

Warning!
This course was created with an older version of pytest-bdd.
Over the years, updates to the framework introduced backwards-incompatible changes.
The example project code and transcripts are updated, but the videos still show the old code.
Please review the pytest-bdd docs to see
specific syntax changes in newer versions.
Transcripted Summary
In the previous chapter, we wrote our first test using pytest-bdd. It was pretty simple and basic.
However, if you noticed, the steps we wrote were not very reusable. All of those numbers were hard-coded, which means they could not be reused by other steps.
In this chapter, we'll take a look at how to parameterize steps so they can be reused by other scenarios.
Here's the feature file we wrote in the previous chapter.
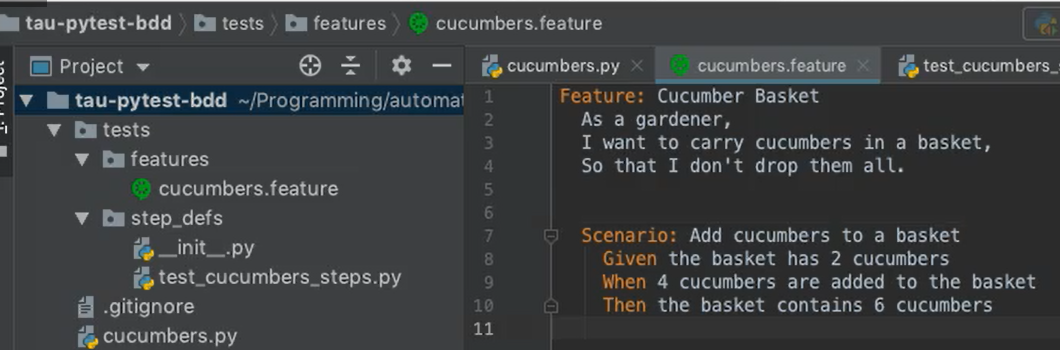
If we wanted to parameterize these inputs, the most common Gherkin convention is to surround the input values with double quotes.
Given the basket has "2" cucumbers
When "4" cucumbers are added to the basket
Then the basket contains "6" cucumbers
This lets the reader know, “Hey, this is a changeable value.” Now, this is not required by Gherkin, but rather a best practice.
If we want this to be truly parameterized, we'll need to update the step definition function behind the scenes in the Python code.
Adding parameters to step functions is actually pretty straightforward — what we'll need to do is import the parsers module from the pytest-bdd package.
Parsers provides a few different ways in which we can parse the values from those lines of Gherkin into meaningful arguments for our functions.
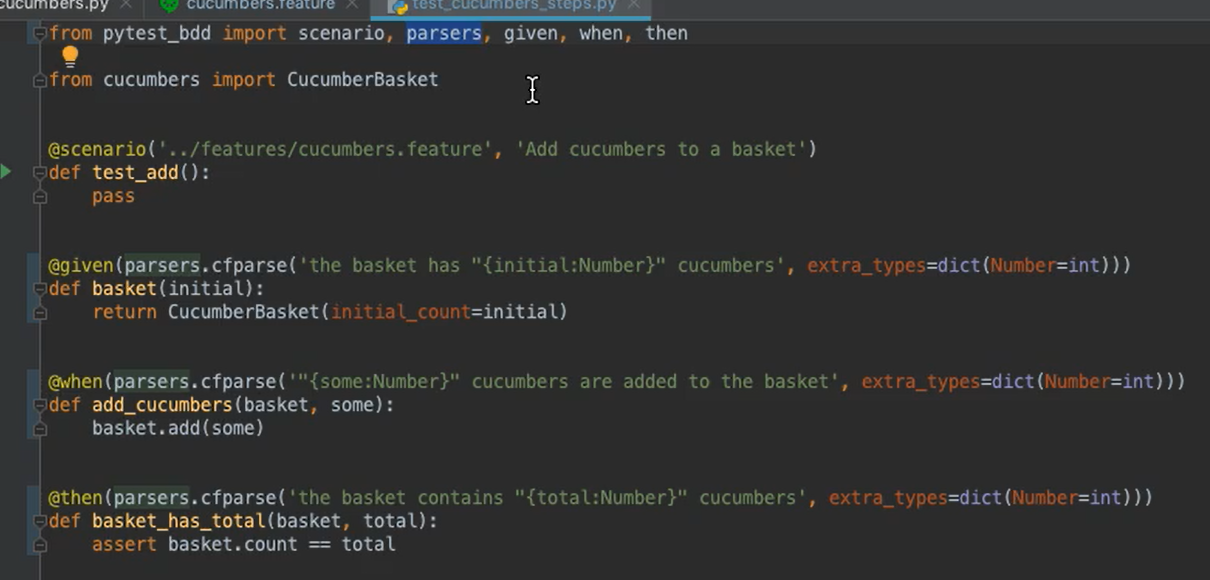
Here we're using the cfparse function. What we've done is instead of giving raw text Strings to our Given/When/Then decorators, we're giving a call to parsers.cfparse.
