

Transcripted Summary
Let's take a look at some guidance around testing from the inside.
These are tips and tricks that every tester and developer should know before they put hands to keyboard doing any unit, component or lower level integration testing. And what I've done, I've packaged these up as a cheat sheet that's included in your course materials, so that as you start to put these things into practice, you'll have this cheat sheet as a quick reference guide.
Let's get started.
Know What You Are Testing
The first thing that we've seen, time and time again, is that you need to know what you're testing.
Remember that there's a big picture, a grand scheme of things, where requirements need to be fulfilled. And at this lower level, you need to act as a consumer of the component that you're testing and validate that it fulfills its requirements.
And there's some questions that can guide you and help you understand exactly how to do that.
The first question is, what is the purpose of the component that you're testing and each of its routines? You have to start thinking about, as part of this subsystem, what is the function of this particular class? And each method, each operation, each routine that’s called, must have some purpose. It's providing some service to some client that is consuming it.
And so that brings us to the next heuristic or question, which is, what components are consumers of that component? That helps you to also get an understanding of, what are the expectations of the other classes or components that are using the component you're testing?
And last but not least, you need to ask a very big design question. That question is around whether or not the class is designed by contract — meaning that there's a mutual agreement between the sender and the receiver, between that client and that server or component under test — or does it follow, let's call it defensive design or defensive programming, where there's a lack of trust between sender and receiver?
Now the reason this is important is because if there's a mutual agreement between sender and receiver on the different types of inputs that can be accepted, if anyone violates that contract it's not on the responsibility of that component under test to defend against bad inputs. It generally means that the defensive aspect of it is usually contained in some other class and it does not apply to this class.
And we'll see more of that once we get into the hands-on portion.
When it's designed defensively, since there's a lack of trust, you need to be a lot more robustness testing.
Test Results Not Implementation
Secondly, you want to make sure that you're testing component behaviors and results and not the internal implementation of that component.

This will ensure that your tests only fail when there's an actual defect and not just due to internal changes to the component. That public interface really represents the set of operations and services that is being fulfilled by that particular component. It shouldn't matter what internal data structures or algorithms you use to implement that public interface. Those internal details are things that developers may want to change, but as long as that public interface is stable you don't have to worry about refactoring tests when the internal details changes.
This improves the test readability — you can now refactor without even touching the test. Your tests now become a specification because they're based on that interface that other clients are going to use and they're actually going to say, "This is the expected behavior of this interface." If you test against those internal details, you're going to increase the fragility of the test. They're going to be very brittle and fail and be very sensitive to small tweaks in the code, or any type of changes in data structures. This makes refactoring hard and can slow down development.
But it's important to note that there's usually a tension here between the encapsulation of these internal details to help with refactoring and testability. And one of the problems that can occur is if there's a lot of complex logic hidden away in private routines. The recommendation here is to really refactor the code and to revisit that public interface. Make sure that we've designed it in such a way that all of the component behaviors that might be needed by the external classes are actually accessible through a more granular public interface.
One thing that we don't want to just do is to just change those private methods to public. That's not what I'm saying here. I'm saying here that we need to take a step back and look at the behaviors that maybe need to be provided as services so that we have simpler logic, but maybe more methods.

