

Transcripted Summary
In this chapter, we'll learn about data management.
What are the options that Playwright offers to make that possible?
First, we'll see .env files and how to interact with them.
Then, we'll see how JSON files work and some options on how to architect them.
Next, we'll learn how to connect to an API for data management.
After that, how to mock some HTTPS calls and intercept those.
Lastly, how to use CSV files. I hope you have fun.
# Data management via .env files
One very common way to manage data in our application is via an .env file.
These are files that are stored locally, on our machines or on the server or in the CI, and it's very common for sensitive data.
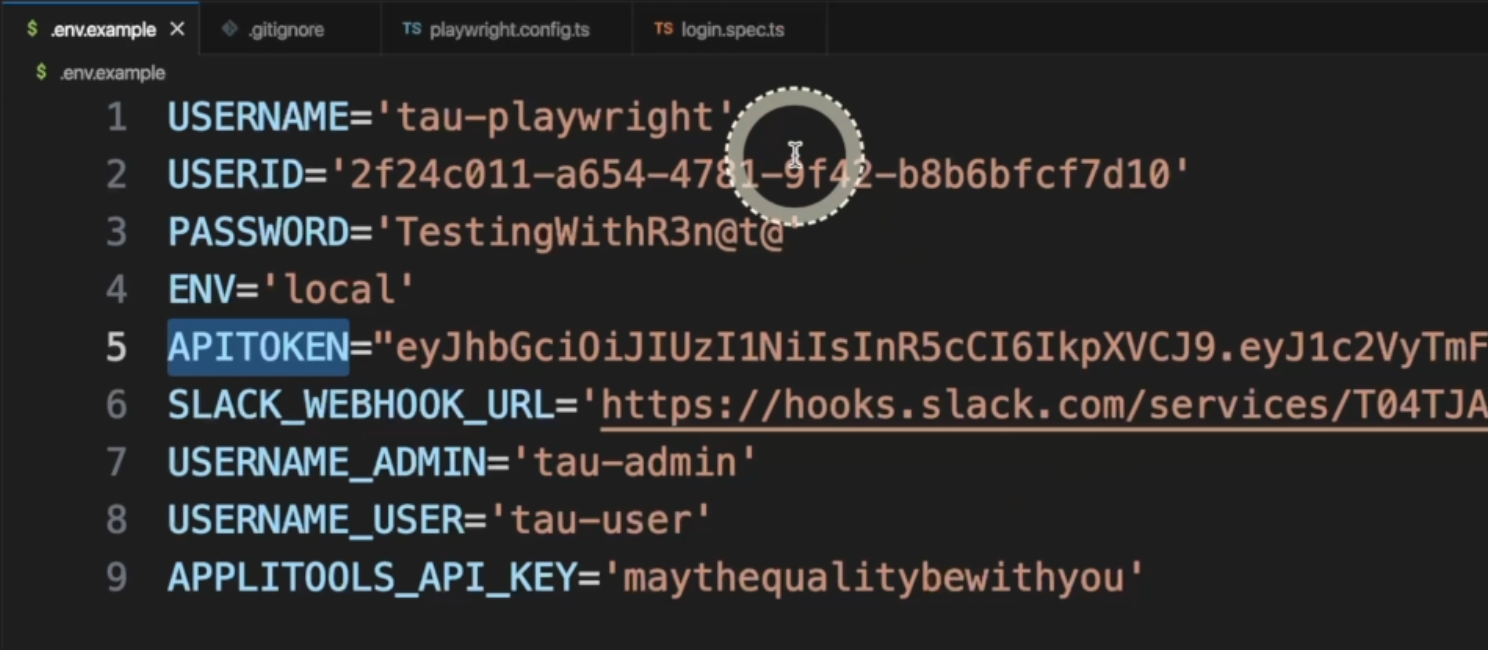
There you have usernames, user IDs, passwords, tokens, etc - data that cannot be shared with the external world.
Usually, these files are present in the .gitignore file, so if you have them locally, they won't be pushed to the repository.

You can define the use of them inside the playwright.config.ts file.
Here on line 4, you can see that we have a require('dotenv').config().