The first argument will be the textual line as a String with this interesting little parsing bit here:"{initial:Number}"
The squigglies [curly brackets] denote that this is the section we're going to look to parse.
The name of the variable [“initial”] is the identifier into which the parse value will be stored.
And the colon with the other identifier [
Number] denotes the type value to which to convert this particular value. If you didn't include this, it would default to be a String.However, if you want to convert it to say an integer, you can provide
extra_typesand convert whatever that identifier type name is to your desired Python type to do automatic conversion.
Once you have this value [“initial”], it will be passed into the step function as an argument, and then you can use it just like any other variable.
So here, instead of hard coding a 2 like we had before, I'm now passing in the initial value parsed from the step to be my initial_count from my CucumberBasket.
Likewise, the other number inputs work the same for the other steps.
So, for my When step: when some cucumbers are added to the basket, I'll pass in that some value into my step definition after the fixtures. And I can reference it here as baskets, adding some number of cucumbers [(basket:some)].
And for the total, the total number gets passed here, and then I assert my basket count is equal to the total instead of a hard coded 6.
I'd like to mention that there are 4 different ways we can parse steps.
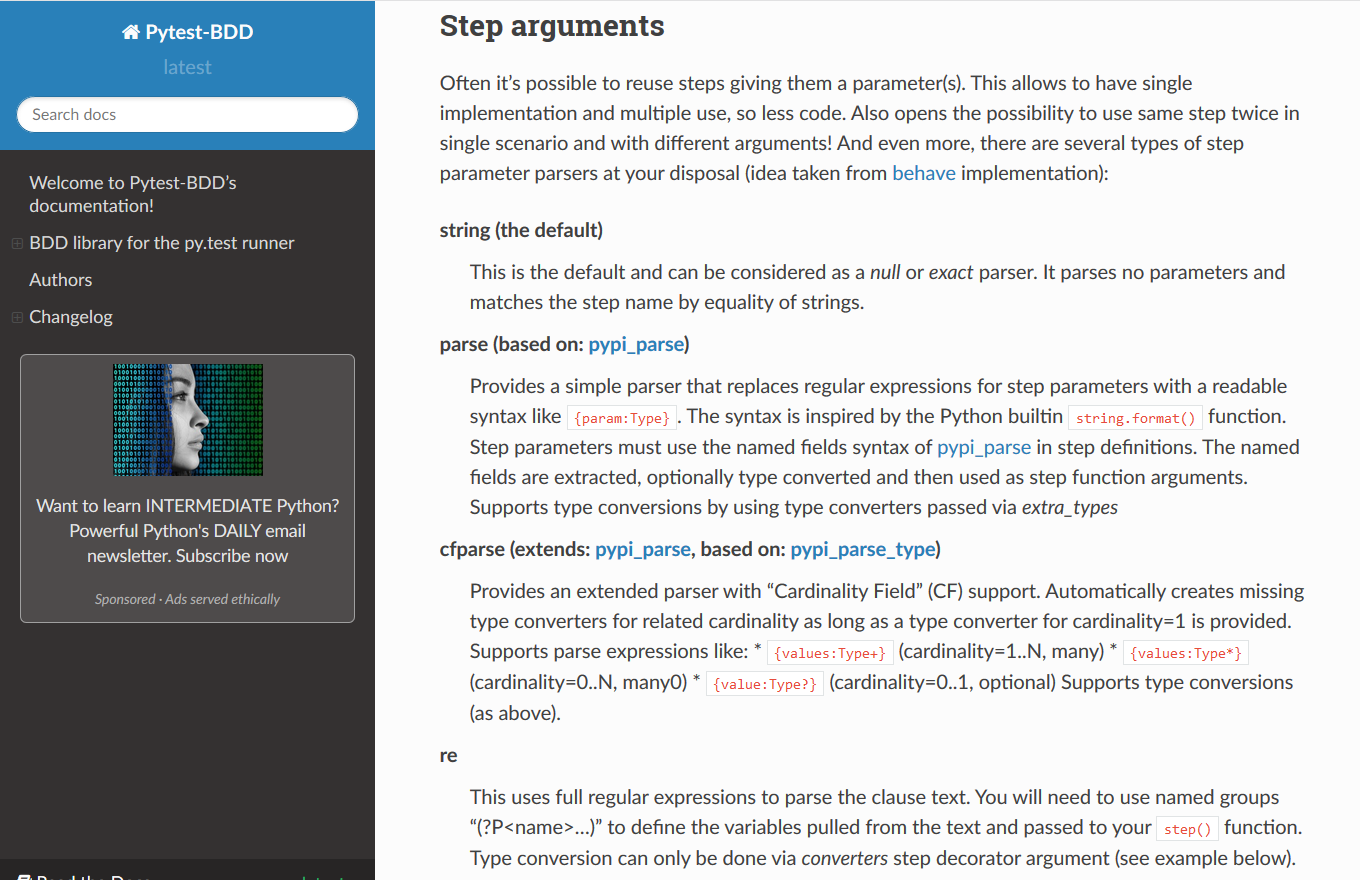
The first one is the way we saw in our first example just using Strings, nothing fancy.
The next more complicated way is the
parsemethod, which is based onpypi_parse, and that gives just some basic formatting.A more powerful one is what we used:
cfparsethat's based onpypi_parse_type, and it lets you do more interesting things like 1 to manies, or 0 to manies.And finally, if you really need the sledgehammer, the most powerful one is regular expressions [
re]. Anything you can do with a regular expression you can use to parse the step.
I recommend using the simplest one to meet your needs.
If we take another look at our feature file with all the steps updated for those parameter values, we can see that PyCharm automatically colors the inputs in blue, making them stand out a little bit more easily.
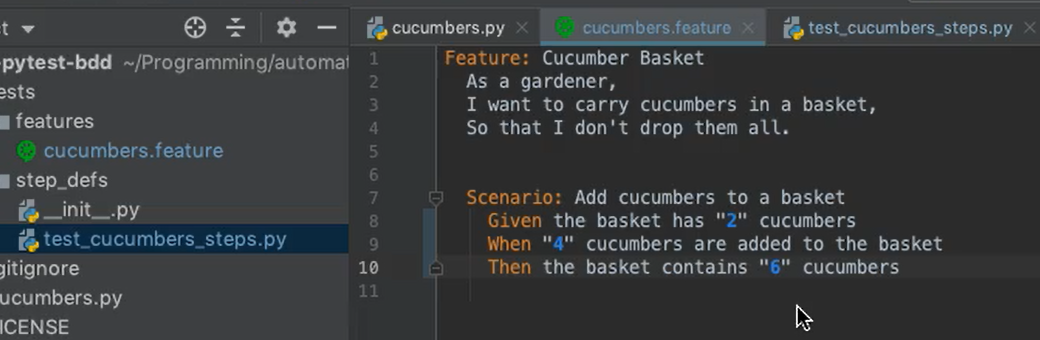
That's a really nice trick. Since we have the step definitions implemented now, let's run the test.