Test One Thing at a Time
Thirdly, you want to test one thing at a time. Each test should have a clear, concise, singular objective, and this will make tests easier to debug. Because once a test fails, you know that there's only one thing that you were actually looking at. And so now you don't have to try to figure out, "Well which behavior is it?"
Make Tests Readable and Understandable
You want to make tests readable and understandable. Your test code should be held to the same standard as your production code. It should be well documented. You name test methods using some description of that scenario and the expectations. This is so that once a test fails, you can really pinpoint what aspect of the functionality went wrong. And even just jump straight to looking at that portion of the code that corresponded to that behavior.
Fluent interfaces actually help to promote making test code self-documented. And so, once we start to look at that you'll see that you can just look at the test code and you can understand exactly what it's doing.
Make Tests Deterministic
You also want to make sure that your tests are deterministic. A test should pass all the time; or fail all the time if nothing in the application has changed. And so, you want to avoid things like you using conditional logic within tests — if/then or try/catch or loops. A lot of the control structures that we looked at are good things when you're doing structured programing, but it's not so good when you're writing automated tests. And this is because you want automated tests to be very simple, very straight line, very sequential, so that you can be sure exactly what failed, when it fails.
You also want to avoid using explicit waits, like sleeps. Sleeps are dangerous because you're telling the test that you want it to pause for a specified moment in time and this specified time period. And what will usually happen is once you try to move those tests into different environments where there's different processing times and different memory requirements, those explicit waits may or may not be long enough, and it causes your tests to be very brittle.
Make Tests Independent and Self-Sufficient
You want to make each test independent and self-sufficient.
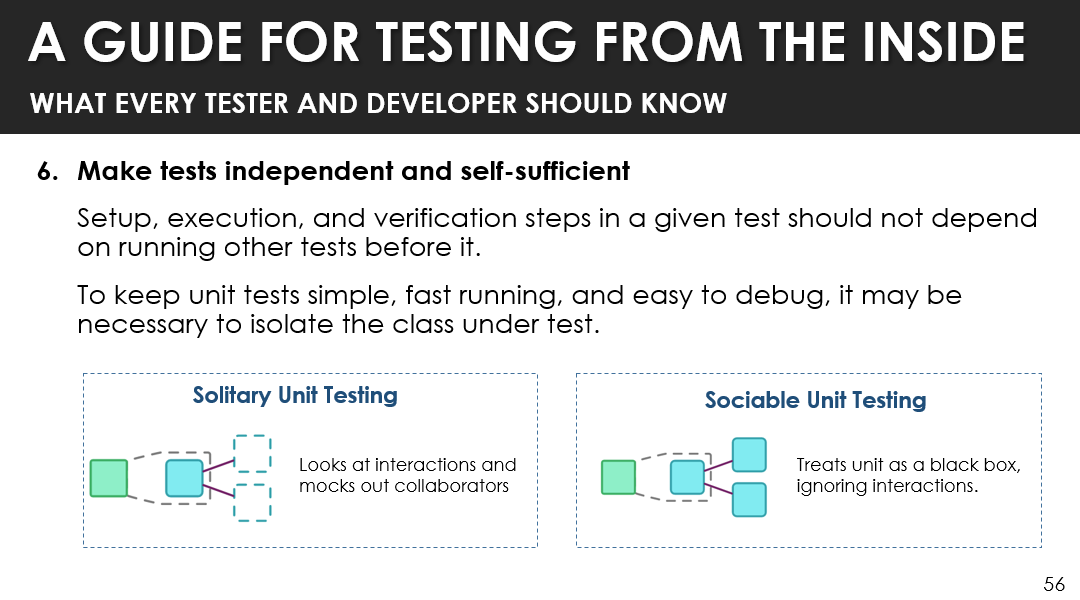
This means that your setup, execution and verification of a given test should not depend on other tests that are running before it. This helps you to keep those component and unit level tests simple, fast running, easy to debug and it might be necessary to actually isolate the component or class under test to do so.
And there's two different techniques for doing that.
The first one is called solitary unit testing, in which you can actually mock out those dependencies or those collaborators.
The other way that you can achieve that is by doing what's called sociable unit testing. And here you don't mock out anything, but you're concern is really on that one class or that one component and you treat it as a black box and you ignore any interactions.
Let's take a look at mocking and some heuristics around that.
Mocking is really where you try to isolate those dependencies. And you might want to isolate those dependencies in certain situations and it's important to understand what situations are good and to avoid some common pitfalls.
The first thing is that you want to mock if you don't have some dependencies available, or maybe they're not implemented yet. This could be due to priority or different scheduling restrictions.
Sometimes you focus your concern within a subsystem or within a particular system. And so, you want to mock things sometimes if they stretch across those system boundaries so you can focus your testing first on just this portion of the system, and later on you can work on testing the integrations across systems.
Sometimes you have cases where it might be difficult to setup or reproduce some conditions. And in that case, you want to use mocks to do that type of simulation. For example, maybe you want to check that your software responds well even when the hard disk is full. And so, you want to simulate a disk full exception, rather than trying to actually populate and fill up the hard disk to get that condition for testing.
Mocking is also very useful when we're dealing with non-determinism. In other words, your application itself may be non-deterministic, where some functions and the calculation of some things are dependent on time, or random numbers, which are things that change. And so, to be able to force a deterministic result and get specific information of the system operating under those conditions during a test, we can use mocks to return specific times or specific numbers so that we can make sure that the behavior under those conditions is acceptable.
Mocking is also very useful when you have long running processes such as payroll or billing. If you're not concerned with the payroll or billing functions right now, but you need that data to be able to run a subsequent test, what you can do is mock that process or mock that response from those types of calls and get back always a specific result from the mock, and then base your test off that.
Caution
There's one big caution here when it comes to mocking. It's really not representative always, of the resulting system that's going to be shipped. And so sometimes you can mock behavior so much that you're actually not testing anything that's very realistic or representative of the end system. And so, you want to make sure that you use mocking with caution.
Repeat Yourself When Necessary
This next guideline is about writing test automation code and knowing that it's okay to repeat yourself when necessary.