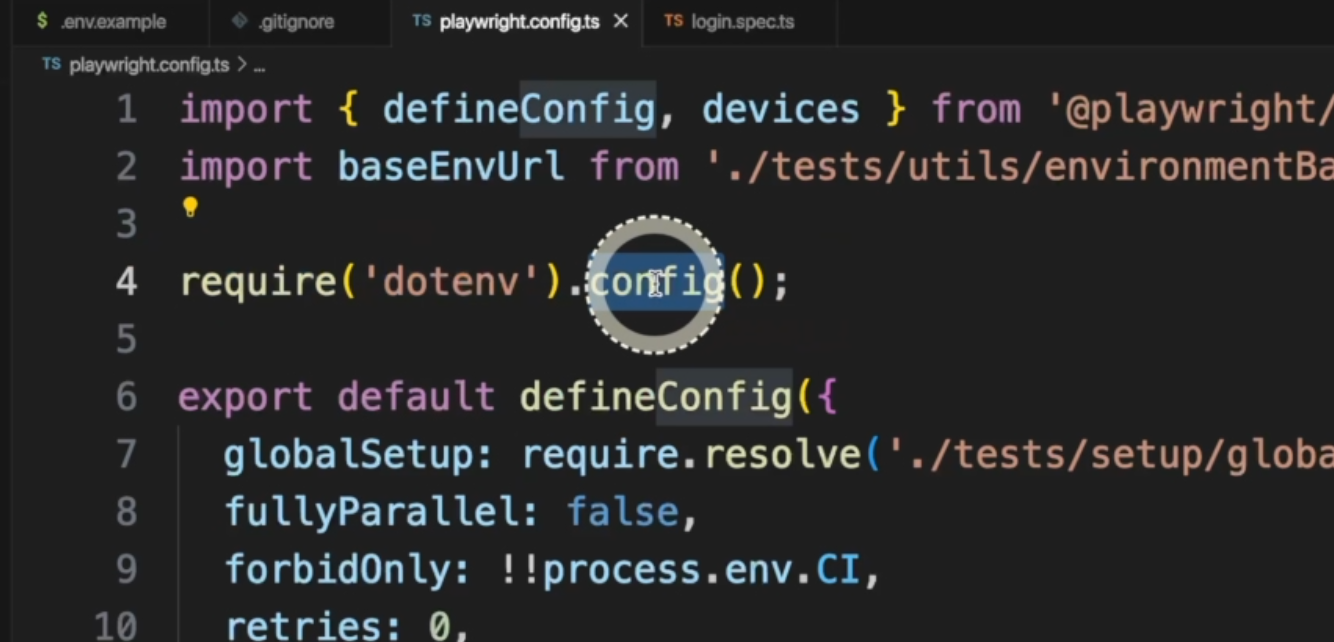
We need to install this, and in our package.json you will see that's there as well.
The way to use it across the application is via process.env.
You use process.env and then the name of your variable - for example, USERNAME or PASSWORD, and then store it in a common variable.

You can also use it everywhere else in the code.
For example, here for the baseURL, we are using a ternary and we get the process.env.ENV variable.
Back to the test file, it's common to use the exclamation mark so TypeScript knows that this variable will be filled before the test execution.
If you remove that, the compiler may complain about it.
We'll see more about pipelines in chapter 6, but for example, inside the playwright.yml file that will be used in your CI, you need to define if you're going to use secrets or vars.
This is how GitHub works and GitLab has something similar to that as well.
In GitHub, for example, inside your report you can go to Settings, scroll the left menu and find "Secrets and variables".
Click "Actions" and you'll find a "Secrets" tab and a "Variables" tab.
