

Transcripted Summary
In this chapter, we are going to understand how to work with XML.
Any automation framework that you create is probably incomplete without having the ability to deal with XML requests and responses.
You might need this if you are automating a SOAP-based service.
You might want to use XML as a data type to store your test data or work with certain pre-created test data.
Let's understand how we can actually work with XML in Python.
We are going to make use of lxml library, which is a very popular library with a very nice Python API.
To show you all how to work with lxml and XML as a data format, I've created a dummy flask service, which always returns a canned response for COVID cases on a daily basis, as well as at a region and a country basis.
This is going to be static data that's never going to change, so any assertion that we create is going to be very deterministic.
So to enable this service, you need to go to the people-api project and ensure that you are within the pip environment.
Once you're within the project and have already set up the pip environment with
pipenv shell
You can run the flask service by running:
python covid_tracker/covid_tracker.py

As you can see, this is serving our API on the localhost 3000 port, so this should work even if you are running the people-api in parallel on the port 5000.
I have this API already imported in Postman - if you are taking a look at the project, you will see that you also have this Postman collection and environment present there.
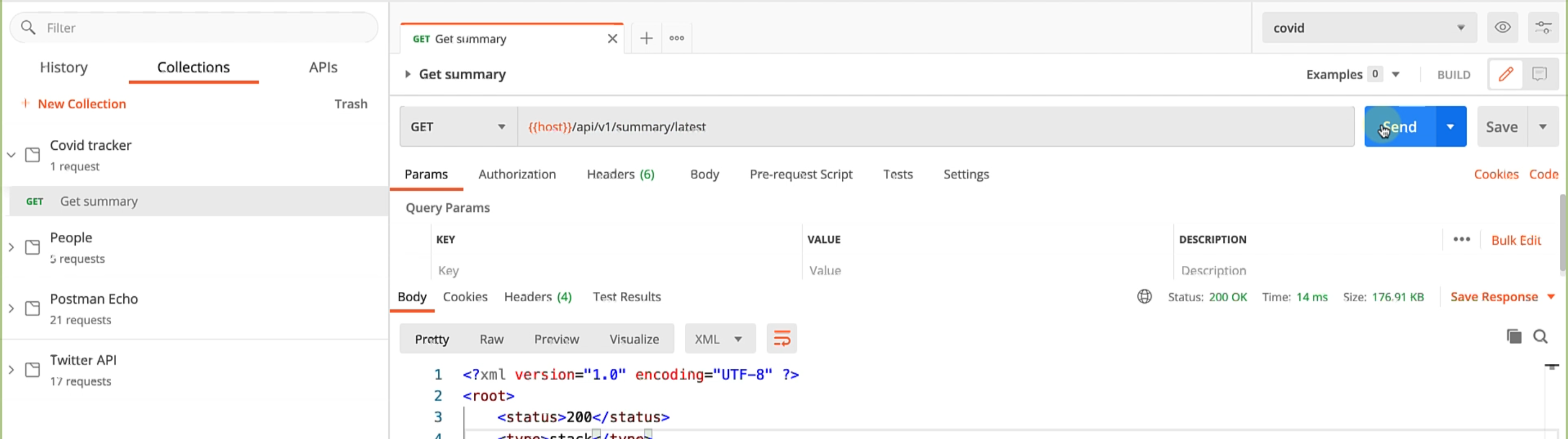
At the moment, this is a very simple GET API, where we are trying to get the latest summary for the day.
When you hit the API, you can see that it returns the COVID data for a given day, and it gives you a worldwide total summary of cases.
Also, it gives you the different regions and what is the breakup of cases there, so we'll work with this data set to show you how to work with lxml.
Back to our project - let's ensure that we are on the correct branch.
Let's checkout example/04_working_with_xml and I already have a couple of examples so I'll make sure I check out an earlier revision.
If you see the Pipfile, we now have lxml as a new module that is added, and I have already installed it.
