

Transcripted Summary
A web element is a thing on a webpage. In fact, everything on a webpage is an element - like buttons, labels and text inputs.

Users and tests alike interact with web pages through these elements.
Most humans don't think twice about interacting with elements. They visually see what they want and then they tap or click or type. However, test automation requires more nuance.
Automated interactions take 3 steps:
First, wait for the target element to appear.
Second, get an object representing the target element.
And third, send commands to the elements.
Automation uses locators to find elements on a page.
Locators are simple query strings for finding elements. They will return all elements that match their query.
Selenium WebDriver supports many types of locators — IDs, names, class names, CSS selectors, XPaths, link text, partial link text and tag name.
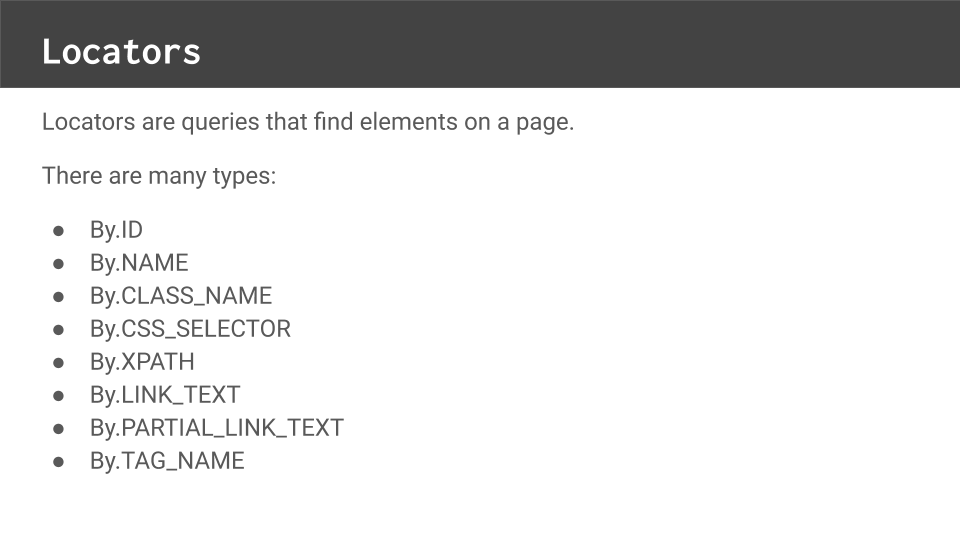
Some locators like IDs and class names are simple, while others like XPath are more complex.
I recommend using the simplest locator possible that uniquely identifies the target element or elements.
Let's look at some locator examples together.
Here's a simple button element.
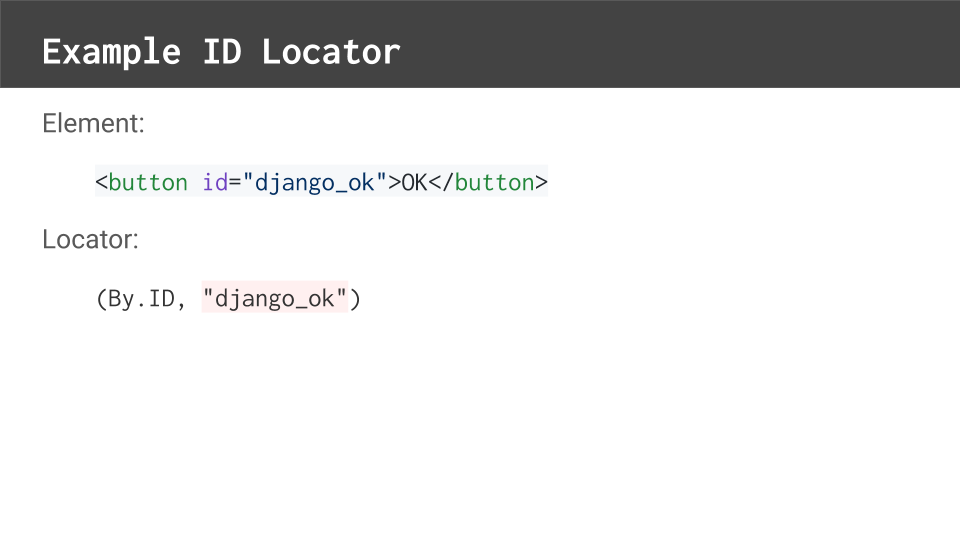
Notice how it has an id field. That's awesome, because id fields are usually the simplest locator types because their query is just the identifier value.