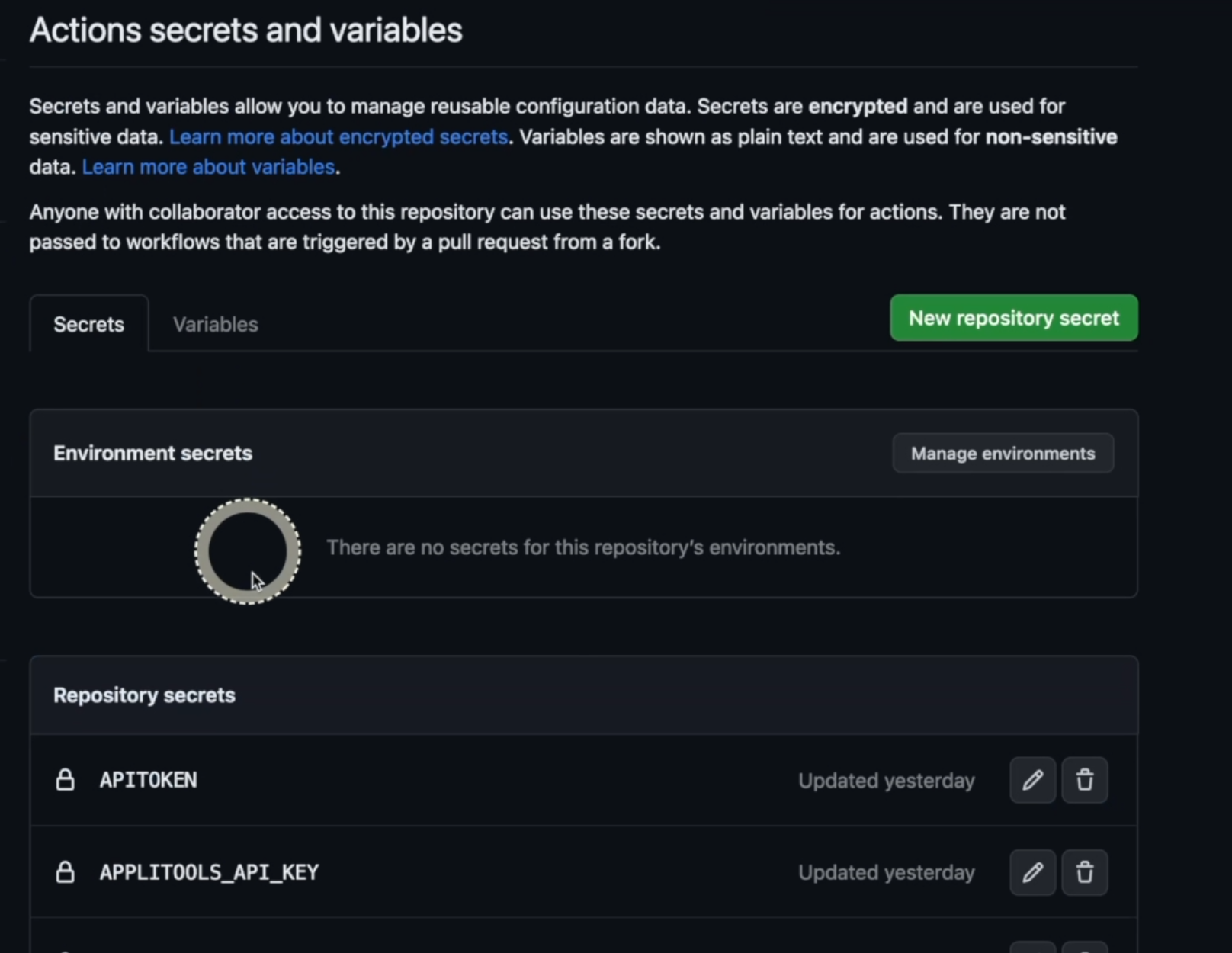
For Secrets, you can click on "New repository secret" and add your name and secret, or go back and go to Variables and do the same.
The difference between both is that secrets won't be logged - it'll be masked - and variables will be logged.
For example, if you are using an environment variable ENV, it's okay to have it exposed here because it's okay to know the value.
But in the secrets, like APITOKEN, you don't want to expose that to anyone, so it will mask it and keep it as a secret.
# Data management via JSON files
Another common way to use data in our application is via JSON format.
Here, we can see a group of data and values, and it can be an object as well.