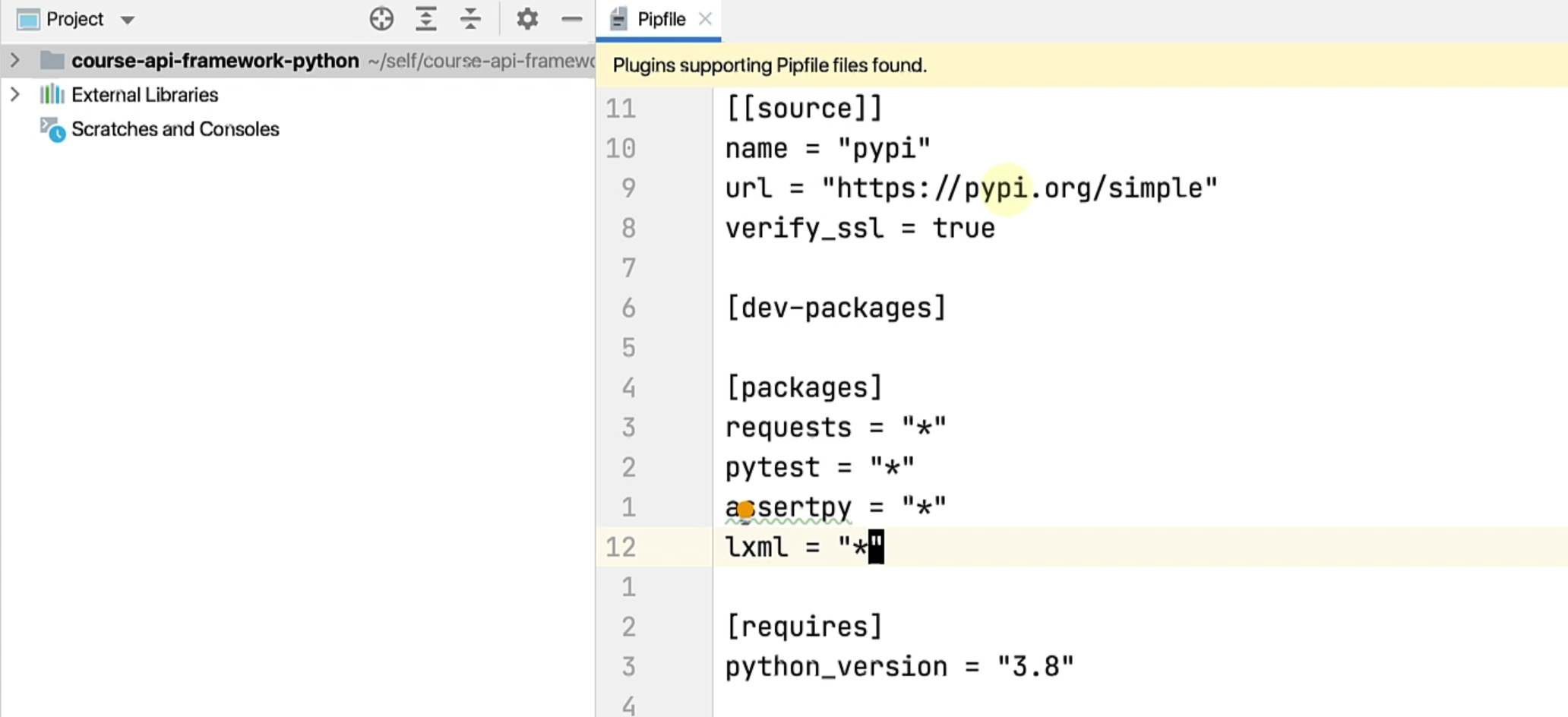
Please ensure that you run pipenv install while being in the pipenv shell to ensure that this is also installed for you.
Let's take a look at the test now.
I've already created a test for us to get started with and you can find that in covidtest.py.
Let's say I want to ensure that the total cases for COVID has crossed a million.
To do that, what I'm doing is making a request to my dummy service running on localhost.
I'm getting the XML text using response.text, and then I'm de-serializing it into an XML object, which I can work with.
Use etree.fromstring and pass your response_xml with an encoding of utf8 wrapped within bytes.
This ensures that you are able to convert your string into an actual tree that you can work with.
def test_covid_cases_have_crossed_a_million():
response = requests.get(f'{COVID_TRACKER_HOST}/api/v1/summary/latest')
response_xml = response.text
tree = etree.fromstring(bytes(response_xml, encoding='utf8'))
The main use case with XML is typically that you want to verify whether a certain node has a certain value.
So here, you can use tree.xpath and pass the XPath for the node that you are actually looking for.
In this case, if you take a look at the XML summary, what I want is, I want a total number of cases within data and summary.
