

Warning!
This course was created with an older version of pytest-bdd.
Over the years, updates to the framework introduced backwards-incompatible changes.
The example project code and transcripts are updated, but the videos still show the old code.
Please review the pytest-bdd docs to see
specific syntax changes in newer versions.
Transcripted Summary
Let's keep learning about pytest-bdd. In the previous chapter, we learned how to make steps in our scenarios more reusable by using parameters.
However, what if we wanted to use the same scenario but provide multiple combinations of parameters, so that we can choose the same steps but just give different inputs?
This chapter will show you how to do that using something called Scenario Outlines.
Here's the feature file we wrote in the previous chapter.
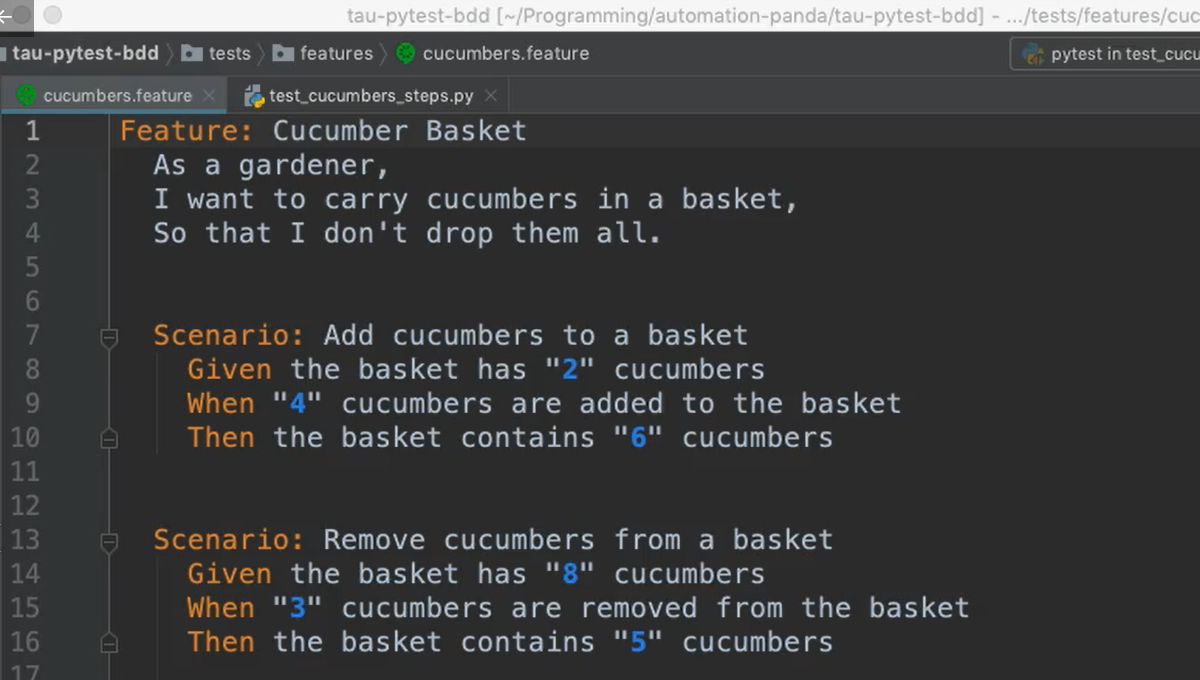
As we can see, it has 2 parametrized scenarios, but both have only 1 combination of inputs.
Let's turn this first one into a Scenario Outline.
First, we give it a new title — instead of Scenario, we call it Scenario Outline.
Then what we do is we give it something called an Examples table. You can give the Examples table a name like “Amounts” of cucumbers.
And what we want to do in the Examples table is provide all the different combinations of inputs we want for our scenario. That starts first by defining what the substitution variables will be.
In this case, I have 3 different values I care about. The initial value of cucumbers [“initial”], the number of cucumbers I'm adding [“some”], as well as the total number of cucumbers [“total”]. So, I'll write them as the header row in my Examples table.
In the subsequent Examples table rows, I'll give the different combinations of inputs.
So here, I'm simply using 2, 4, and 6 like I had used above.
Finally, I'll need to provide the substitution variables in my steps so that steps themselves, will get the parametrized values.
Notice how as I type the variable names for substitution. I put them between angle brackets. The angle brackets denote that the substitution from the Examples table should happen.
Scenario Outline: Add cucumbers to a basket
Given the basket has "<initial>" cucumbers
When "<some>" cucumbers are added to the basket
Then the basket contains "<total>" cucumbers
Examples: Amounts
| initial | some | total |
| 2 | 4 | 6 |
| 0 | 3 | 3 |
| 5 | 5 | 10 |
And if you're using PyCharm Professional, you'll also see the syntax highlighting light up. Boom, boom, boom. Nice.
Now that I have my variables in place, I can add other combinations as well. And just like that, we've turned a Scenario into a Scenario Outline with multiple input combinations.
You may be wondering, how large could this Examples table be?