Boom. Everything passes. Nice.
As we said at the beginning of this chapter, having parameterized steps makes it easier for steps to be reused by other scenarios and thereby creating what we like to call a test automation snowball.
Here, I've added another scenario.
# cucumbers.feature
Feature: Cucumber Basket
As a gardener,
I want to carry cucumbers in a basket,
So that I don't drop them all.
Scenario: Add cucumbers to a basket
Given the basket has "2" cucumbers
When "4" cucumbers are added to the basket
Then the basket contains "6" cucumbers
Scenario: Remove cucumbers from a basket
Given the basket has "8" cucumbers
When "3" cucumbers are removed from the basket
Then the basket contains "5" cucumbers
This one, instead of adding cucumbers, removes cucumbers from the basket. Given the basket has 8 cucumbers, When 3 cucumbers are removed from the basket, Then the basket contains 5 cucumbers.
Notice how I've reused the Given and the Then steps.
Even though the scenario has 3 steps, the only new step I had to add is this one for removing cucumbers.
If I control-click to navigate to the step definition, you can see I've added that step here.
@when(parsers.cfparse('"{some:Number}" cucumbers are removed from the basket', extra_types=EXTRA_TYPES))
def remove_cucumbers(basket, some):
basket.remove(some)
It's very similar to the “add” one except, now I'm saying “removed”, and instead of calling the add method, I'm now calling the remove method.
Also note, I'll have to add a new scenario decorated test function so that I can run the remove cucumbers from a basket scenario in my feature file.
@scenario('../features/cucumbers.feature', 'Remove cucumbers from a basket')
def test_remove():
pass
If I run this test now…
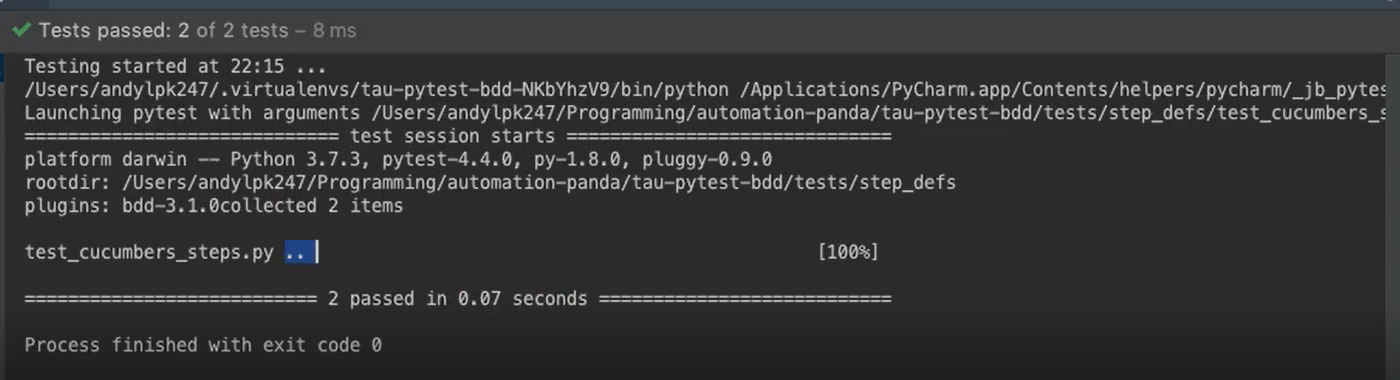
Notice how it runs 2 tests instead of just 2 also denoted by these 2 dots, and both of them are passing. Sweet.
As more tests are added to the feature file, it becomes a little cumbersome to always add a new test function for every single scenario.
We like to follow the principle of don't repeat yourself, and most times, we want to include all of the scenarios in the feature file when we've run our tests. Thankfully, pytest-bdd includes a helper function to do this.
It's called the scenarios function, and it works like this.
from pytest_bdd import scenarios, parsers, given, when, then
from cucumbers import CucumberBasket
scenarios('../features/cucumbers.feature')
Instead of declaring a new test method for every single one, we can call scenarios and provide the path to the “features” file.