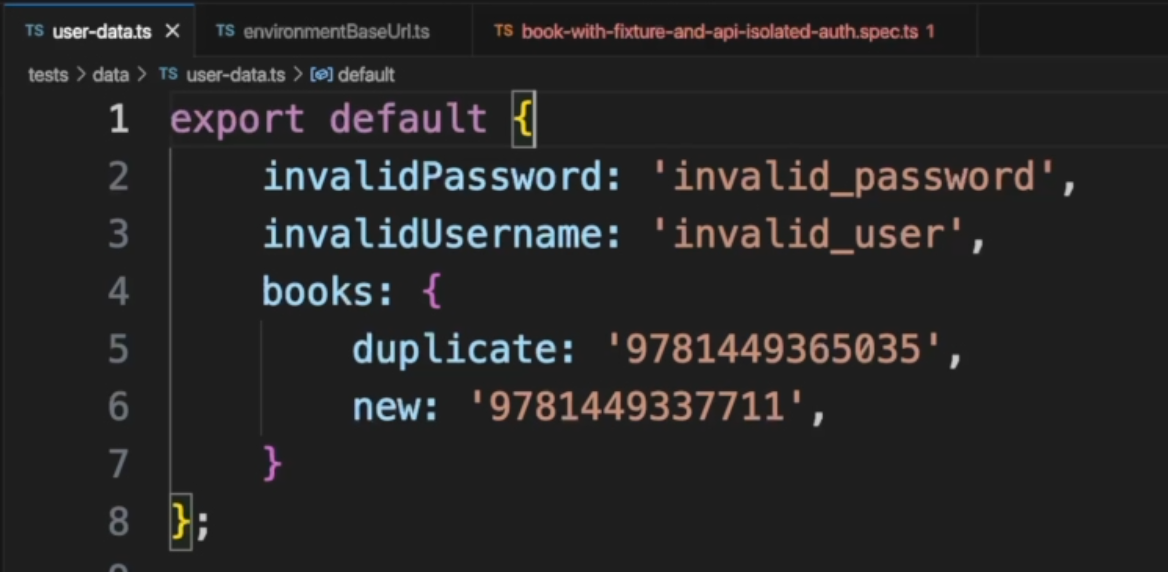
Another example is here where we have environments and values for each environment.
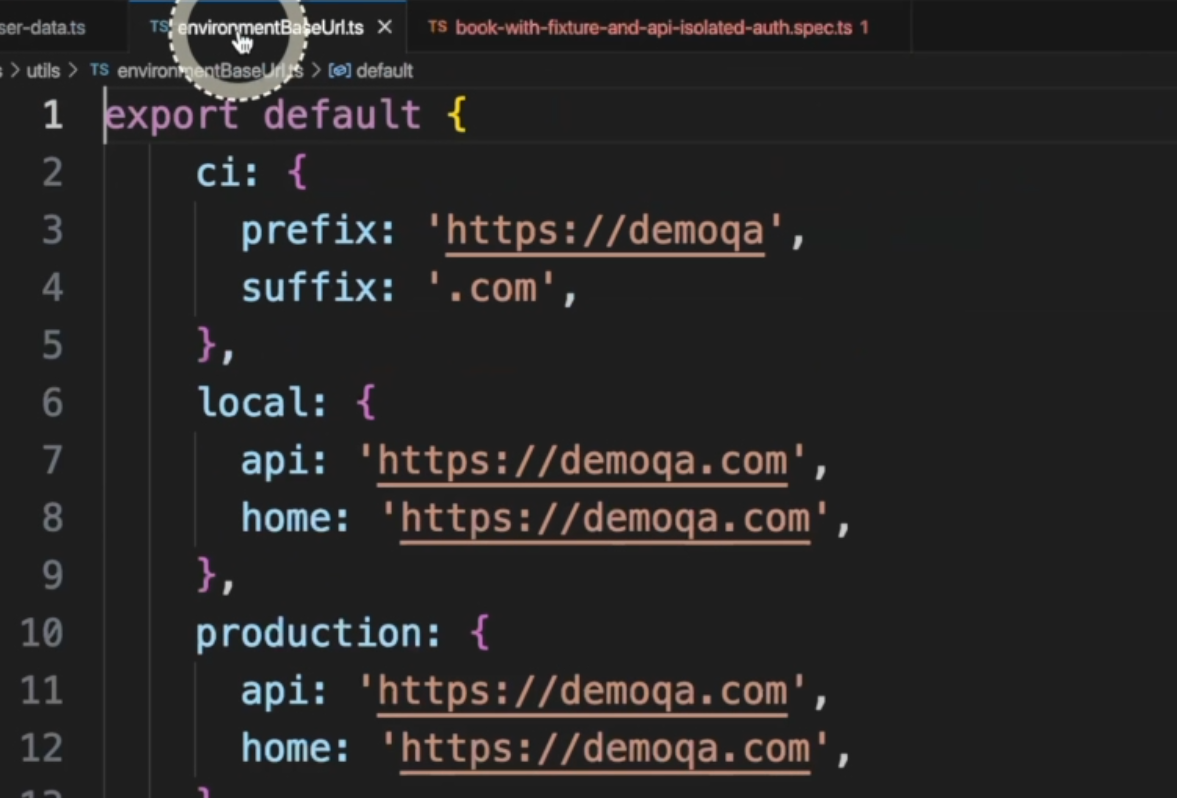
An example of this can be found inside the book-with-fixture-and-api-isolated-auth.spec.ts file.