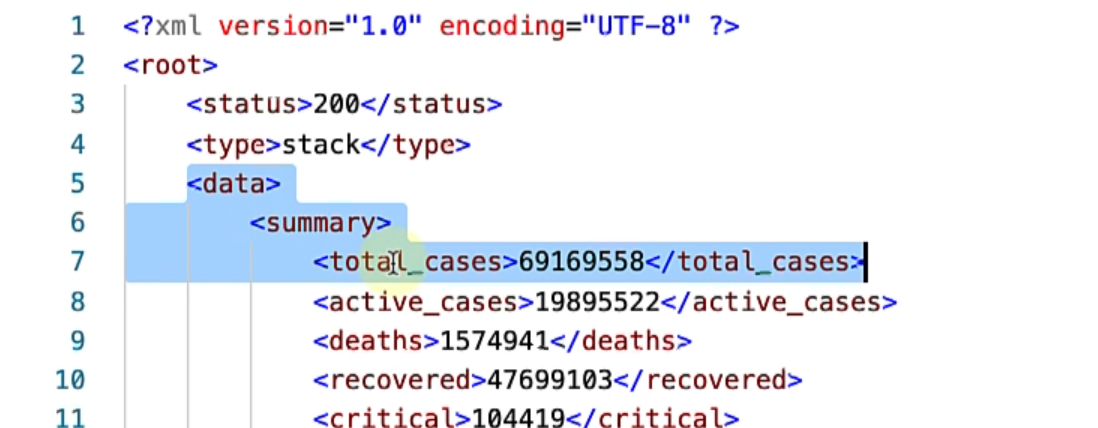
Here is the relative XPath for that: //data/summary/total_cases.
We start with data and then have an absolute path towards total_cases and I want the first element out of this list, and finally, I just want the text value of this node, so I'm doing .text.
def test_covid_cases_have_crossed_a_million():
response = requests.get(f'{COVID_TRACKER_HOST}/api/v1/summary/latest')
response_xml = response.text
tree = etree.fromstring(bytes(response_xml, encoding='utf8'))
total_cases = tree.xpath("//data/summary/total_cases")[0].text
This is going to give me the total number of cases.
Let's run this test now.
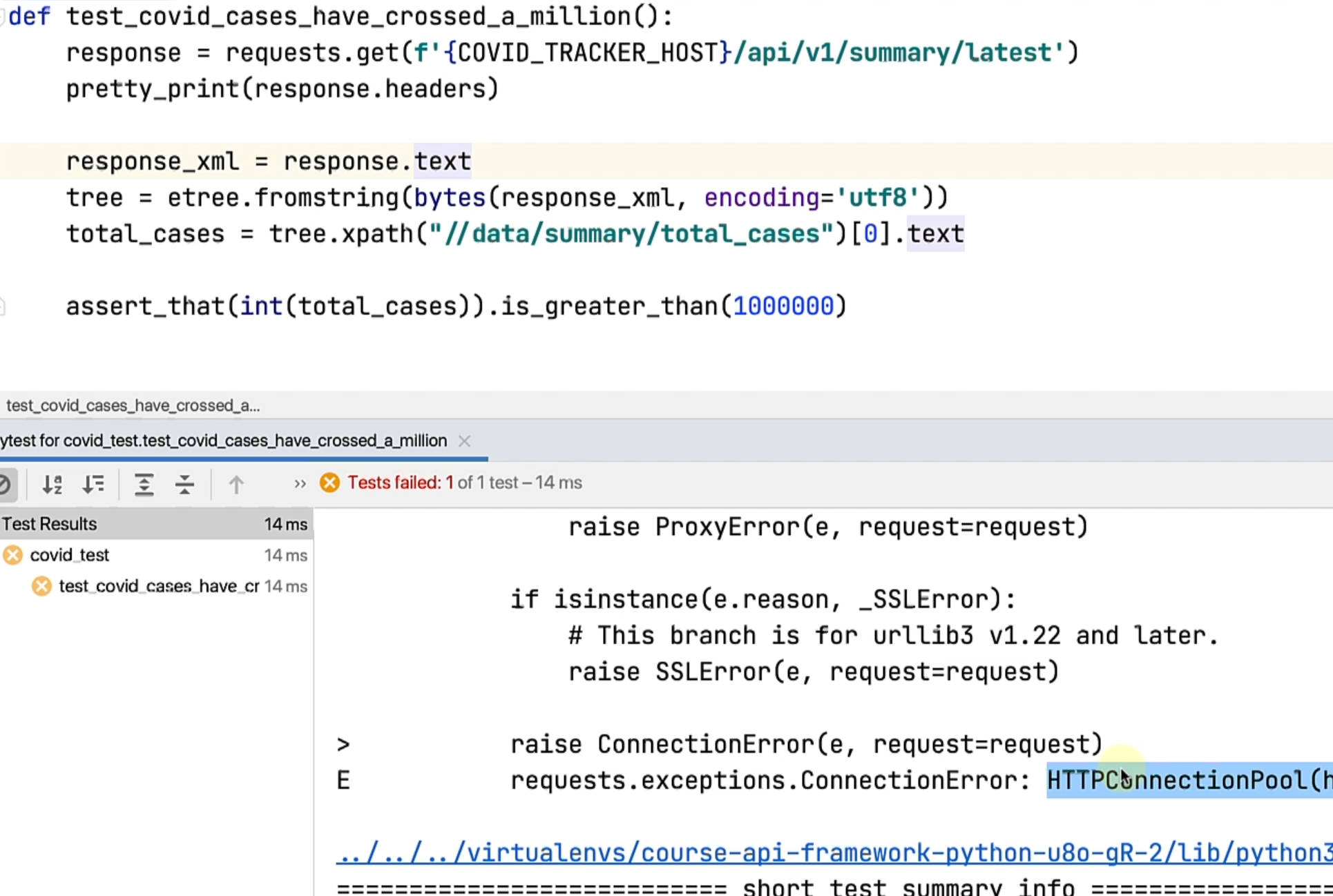
It seems to be connecting to the port 5000, which was an earlier thing, so if you're looking at this commit, go to config.py and change this to 3000 and let's run the test again.
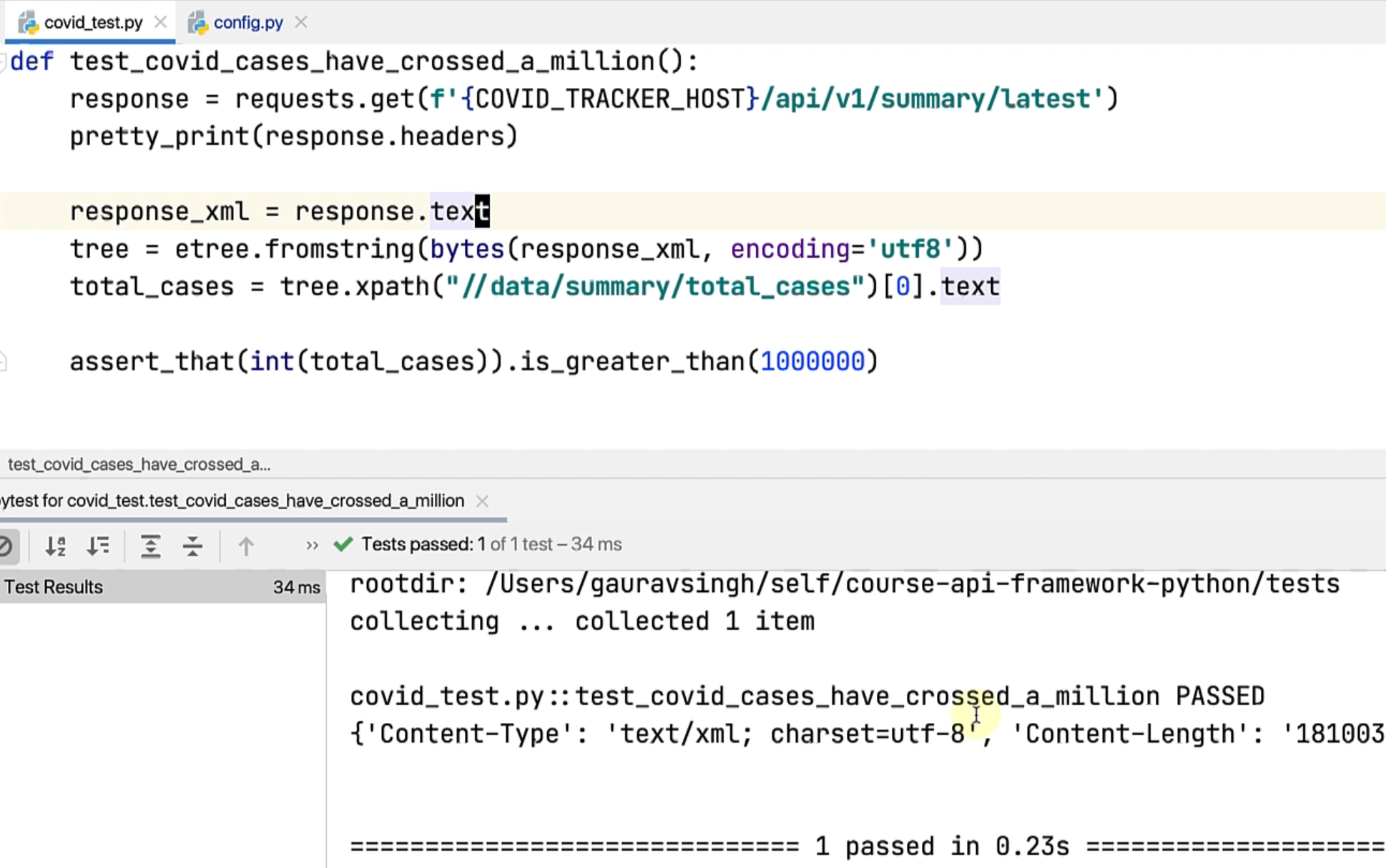