There's actually no limit in Gherkin. You can use as many rows and as many columns as you want.
However, I would strongly caution you to try to keep the table size small. You should really only focus on equivalence classes of the input combinations you need. It's very, very tempting to make large tables to have wide test coverage, but just remember you don't always need to test everything.
Every test is going to incur runtime in a resources load. So just keep that in mind as you're developing your tests.
Now that we've written our Scenario Outline in our Feature file, it's time to update the step definition module to be able to run those new variations of the steps.
One thing that's a little frustrating with pytest-bdd is that you'll need to add a new variant or version of the step text in order to support Scenario Outline. It's not so bad though.
Let's take a look how we do it.
Let's start with the @given step.
NOTE
First of all, I want to note that in pytest-bdd it is allowed to give one step function multiple step decorators, so that you can have multiple step texts essentially point to one body of code. That's what we'll be doing for these Scenario Outlines.
Warning!
At this point, the video is showing outdated code. The example code in the repository is correct.
I'll start by duplicating the decorator, but now I'm going to change the call so that it can support the angle bracket version of the step for this Scenario Outline. Thankfully, it doesn't need a parser because it'll read this as plain text. And, that will able to match it successfully.
In order for the Scenario Outline to do the matching though against this substitution variable name, and thus be injected here as the fixture, we'll also need to update our scenarios function with something called examples converters[example_converters].
The examples_converters are basically a dictionary where each substitution variable name is mapped to the conversion type for the Python variable.
- In our case, we want to convert all of those values, those parameters, into integers.
- Then, in order for our
Scenario Outlineto pick up those converters, we simply add theexample_converterskeyword arg to ourscenariosfunction — so that way this converter dictionary will be applied to all thescenariosin this Feature File, which makes it pretty easy.
Now that we've seen that, let's just quickly go an update all these other steps in here.
Tip
It's useful to keep the old step version, or the original, or classic step version if you will, so that you can still use those steps in traditional scenarios. Having the 2 different types of step decorators just makes it a little bit easier to reuse these guys in the future.
Okay, and oops. Just one more here. As you can see, it doesn't take long to update them. Just a little bit of typing.
# test_cucumbers_steps.py
Warning!
The example code shown here in the transcript is up-to-date and will work with pytest-bdd version 6. It matches the code in the example repository. The code shown in the video is from pytest-bdd version 3 and is outdated.
from pytest_bdd import scenarios, parsers, given, when, then
from cucumbers import CucumberBasket
scenarios('../features/cucumbers.feature')
CONVERTERS = {
'initial': int,
'some': int,
'total': int,
}
@given(
parsers.parse('the basket has "{initial}" cucumbers'),
target_fixture='basket',
converters=CONVERTERS)
def basket(initial):
return CucumberBasket(initial_count=initial)
@when(
parsers.parse('"{some}" cucumbers are added to the basket'),
converters=CONVERTERS)
def add_cucumbers(basket, some):
basket.add(some)
@when(
parsers.parse('"{some}" cucumbers are removed from the basket'),
converters=CONVERTERS)
def remove_cucumbers(basket, some):
basket.remove(some)
@then(
parsers.parse('the basket contains "{total}" cucumbers'),
converters=CONVERTERS)
def basket_has_total(basket, total):
assert basket.count == total
So now that our step definition functions are ready, let's rerun this Feature File.
If you notice, one of these scenarios is a Scenario Outline while I've left the other one as a plain old Scenario.
# cucumbers.feature
Feature: Cucumber Basket
As a gardener,
I want to carry cucumbers in a basket,
So that I don't drop them all.
Scenario Outline: Add cucumbers to a basket
Given the basket has "<initial>" cucumbers
When "<some>" cucumbers are added to the basket
Then the basket contains "<total>" cucumbers
Examples: Amounts
| initial | some | total |
| 2 | 4 | 6 |
| 0 | 3 | 3 |
| 5 | 5 | 10 |
Scenario: Remove cucumbers from a basket
Given the basket has "8" cucumbers
When "3" cucumbers are removed from the basket
Then the basket contains "5" cucumbers
That's okay though. All Scenarios and Scenario Outlines can be run together.
So, let's take a look.
And, boom! Everything's passing.

As you'll see, there were 4 tests that passed. Why 4? 1 for each row in our Examples table as well as the 1 Scenario for removing the cucumbers.
Now, if you're already familiar with the pytest framework, you might be thinking that Examples tables and Scenario Outline are very similar to pytest parameters.
And you know what? You'd be right.
Pytest parameters are just another way that you can provide input combinations to the exact same test function so that you can run the same procedure and expect different results.
In fact, with pytest-bdd, there's a way that you can remove the Examples table entirely from the Gherkin Feature File and put it directly into the Step Definition Module using this exact same decorator, pytest.mark.parametrize.
Let's see how it's done.
So back to our Step Definition Module. I've made some updates.
If you'll notice, I commented out the scenarios function and added a Scenario test case directly. The scenario test case I've chosen is from the Feature File we've been looking at for the “Add cucumbers to a basket” scenario.