Here we are importing userData and baseAPIUrl.
We can see on line 24 that baseAPIUrl can be used by env - so combined values.
If, for example, it's "staging" or "local", it will get the data based on this information here, which is very cool.
Then, we'll find the api URL.
For the userData, we can see here on line 42 that we have userData.books.duplicate.
Inside the file, it will get books, duplicate, and get this value.
# Data management via API requests
A third and very common way to use data is via API requests.
Here, in the book-with-fixture-and-api-isolated-auth.spec.ts file, we have deleteAllBooksByUser and addBookToCollection.
If we go to these methods, we can see that they're making a call to the application - to the API - and then getting a response.
Manipulating data is straight to the application via the API.
Another way of using it is via the database directly.
You could create a connection and then manipulate that data directly in there.
However, it is more often recommended to use the API because the API usually has rules that will prevent the data from being inconsistent in the database.
# Data management via intercepting an HTTPS request
The fourth example we are going to see here is via intercepting an HTTPS request in the browser, and eventually mocking a response.
This scenario is very useful when you are testing third parties where you cannot change the response.
For example, if I need to make a call to PayPal and test the scenario where PayPal is down, then you can do the call and by understanding the response, you can mock the response coming from the server, and then make it fail and test your application normally.
Of course you can do that in case you don't have the access to change the data in the database - you can force data into the response and then load your UI and proceed with your tests.
This approach needs to be used very carefully, because if you're mocking the response from the API, you need to make sure your integration is really working with the API.
That's because this will isolate the UI and won't validate all the scenarios on the API level.
To see how that works in Playwright, let's take a look at the profile-api-interception.spec.ts file.
Here we have the imports, here we are creating the page object in a traditional way with the new ProfilePage, and inside our test we have this method, watchAPICallAndMockResponse.
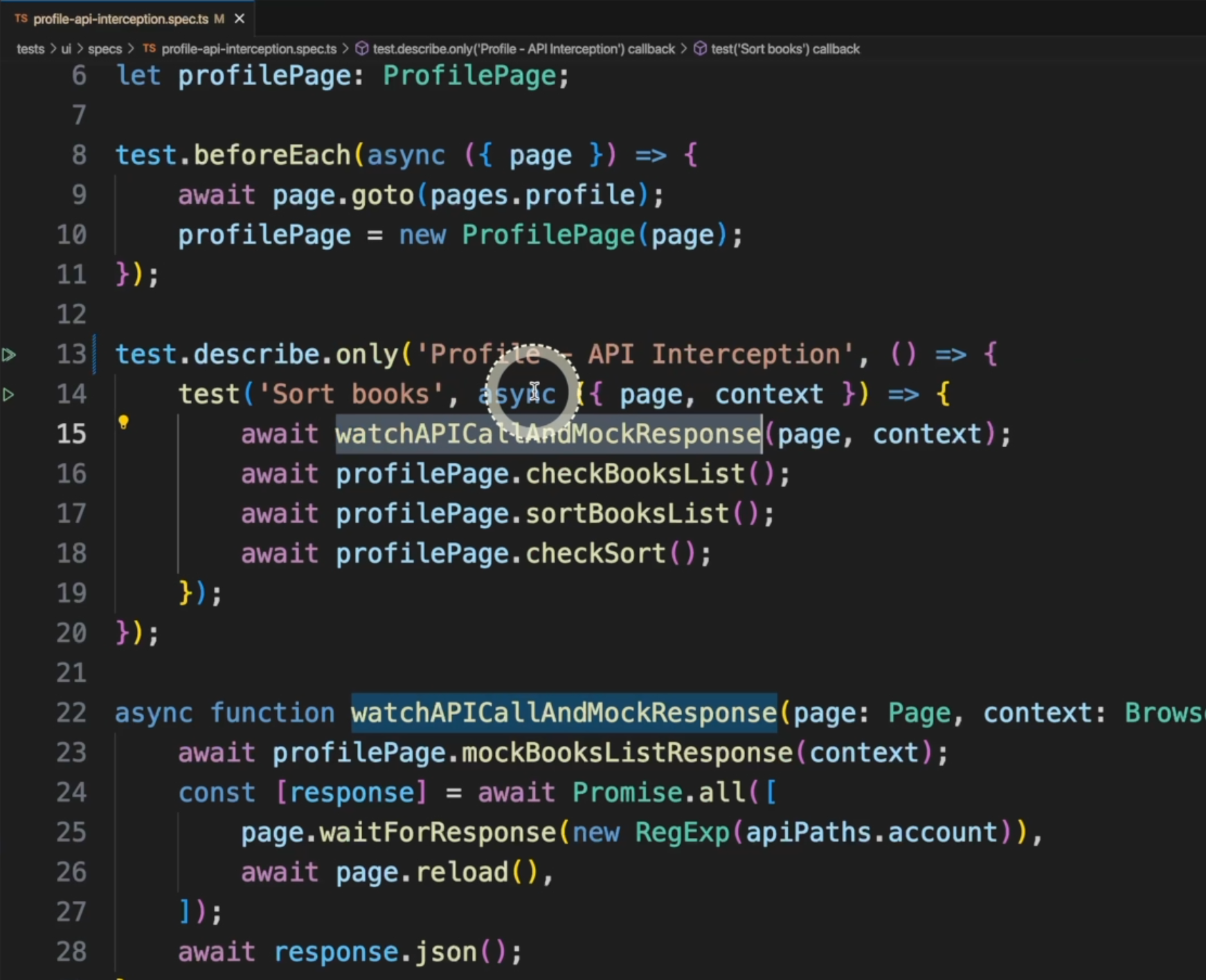
This is a regular test - it doesn't have any fixtures - so this is the first method that will be executed when this test starts.
Going to the method, we see profilePage.mockBooksListResponse, and if we go there, we have the context that is being passed in as a parameter.
async mockBooksListResponse(context: BrowserContext) {
await context.route(this.booksCollectionRequestRegExp, (route) => route.fulfill({
body: JSON.stringify({...(bookListData)})
}));
}
Here we see a command - context.route(this.booksCollectionRequestRegExp)- which is a RegExp using the apiPaths.account path, which is this one here - 'Account/V1/User'.
This corresponds to the API call that will get the list of books for this user.
We pass route in here and we create an arrow function with root.fulfill(), meaning that as soon as this endpoint is called, we will intercept it and we will replace the content by using this new body with this data right here - the bookListData.
If we go here, no matter what the request response to us is, we are going to force this data into this request.
