

Transcripted Summary
Hello, everyone, welcome to chapter seven of this series on how to build an API test automation framework with Python.
In this chapter, we are going to see how to refactor our framework into shape.
So far, in our framework, we have always been exploring how to do X or Y using requests or any other library, but a framework is essentially something that is going to be shared across multiple team members and is going to be worked upon by multiple people.
So, we'll see what are some of the practices wherein we can refactor our existing code into something that is a bit more manageable, and understand the thought process behind it.
To proceed, I've already checked out the example/07_refactoring_structure branch, and let's see some of the changes that I've already made.
So we'll just go to the git log and go to this commit and see some of the changes.

# Remove unnecessary comment and replace them with well named functions/classes
The first change that I've actually done is removed all the comments that are there.
Why is this important?
You might argue that writing a lot of comments in your framework code is a good idea, right? Because it explains the functionality.
However, in the long run, there is a chance that your comments might not hold well with the underlying code that has been written, because it's easy to refactor functions as well as classes, but removing comments and tweaking them to whatever every change conforms to is often going to be very difficult.
Write clean descriptive class names and method
Ensure that you write clean descriptive class names and method names instead of writing a lot of comments.
That is the number one change.
I've removed all the comments and try to abstract it in a way wherein it is more readable.
The second is - we saw that we are directly making a call to requests.get with a BASE_URI for either our get function, or we were using create_person_with_unique_last_name.
Also, we were directly working with the response object in our tests.
# Introducing client class as an abstraction
Now, while this works for a short framework, like we have at hand, when this framework scales for multiple different endpoints for different domains that they have to represent, this is going to be a very bad practice.
If we have to change the behavior of the get function, you will have to do it in all the tests, which means, for any such change, all of your test functions have to change.
Abstract third party libraries
A good practice is usually to wrap your third-party libraries into their own class or some abstraction that your tests depend on.
One of the common patterns that people follow with API frameworks and automation is typically to abstract all the API endpoints into their own clients.
As you can see in this example, I have introduced a PeopleClient().
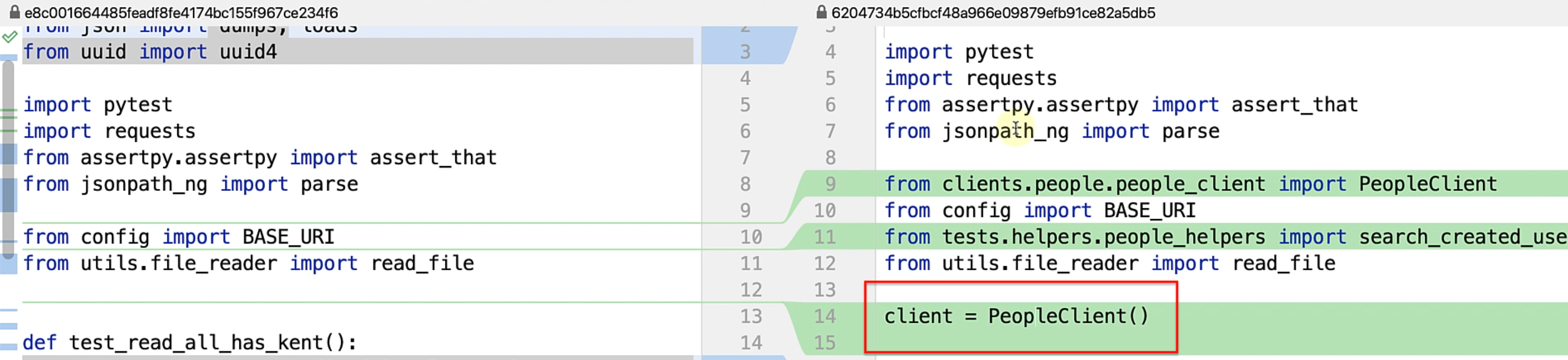
Let's see what this PeopleClient() actually looks like.