You see, as a developer you're taught that writing the same code twice is bad because it can lead to a maintenance nightmare. In other words, everywhere that you write that code, every place that it's duplicated, if you need to change it, you need to revisit each of those instances to make that change. This is called the “do not repeat yourself” (DRY) principle. In testing it might be okay to violate that DRY principle, because in many cases it can make tests simpler and easier to read. And so here let's look at an example.
[Test]
public void MultiplyPositiveByNegativeProducesCorrectResult()
{
MultiplyTwoNumbersAndAssertTheCorrectValueAndThatOperationIsValid(-1, 3, -3, true);
}
[Test]
public void MultiplyTwoPositiveNumbersProducesCorrectResult()
{
MultiplyTwoNumbersAndAssertTheCorrectValueAndThatOperationIsValid(1, 3, 3, true);
}
In this example, we're trying to avoid duplication. We have two tests:
- One that multiplies a positive by a negative number and you're checking to make sure that it produces the correct result.
- And another test that multiplied two positive numbers and makes sure that that produces the correct result.
And what we're using here is a common private method, within this test class, that multiplies two numbers and then asserts the correct values of that operation and makes sure that that's valid. And so, we're passing parameters in there.
Now even though we can kind of read this particular private method, it's actually not clear what each step of this test is doing. And so, when we obscure the test like this, it actually becomes not a good thing because no longer is it very visible to the tester exactly what the behavior of this test method is doing.
And so, you have to ask yourself, is there a way that I can avoid duplicating test code without obscuring the test steps? And the answer is yes.

Many frameworks provide mechanisms for you to be able to supply sets of inputs and expected results to a test method, a very generic and re-usable test method. And each role of data values represents an instance of a test that is being passed into this particular function. And here you can see that the test steps are very clear.
You don't have to worry that you can't read exactly what's going on in this case with the calculator and the results.
And here you actually see an example of a fluid interface. Where you see it says, the results should be, and whatever the expected result is.
And here you see that you have formal parameters, right? This is your first number, your second number and what is expected.
And above it, each row represents a test case for supplying the first and the second number and the expected result.
And we can even give a description of this particular test scenario.
So here, we can use this construct to make sure that we can have re-use and we can still avoid that duplication, but we don't obscure the purpose of the test.
Measure Code Coverage but Focus on Test Coverage
Our last heuristic is all about measurement.

You want to measure code coverage, but you want to focus on test coverage.
In other words, we've seen in our examples that 100% code coverage is something that you can easily achieve. And we don't want you to be misled into thinking that 100% code coverage means that you have strong tests. You see, code coverage is more of a negative indicator. Low coverage indicates that your tests are weak, and you can use it as an opportunity to make tests better.
We don't want you to use code coverage as a goal. In other words, don't write tests simply to try to achieve 100% code coverage, because you'll likely stop when you hit 100%.
There's a wonderful paper that we've included as part of your course materials, that says,
Brian Marick Quote
"If a part of your suite is weak in a way that coverage can detect, it is likely also weak in a way that coverage can't detect."
And so, the focus here should be about making sure that you look at your test set, you look at what you're using, you apply testing techniques and testing methodologies. Because it's those techniques and those methodologies that allow you to build a very strong test set.
Good test coverage is achieved by executing routines and methods using a variety of values selected using those different testing techniques and methodologies. Three widely used techniques include boundary value analysis, equivalence partitioning and using domain analysis and domain testing.
So, this concludes the summary of our guidelines.
Remember, this is just an overview. What we need to do now is to get hands-on and put this stuff into practice. And what we'll be doing, as we do the hands-on, we'll revisit some of these guidelines to make sure that our tests are following good practices.