The test passes now.
# Accessing the data using XPath
There are a couple of other ways of accessing the data using XPath.
Let's see how that works.
To demo that, let's assume we want to write a test where we want to check that the total number of cases worldwide is greater than the sum of total cases at a per country level breakdown.
Let's say you want to assert whether that data is correct, so we'll write a test for that.
It's always good to write a title - test_overall_covid_cases_match_sum_of_total_cases_by_country - which is quite self-explanatory so that anyone running the test understands the intent behind it.
We want to ensure that first we make the API call and get the XML response just like before.
def test_overall_covid_cases_match_sum_of_total_cases_by_country():
response = requests.get(f'{COVID_TRACKER_HOST}/api/v1/summary/latest')
pretty_print(response.headers)
response_xml = response.text
tree = etree.fromstring(bytes(response_xml, encoding='utf8'))
We have made the call and gotten the XML response.
What we are interested in now is to get the total number of cases, which is similar to what we did here and we want to convert this to an integer since we want to actually get the conversion and do assertion on that.
def test_overall_covid_cases_match_sum_of_total_cases_by_country():
response = requests.get(f'{COVID_TRACKER_HOST}/api/v1/summary/latest')
pretty_print(response.headers)
response_xml = response.text
tree = etree.fromstring(bytes(response_xml, encoding='utf8'))
total_cases = int(tree.xpath("//data/summary/total_cases")[0].text)
Now we need the country level breakdown of cases, and we need the total of that to do our assertion against.
Another way in which you can use XPath with lxml is to use etree.XPath() and give it your XPath that you are looking for.