from json import dumps
from uuid import uuid4
from clients.people.base_client import BaseClient
from config import BASE_URI
from utils.request import APIRequest
class PeopleClient(BaseClient):
def __init__(self):
super().__init__()
self.base_url = BASE_URI
self.request = APIRequest()
def create_person(self, body=None):
last_name, response = self.__create_person_with_unique_last_name(body)
return last_name, response
def __create_person_with_unique_last_name(self, body=None):
if body is None:
last_name = f'User {str(uuid4())}'
payload = dumps({
'fname': 'New',
'lname': last_name
})
else:
last_name = body['lname']
payload = dumps(body)
response = self.request.post(self.base_url, payload, self.headers)
return last_name, response
def read_one_person_by_id(self, person_id):
pass
def read_all_persons(self):
return self.request.get(self.base_url)
def update_person(self):
pass
def delete_person(self, person_id):
url = f'{BASE_URI}/{person_id}'
return self.request.delete(url)
PeopleClient() is essentially a simple class that is inheriting from a BaseClient, and if you can see, the BaseClient just has a simple API header for now.
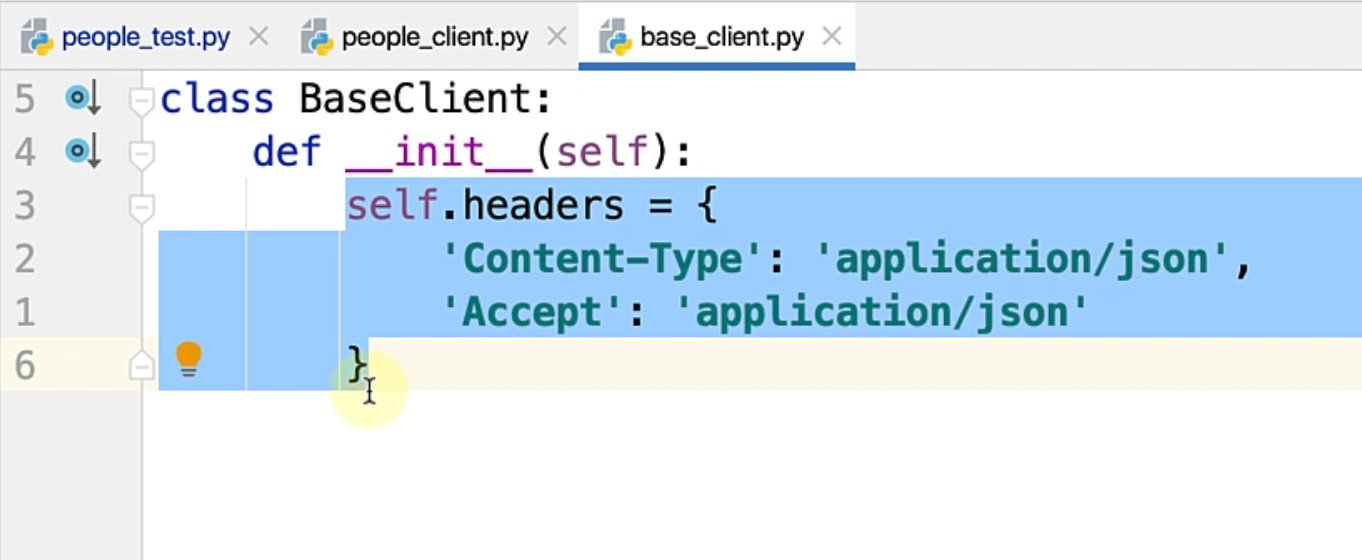
We could obviously abstract this slightly better, but for now, this is something that works well, and we are storing the base_url that this client actually supports as a variable here, so that we don't have to pass it along everywhere.
Also, we have an instance member called request, which is an object of APIRequest class.
Let's see what this is.
from dataclasses import dataclass
import requests
@dataclass
class Response:
status_code: int
text: str
as_dict: object
headers: dict
class APIRequest:
def get(self, url):
response = requests.get(url)
return self.__get_responses(response)
def post(self, url, payload, headers):
response = requests.post(url, data=payload, headers=headers)
return self.__get_responses(response)
def delete(self, url):
response = requests.delete(url)
return self.__get_responses(response)
If you can see APIRequest, this basically has the same methods that we have been working with - essentially a get, post and a delete function, that accepts similar parameters as we have been working with.
