

Transcripted Summary
We've looked at some basic examples of pipelines. What might be in your own team's pipeline? Let's look at some possibilities.
These are some examples of pipeline stages.
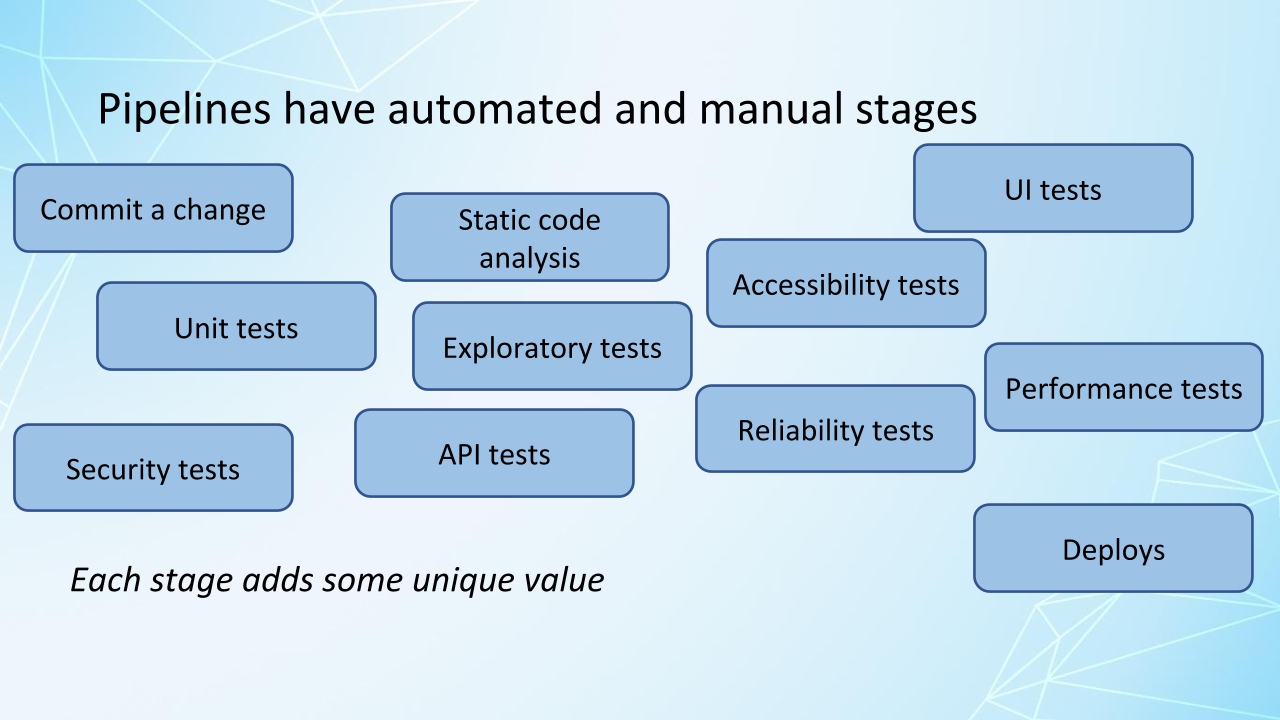
Each stage in your pipeline should add some value, some unique value in some form.
It could be confidence from passing tests, it could be the ability to do some manual testing by deploying to a test environment, or letting other users do user acceptance testing. Lots of different possibilities.
One way to start thinking about your team's pipeline is by considering the steps you would go through to get an urgent fix out to production.

You might not do all the same steps or stages as you would to deliver a routine code change to production.
I encourage you to pause the video and think about the scenario. What has to happen before an emergency fix gets out to production? And remember, even if you're on a team that doesn't have continuous integration yet, you still have a pipeline, it's just that all the stages are manual.