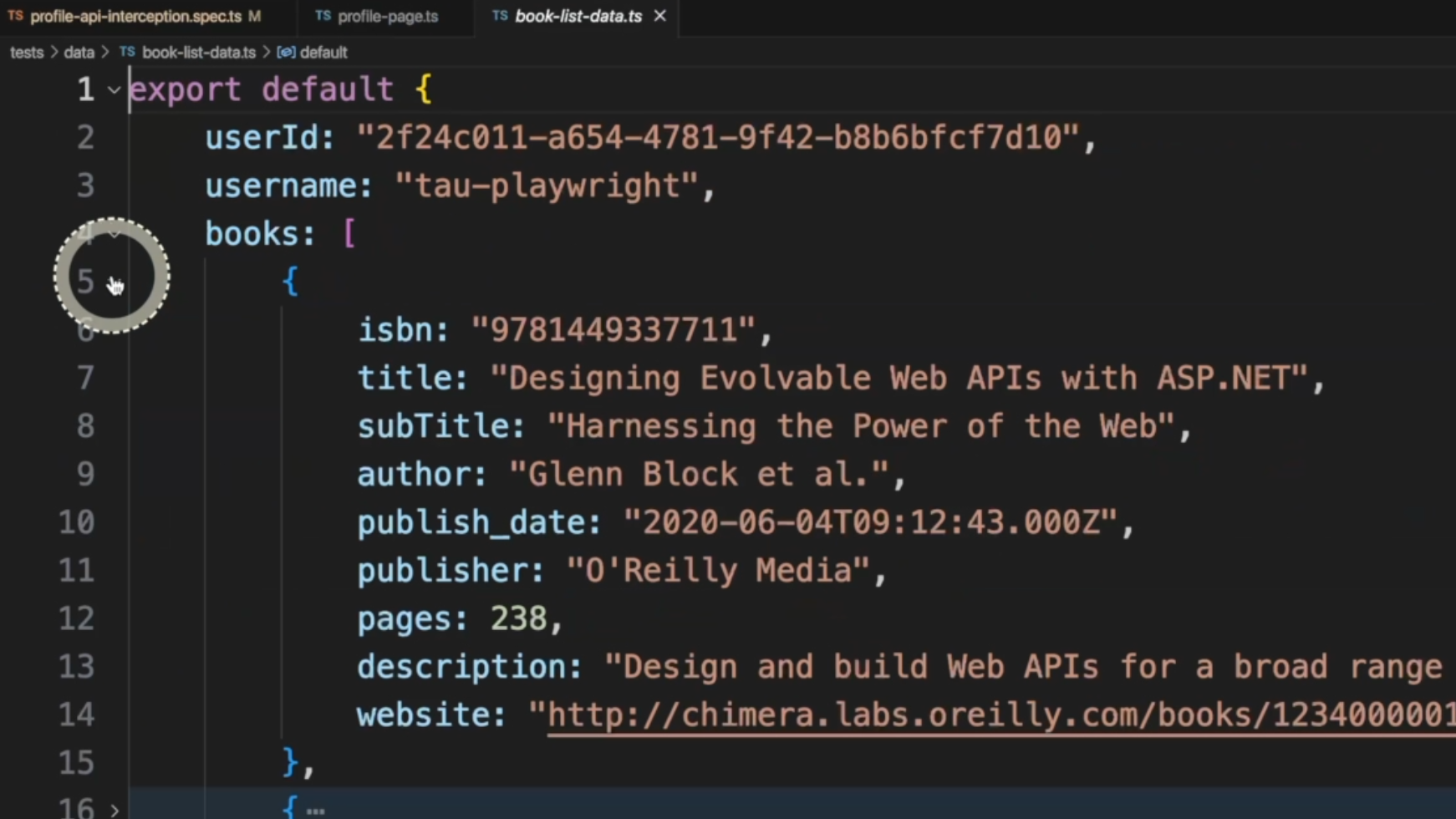
This mockBooksListResponse method will return to this profilePage and it'll reload the page with that new content.
We can see in the browser how that works.
For this user "tau-playwright", we see that we don't have any books right now.
We can refresh the page and nothing will come up.
When I execute the test, I can come here in the report traces and see that as soon as we get the response, you can see that two books are loaded on the page and the test is being executed.