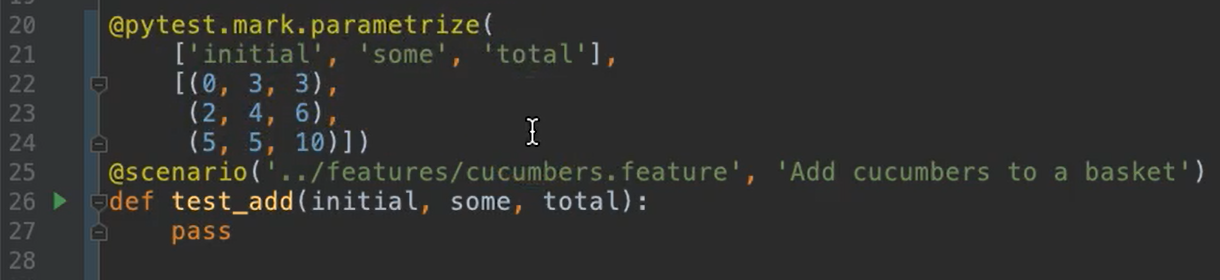
I've also added this @pytest.mark.parametrize decorator.
The first argument is a list of all of the substitution variable names from the Scenario Outline.
And the second argument is a list of tuples that have all the different input combinations in line with the variables.
You'll also notice that my test function declares those and the reason why you need them, even though the method does nothing but
pass, or no-op, is thatpytestitself requires that for parametrized functions.
In order to do this, I've also had to add import pytest [at the top] so I can get the decorator itself.
I'll also need to update my Feature File. As we see here, it has the Examples table. I'll need to remove that.

Looks a little weird now, doesn't it? But that's okay.
Let's give her a test to run.
And as we can see, the test passed.
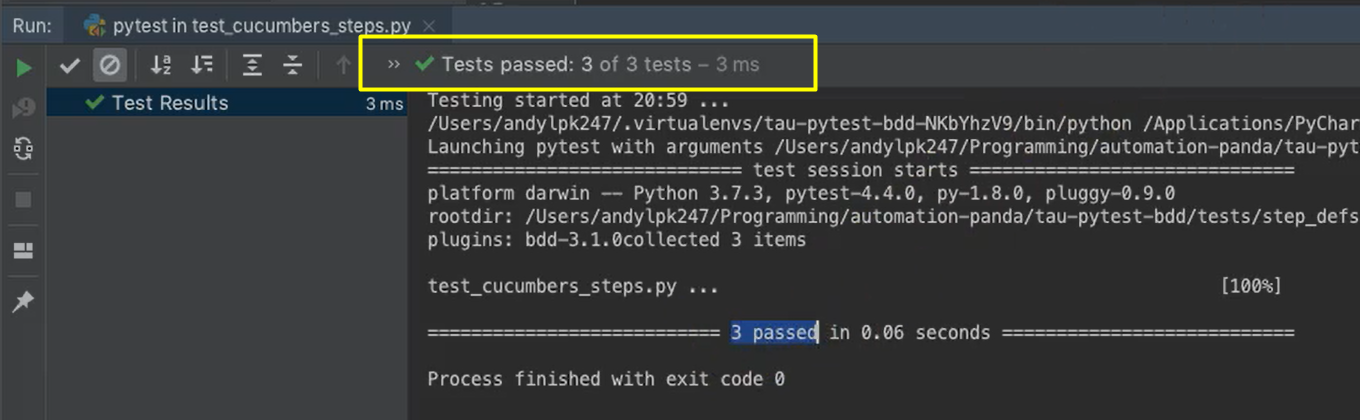
Now you might be thinking, "Hold on. Shouldn't we have 4 tests?" — because the Scenario Outline should account for 3, and the Scenario should account for 1.
This here is one of the limitations of using the pytest parametrization in the Python code.
If I go back to my test module, since I only declared the “Add cucumbers to a basket” Scenario to be a test and I commented out the whole scenarios function, then that “Remove” Scenario was not included with my test run.
Parametrized Decorator
The pytest parametrized decorator [pytest.mark.parametrize] cannot be applied using the convenient scenarios function. It must be applied individually using directly decorated test functions.
If I wanted to run that “Remove” scenario, I would need to add another test function here with a scenario decorator for it, which is less convenient.
Also, personally, whenever I look at a Scenario Outline in the Gherkin, I sort of expect to see the Examples table here, and it looks a little odd to me that it's missing. That breaks that whole notion of specification by example, which is central to behavior-driven development.
So, be cautioned if you want to use Python's parametrization rather than Gherkin's parametrization.
For that very reason, I prefer to do my parametrization in the Gherkin rather than in the Python with the pytest fixture. So, in my example code online, you'll see this version.
Resources
- GitHub Repo – Chapter 5
- Pytest-BDD Documentation
- pytest Official Site
- Automation Panda - Python Testing 101: pytest
- Automation Panda - Python Testing 101: pytest-bdd