By convention, IDs should be unique for HTML elements, so using an id should uniquely locate the target element on the page.
In Python, I like to write my locators as tuples.
The first part is the locator type which uses Selenium WebDriver's
Byclass.The second part is the query, which in this case, is the ID value.
Unfortunately, not every element has an id.
Let's look at a CSS selector example together.
This button element has a class instead of an id.
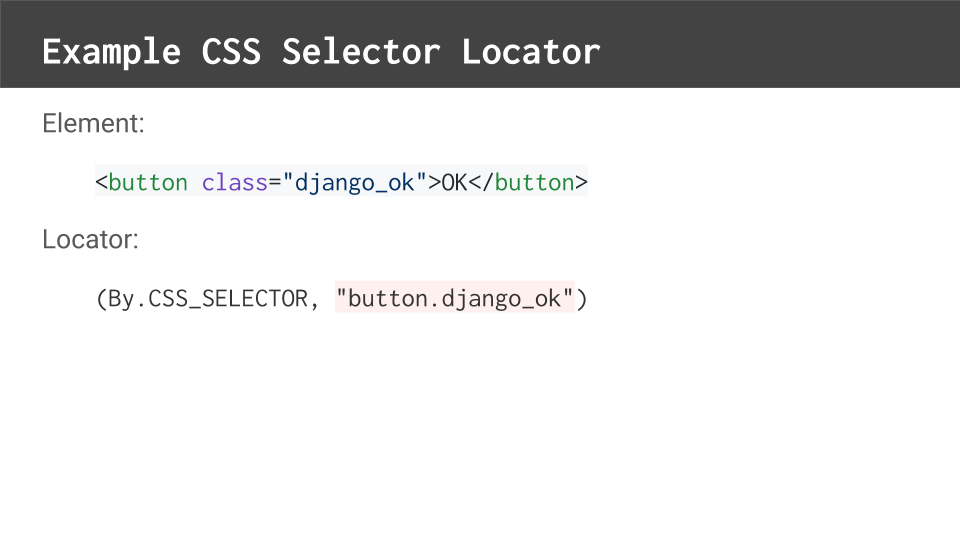
We could use a CSS selector to uniquely identify it. CSS selectors work the same in Selenium WebDriver as they do in CSS pages for web front-ends.
Here, we could use “button.django_ok” to select the button element with the “django_ok” class.
Finally, let's look at a tougher example.
Sometimes elements don't have any helpful anchors; in those cases, we often need to rely upon XPath.
XPaths can uniquely identify any element or elements on a page.
This button element has no attribute values whatsoever.
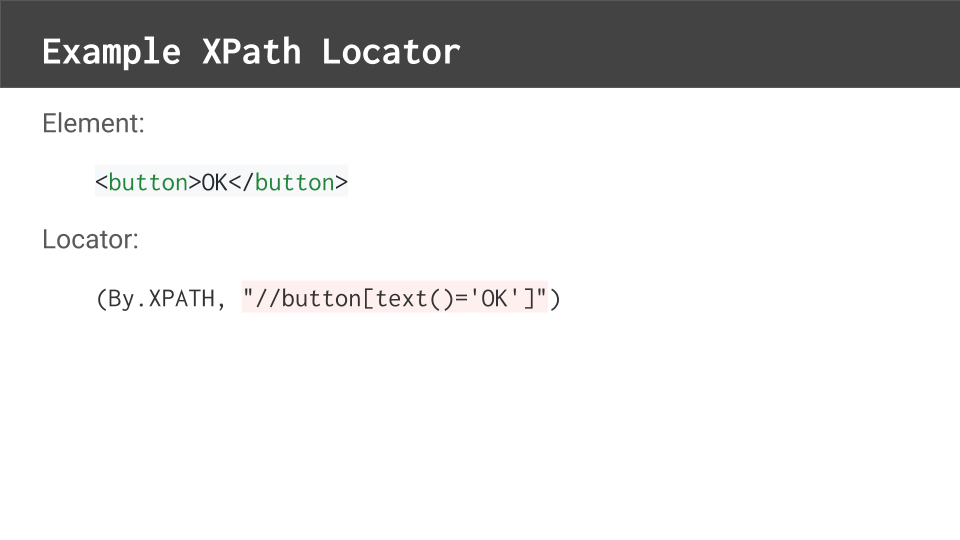
To locate it, we could use an XPath that checks the button’s text value.