If you take a look at the XML, we want data, regions, and then the total_cases values.
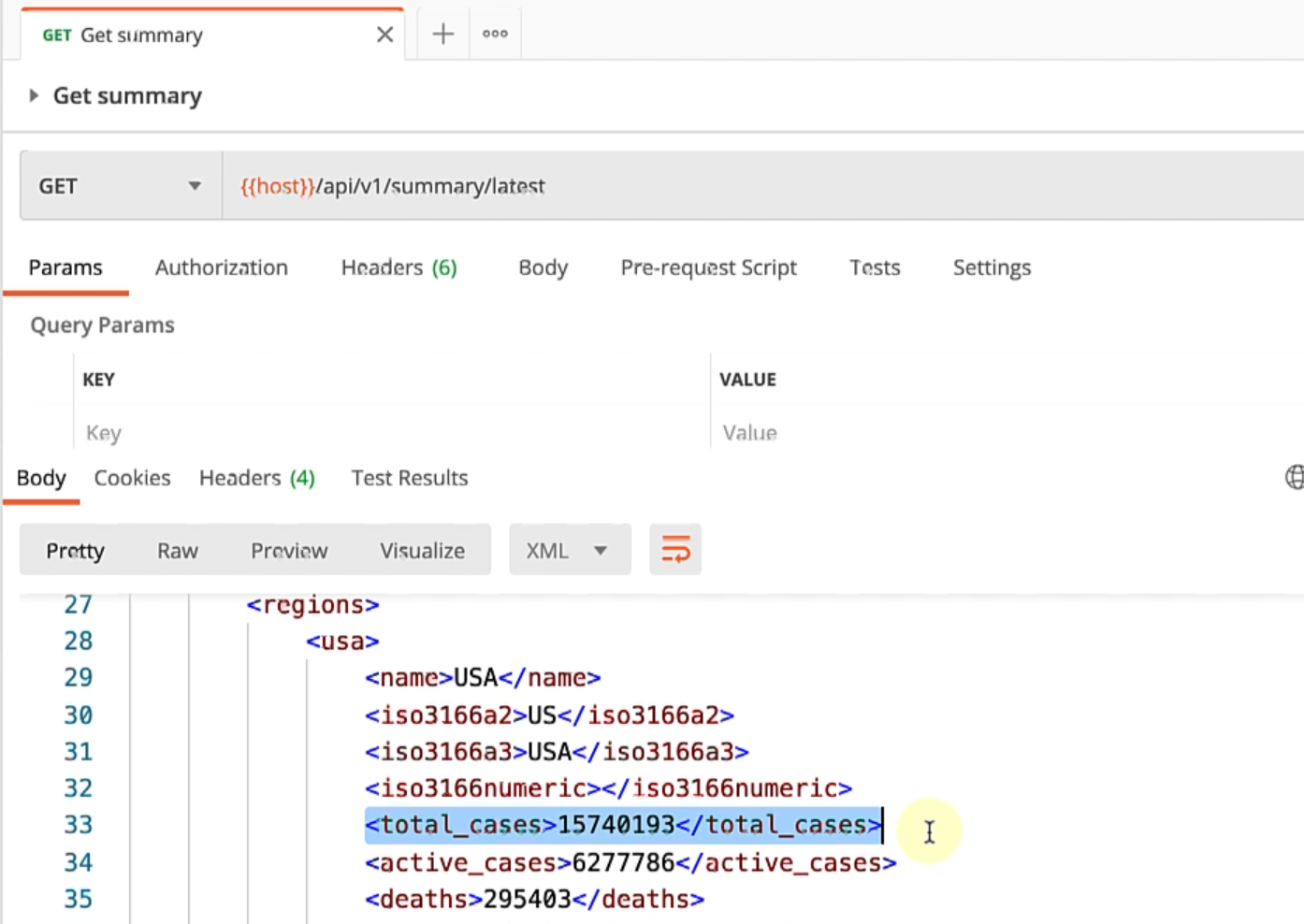
Let's say we want all of the total cases in a list format - //data/regions//total_cases - this is going to give us a XPath expression, but it's not actually going to evaluate for, so we'll say this is our search_for criteria.
What we want next is to actually total up the values from each of these individual regions.
So let's say for region in - and we're using the function search_for to make a call and pass tree in this case.
Let's say we just want to get the total, so I will say cases_total_by_country, start it as zero and add that to what we get in region.text and I'm converting it to an integer so that we can essentially get the total.
Finally, I just want to assert_that the total_cases is greater than the case_total_by_country.
