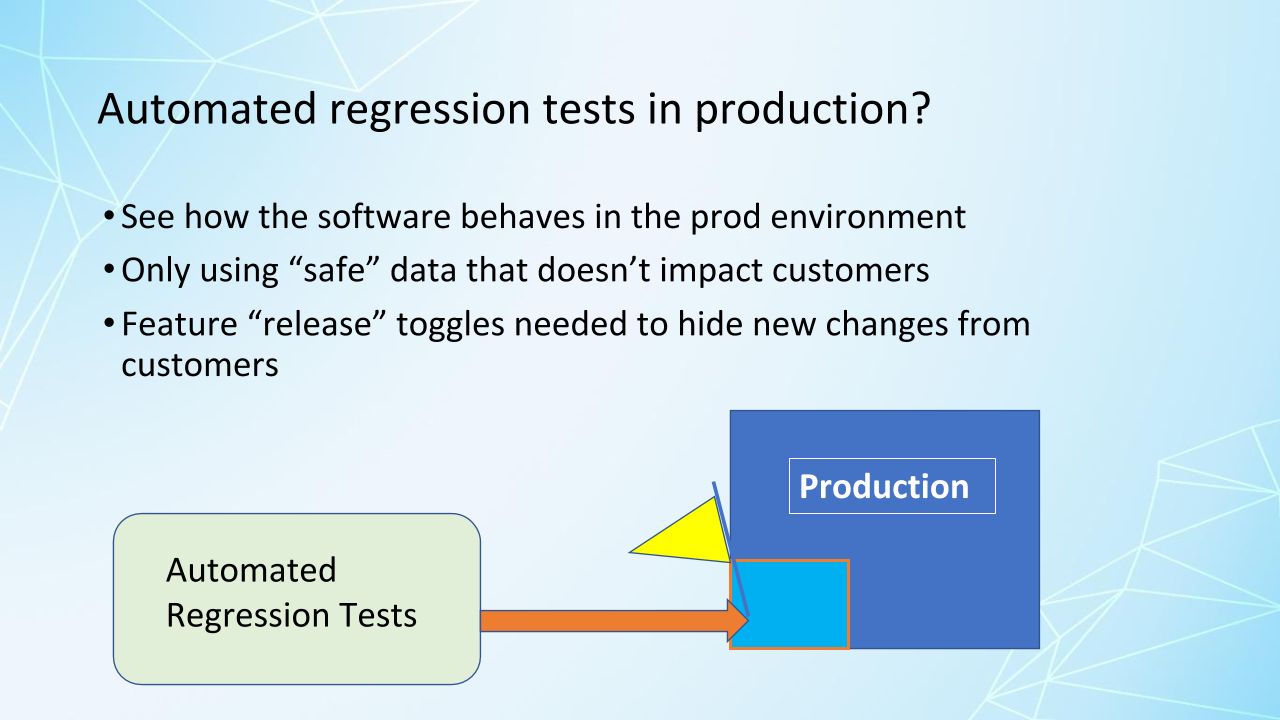
So, as long as we don't impact customers and as long as we can hide the features we're testing, if we want to, from customers, by using feature release toggles. And this can be a really important way to see how things behave in production. So automated regression tests are not just for your test environments.
Testing in production — I mentioned chaos engineering as one way to do that — and that does not mean letting customers find our bugs.

It's only feasible with observability and the capability to quickly revert or fix a problem. So, because we can deploy to production without releasing the changes, thanks to feature toggles and other means, such as canarying and dark launches, we're able to do this.
Cindy Sridharan says that she'd argue that being able to successfully and safely in production requires a significant amount of automation — a firm understanding of best practices as well as designing the systems from the ground up to lend themselves toward this form of testing. So, it's an important source of information and important way that we can be confident that we're continuing to deliver reliable, business value to our customers.
And we can learn more that will feed into new or updated features to make our customers even happier.
I really like this model from Cindy Sridharan (@copyconstruct on Twitter — you may know her better that way).

So, we still are doing testing, or still doing our best effort to test before we release, we're trying to simulate production, but for the things we couldn't simulate, we're going to monitor for things we think might happen in production and get alerts for that.
And for everything else, we're going to use observability to ask those questions when problems happen. We're covering all our bases.
So, if you're a tester, what does this mean for you?

Abby Bangser has said that observability is a bridge to ops for testers, because our skills such as critical thinking, exploratory testing and spotting patterns are ideal for observability. Chaos engineering also requires those skills and Sarah Wells says, "Chaos engineering is a form of exploratory testing."
So, the metrics can help us spot potential issues, the logs can help us pinpoint problems and you don't need to do this all by yourself. Get together with your teammates, ask questions, see what patterns you notice. Do learn to use the tools and your teammates will help you; and we also have lots and lots of online resources to learn more about these tools.
In our last chapter, we'll talk about how to get the whole team engaged.
Resources
Guide: Achieving Observability by Charity Majors - honeycomb.io pdf
“Tracing versus logging versus monitoring: What’s the difference?” by Chrissy Kidd
“Monitoring demystified: A guide for logging, tracing, metrics” by Mitch Pronschinski
“What is Chaos Engineering” by Joe Colontonio (includes link to podcast with Tammy Butow)
“Interview: For the FT’s Sarah Wells, it’s problem first, tech second” - DevClass
“An Introduction to Metrics, Monitoring, and Alerting” by Justin Ellingwood