XPath syntax might be a bit confusing at first, but it's fairly straightforward.
The leading double forward slash means find the element anywhere in the page under the root elements.
The word “button” means to find an element with the button tag.
The square brackets denote a condition for the element to meet — its text value must equal “OK”.
XPaths can be much more complex than our simple example here. They can check parent-child relationships and other more sophisticated conditions.
I strongly recommend learning advanced XPaths in texts as you learn more about web UI test automation.
Our test case interacts with 3 elements.
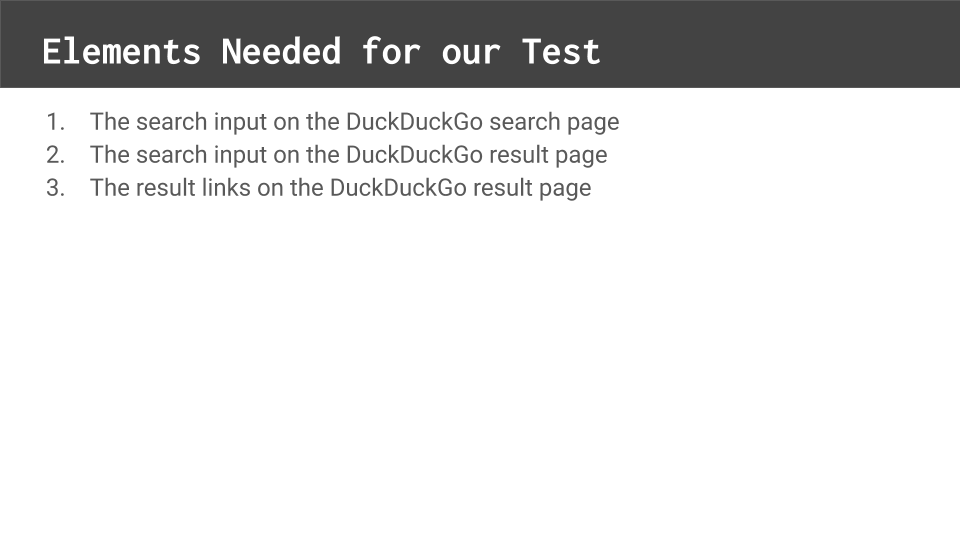
The search input on the search page, the search input on the result page, and the result links on the result page. That means we will need to write locators for each of these 3 elements.
Note that the third element is actually not 1 element, but rather a list of related elements.
You might also be wondering, what about the page title?
The page title is actually not a web element but an attribute of the page. We will get that value using a different kind of WebDriver call that we'll see in the next chapter.
Now that we know how locators work, let's figure out how to get locators for target elements that we need for our test case.
Let's start with the search input element from the DuckDuckGo search page.
I've already loaded the page here and the target element I want is this text field, one where we enter our search phrases.
Personally, I like to use Chrome with the developer tools. To access it, right click on the element and select Inspect. When you do that, you'll see the dev tools window open and it will show the HTML source code for the page.
My text field input for the search input is right here.