Now, if we were to run this, we'll see that all the tests are included. See? Two 2 still passing. Awesome.
We can also avoid repeating ourselves with the extra_types.
If you notice, every single step function in this step definition module uses the same dictionary for its extra_types for parsing:
extra_types=dict(Number=int)
What I like to do is pull that dictionary out and then refer to it anytime I need to use those EXTRA_TYPES. That way all step functions in the module will have the same types of parsing going on.
# test_cucumbers_steps.py
from pytest_bdd import scenarios, parsers, given, when, then
from cucumbers import CucumberBasket
scenarios('../features/cucumbers.feature')
EXTRA_TYPES = {
'Number': int,
}
@given(
parsers.cfparse('the basket has "{initial:Number}" cucumbers', extra_types=EXTRA_TYPES),
target_fixture='basket')
def basket(initial):
return CucumberBasket(initial_count=initial)
@when(
parsers.cfparse('"{some:Number}" cucumbers are added to the basket', extra_types=EXTRA_TYPES))
def add_cucumbers(basket, some):
basket.add(some)
@when(
parsers.cfparse('"{some:Number}" cucumbers are removed from the basket', extra_types=EXTRA_TYPES))
def remove_cucumbers(basket, some):
basket.remove(some)
@then(
parsers.cfparse('the basket contains "{total:Number}" cucumbers', extra_types=EXTRA_TYPES))
def basket_has_total(basket, total):
assert basket.count == total
Another Python trick we can use to eliminate the duplication with these extra_types for parsing is using what we call a partial function.
What a partial function is, it's a wrapped function that will include part of the arguments for it, so that way you can call the partial function instead of the original function, and you won't need to pass things like extra_types to every single call.
Partial functions are part of the standard Python library
from functools import partial
If we want to make the `partial` function, let's give it a name:
parse_num=partial(parsers.cfparse, extra_types=EXTRA_TYPES)
The first argument will be the function that we're wrapping, which will be parsers.cfparse, and the subsequent arguments will be any arguments we want to have added automatically. In our case, it'd be the extra types.
Now instead of calling parsers.cfparse every time, I can call parse_num, and I can remove the extra_types.
# test_cucumbers_steps.py
from functools import partial
from pytest_bdd import scenarios, parsers, given, when, then
from cucumbers import CucumberBasket
scenarios('../features/cucumbers.feature')
EXTRA_TYPES = {
'Number': int,
}
parse_num=partial(parsers.cfparse, extra_types=EXTRA_TYPES)
@given(parse_num('the basket has "{initial:Number}" cucumbers'))
def basket(initial):
return CucumberBasket(initial_count=initial)
@when(parse_num('"{some:Number}" cucumbers are added to the basket'))
def add_cucumbers(basket, some):
basket.add(some)
@when(parse_num('"{some:Number}" cucumbers are removed from the basket'))
def remove_cucumbers(basket, some):
basket.remove(some)
@then(parse_num('the basket contains "{total:Number}" cucumbers'))
def basket_has_total(basket, total):
assert basket.count == total
And now the code is much more simple.
If I were to run it, everything's still passes. Woo hoo!
I do want to caution you though, if you choose to use partial functions to make your parsing a bit simpler.
Not all IDEs know how to handle it well. If you notice here in PyCharm, when I've given the partial function in each of my decorators, the arguments for the functions themselves are highlighted in yellow, and that's because PyCharm doesn't recognize that these inputs are parsed from these lines.
Even worse, if you look at the feature file, you'll notice that every single one of those steps is now highlighted in yellow again, as if it's not available. The tests run just fine as we saw, but the highlighting of the source is just not there.
So be careful with that.
If you want to be fully compatible, you may simply want to avoid the partial functions and do the classic way.
Resources
- GitHub Repo – Chapter 4
- Pytest-BDD Documentation
- pytest Official Site
- Automation Panda - Python Testing 101: pytest
- Automation Panda - Python Testing 101: pytest-bdd