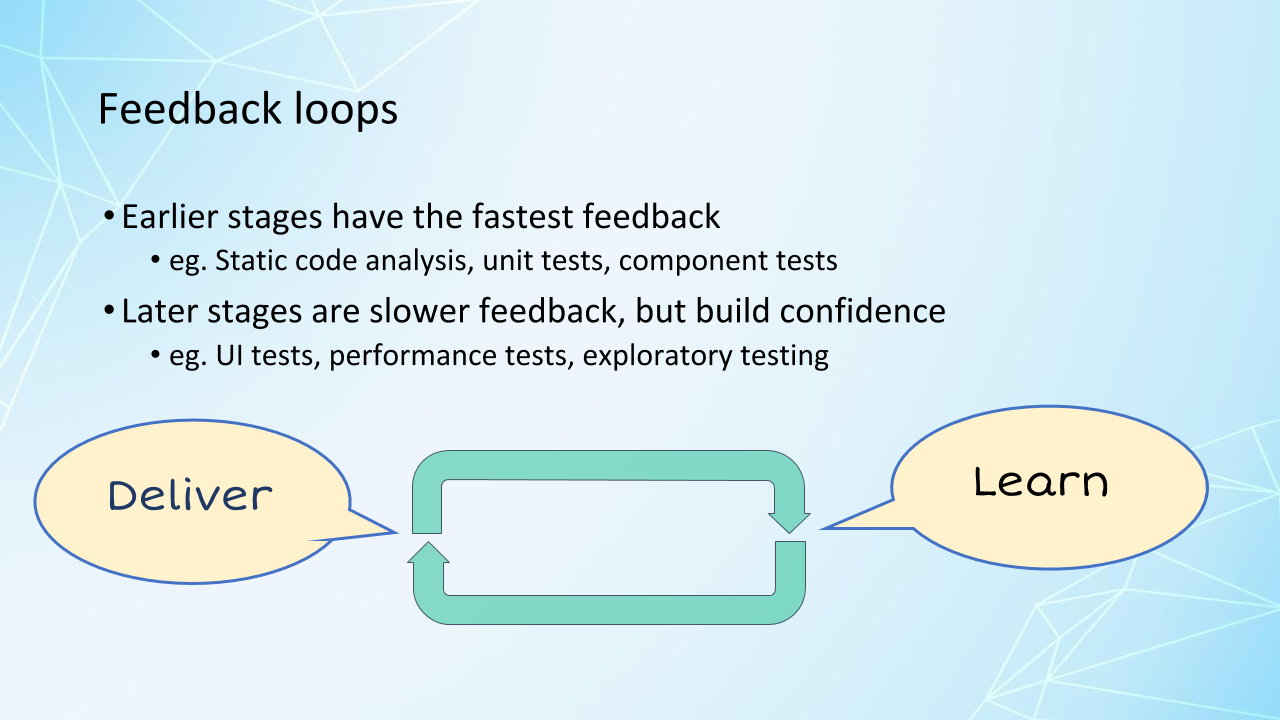
As each stage in our pipeline executes successfully, it builds more confidence in that release candidate, so things like code analysis and unit tests are really fast feedback and we run those first because we want to catch the obvious problems first.
The later stages take longer, but they keep building our confidence.
As I said, each stage in our pipeline should be designed to get some information of value to someone on the team.

Today's tools let us send notifications and test results automatically to whoever needs them. That could be through email or Slack or some kind of desktop application.
Think about how each stage gets started.
If we have our pipeline configured so that each stage asks the next stage to start after it is successful, that's called pushing.
Or, if we give each stage prerequisites to pull or listen periodically to the stage before it, that's called pulling.
There's no right or wrong either way, but you just need to be careful that if a stage is started and the previous stage wasn't really totally successful, a problem might go undetected or it might be hard to diagnose when it shows up later.
We look for test suites that we can run in parallel for faster feedback, but we need to watch for dependencies.