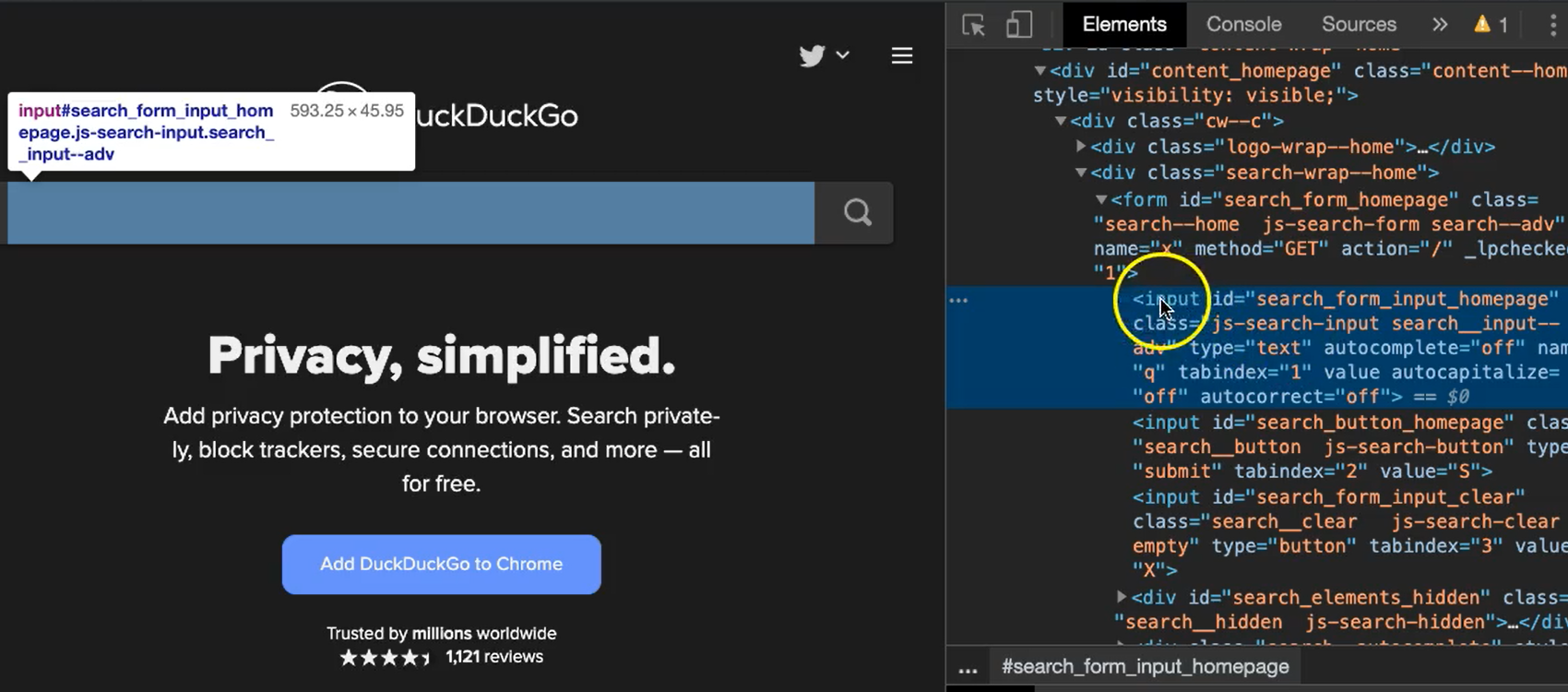
If I look at the HTML code, I can see right away that it's an input element that has an id of "search_form_input_homepage".
I can quickly check to make sure if that is a unique id by using a quick CSS selector and sure enough it only found one on the page. So, for this element, I'm going to use an id locator with this as my identifier.
Let's add that locator to our page object code.
Here I have the code open in Visual Studio Code and I've got my search page object file open.
Here, under the class, I've added my search input locator.
SEARCH_INPUT = (By.ID, 'search_form_input_homepage')
As you can see, it's a tuple, By.ID, with that identifier value search form input homepage.
I like to add my locators as class variables because we really only need 1 copy or instance of this tuple for my class. All objects are going to use the same one.
The next chapter we'll see how we use this locator in these methods.
I've also created locators for my two result page elements.
RESULT_LINKS = (By.CSS_SELECTOR, 'a.result__a')
SEARCH_INPUT = (By.ID, 'search_form_input')
For the RESULT_LINKS I used By.CSS_SELECTOR and for the SEARCH_INPUT I used a By.ID selector.
I encourage you to try to figure these out on your own by opening Chrome dev tools. See if you can target the element and come up with these locators or even similar locators.
This chapter is just a light introduction to web element locators.
If you want to get serious about web UI test automation, then you'll need to learn more advanced techniques for locators. I strongly recommend taking another test automation university course called Web Element Locator Strategies.
That course digs deep into each locator type with advanced examples. Plus, if you take that course, you'll get more TAU points.
There's another TAU course that you might find interesting as well, AI for Element Selection. That course shows how to use AI techniques to avoid the pain of fragile locators. Check it out if you get the chance.