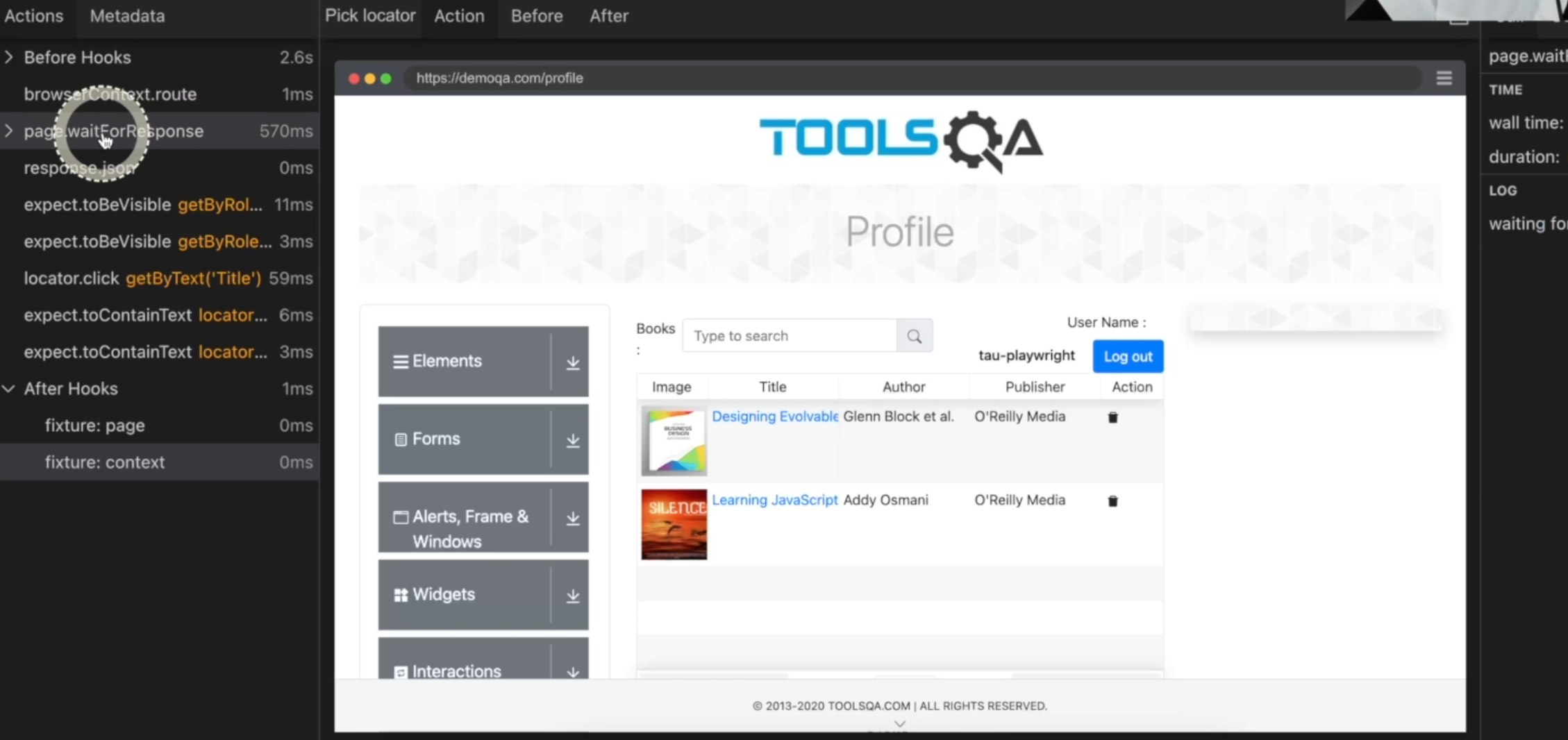
This is the interception of the request made to your application.
Back to our test, after watching the API call and mocking the response, we do a checkBooksList that will make sure both books are present on the page with toBeVisible.
Next, we'll call sortBooksList that will click on the header twice.
Lastly, it will check if the books' order has changed.
See here that gridRow1 contains the book in position 1 instead of 0, and gridRow2 contains the book in position 0.
Back to our report, we can see what happened.
First, it loads the page, and then checks the first element is this "Designing Evolvable" book.

We can see it here.
Next, it checks the second link to see if it's "Learning JavaScript".
The other command will click on the "Title" header to sort the books.
At this time you can see that the order changed.
"Learning" became the first and "Designing" became the second.
So if you click here, you see that "Designing" is the first, and if you click here, you see that "Learning" is the first.
If you go back to our real application, that data is not there.
This is just an HTTPS interception. We are forcing the data into the API response.
Once all these commands are executed, our tests will pass successfully.
# Data management via CSV file
Another option that is very commonly used is via CSV files.
You can create a CSV file.
In this example, we are creating an input.csv file.

This is the format that it should follow.
Here, you have each column, and here is the data.
In your spec file, or any other file inside your test suite, you can do an import fs, which is a file system function, and transform, read, the CSV file into an object.
With that, you can iterate over your object and use every single value of the file.
In this example, we are console logging every record, every line of the CSV file.
Woo hoo! Congratulations. This is the end of chapter 4.
I'm here to wish you good luck with the quiz below and to remind you to take a look at the extra exercises and links in the Resources section. I'll see you in the next chapter. Happy testing.