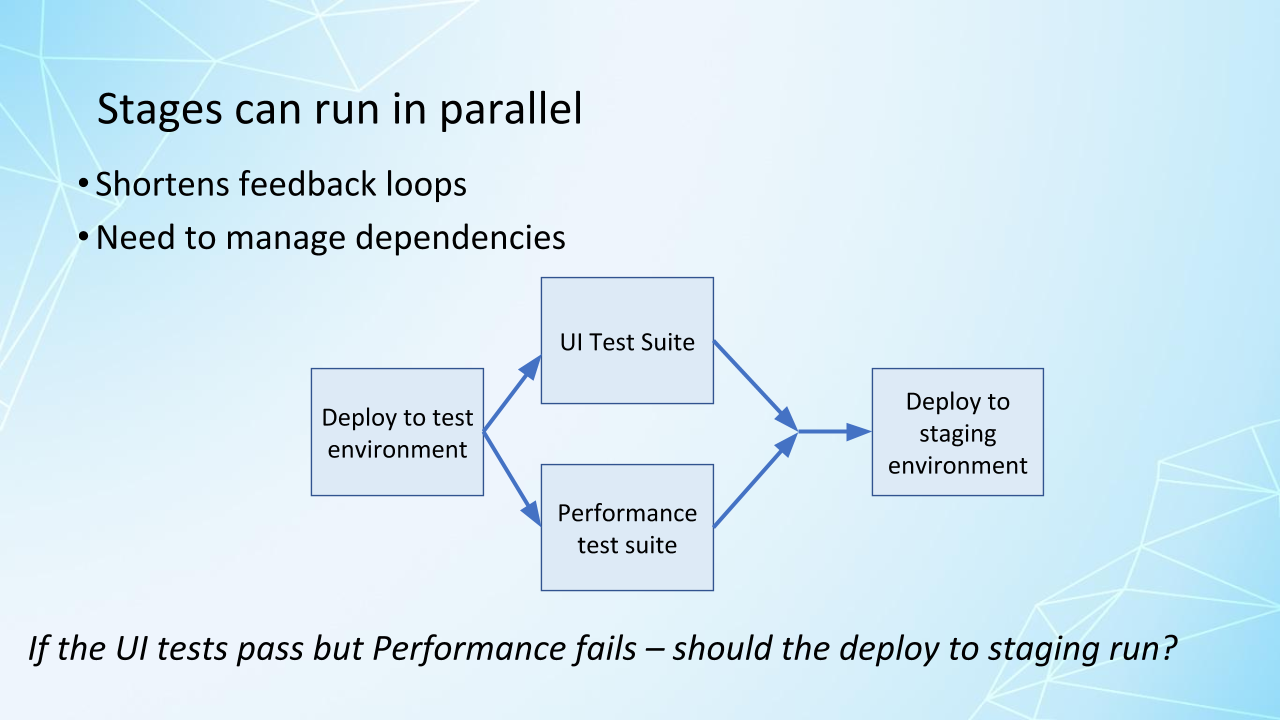
Here we're seeing something called fan-in dependency management.
We have two stages, a UI test suite and a performance test suite that are running in parallel and when they're both successful, there's a deploy to a staging environment as the next stage.
Or do they both need to be successful? Is there a case in which we would keep deploying to the staging environment even if perhaps the performance test suite failed?
These are team decisions that we have to make, but we have to be aware of the potential dependencies and the possible risk when stages fail of continuing on.
I encourage you to get together with your team and visualize your team's pipeline.

It's a powerful exercise that you and your team can do in an hour or less.
You visualize your pipeline by writing stages on cards or sticky notes. This is just a starting point to start looking at your pipeline and improving it. Set out those cards or sticky notes to represent how your pipeline works and how it looks.
Note down the value of each step.
Who needs to know the results of that stage?
Who's alerted if that stage fails? How are they alerted?
How long is the feedback loop from each stage? So, from when you commit a change to the code base to when you get the feedback that something succeeded or failed, how long is that?
Do you see any ways to shorten those feedback loops? Are there more steps that you could parallelize?
What are the dependencies between stages? Do you have dependencies to external systems?
Could you use test doubles to stub, fake, or mock out those external systems to reduce those dependencies?
What kind of gates are in the pipeline? For example, what has to be true to know you're ready to deploy to a test environment? Are there certain tests that have to have succeeded by that point? Or to staging or production?
Again, don't forget the manual steps like exploratory testing.
I have some resources to help you do this pipeline exercise and you can do it periodically to keep improving your pipeline over time, step by step.
With our pipelines, our goal is to have fast, consistent feedback and actionable alerts if something goes wrong to give us confidence for continuous delivery or deployment.
And again, if you'd like to try that pipeline visualization workshop, I have a link to it in the resources.
In the next chapter, we're going to talk about formulating your test automation strategy for DevOps.
Resources
- The Whole Team Approach to Continuous Testing (Chapter 1) by Lisi Hocke – TAU Course
- Materials for a pipeline visualization workshop, Abby Bangser and Lisa Crispin (from European Testing Conference 2017)
- Go’s Dependency Management, Mark Chang, Thoughtworks