def test_overall_covid_cases_match_sum_of_total_cases_by_country():
response = requests.get(f'{COVID_TRACKER_HOST}/api/v1/summary/latest')
pretty_print(response.headers)
response_xml = response.text
tree = etree.fromstring(bytes(response_xml, encoding='utf8'))
total_cases = int(tree.xpath("//data/summary/total_cases")[0].text)
search_for = etree.XPath("//data//regions//total_cases")
cases_total_by_country = 0
for region in search_for(tree):
cases_total_by_country += int(region.text)
assert_that(total_cases).is_greater_than(cases_total_by_country)
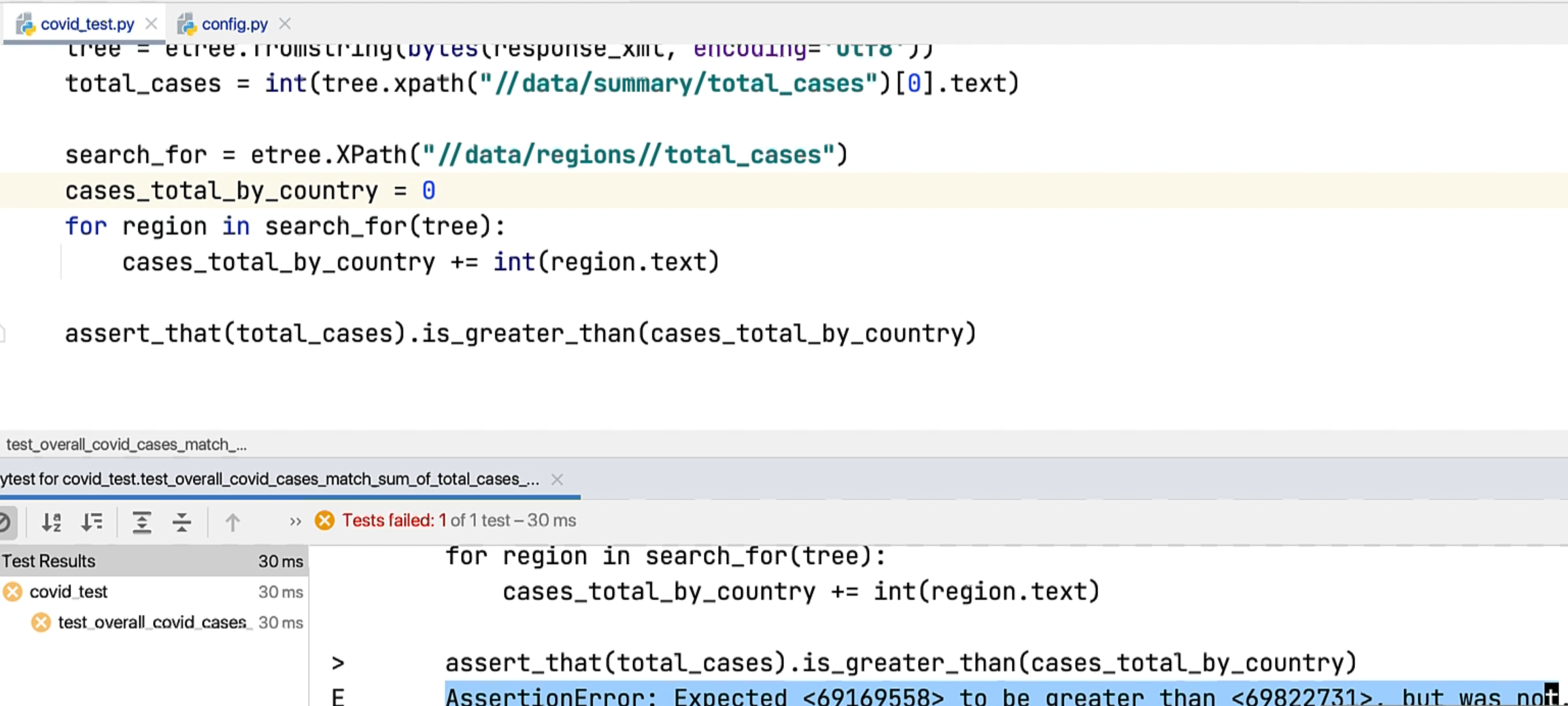
This test failed - it says that the total was expected to be greater than this, but it's not.
Clearly, we can see that there is some mismatch between this data set or some variance, which could actually be a bug.
I hope this gives you a taste of how to work with XML with Python using lxml.
There are many other use cases which lxml can actually support.
If you just search for "lxml xpath", you'll get very nice documentation on how to work with XML and XPath using lxml and what all syntax it supports.
I would encourage you to go through this and understand the API in detail - what I've given you is just a taste.
If you are making use of namespaces, you have a way to actually even pass that in the XPath expression.
Also, you can actually even generate the XPath expression if you need, by using the Element and the SubElement syntax.
There are different ways of specifying your XML - you can use etree.XML, you can use regular expressions, and we already saw how to use the ElementPath.
In our example, you can optionally pass namespaces if your XML is going to contain some namespaces and that's pretty much it on how to deal with XML responses.
If you're dealing with XML requests, a common approach to deal with that could be, you can store your XML in a file and read it from there, and then use the same method to convert it into an elementary object and then modify as per your need, again, converting it to string.
The library offers you a lot of flexibility for your use cases and covering it here would make this video very exhaustive.
What I'll encourage you to do is to go through the doc and understand how lxml can suit your use cases.
That's it for this chapter, I'll see you in the next one.