Under the hood, it actually makes a call using the requests library.
How can this be useful for future reference?
Tomorrow, if we have to move away from the requests to a different library, we could just isolate the change to this class and not have it spill over to all the independent classes.
So, this is always a very useful pattern to follow, and once we get the response, we are making a call to our own custom __get_responses function.
Let's see what this function does.
def __get_responses(self, response):
status_code = response.status_code
text = response.text
try:
as_dict = response.json()
except Exception:
as_dict = {}
headers = response.headers
return Response(
status_code, text, as_dict, headers
)
This function is extracting relevant bits of information, like the response.status_code, the response.text, as well as trying to see if it can get a dictionary out of the response.
This can happen if you have certain response scores like 204, where there is no content, which might give an error when you try to do response.json().
If it finds an exception, it returns just an empty dictionary.
Here, I have deliberately made use of an anti-pattern just to show you.
You can see that I am using a broad level Exception, which is never a good idea because you'll catch everything.
Exception Handling
It's always better to handle a very specific exception.
So in our case, this would probably be something like a json decode error or something - we can replace it once we figure it out.
Also, you get the response.headers, and then we are just creating a custom object that we'll return from this __get_responses.
What is this custom response object you might ask?
This is just a Python data class, with all these four parameters that we have already specified.
@dataclass
class Response:
status_code: int
text: str
as_dict: object
headers: dict
Let's see how this is being used now.
You have this APIRequest() and observe that I have created some specific functions that this people set of API supports.
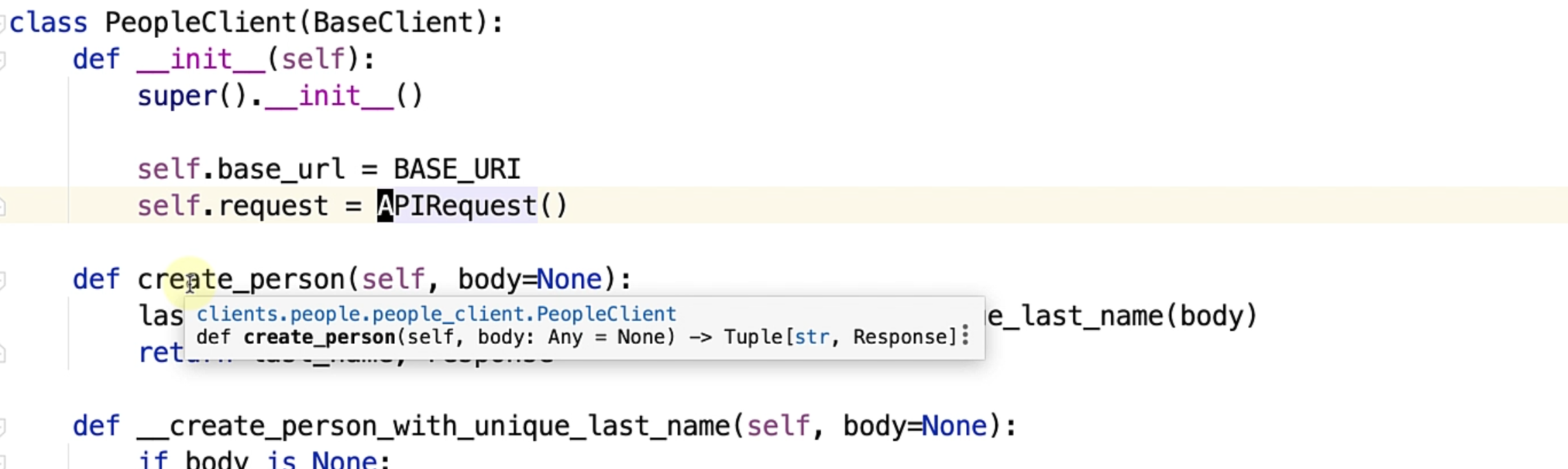
We have a function for create_person, we have a function to read_one_person_by_id - this is deliberately not implemented for you to try it out as an exercise.
You have read_all_persons, wherein you are doing the same get operation.
You have an update_person - again, left as an exercise for you, and the delete function, which is essentially what we had in our people_test file.
Notice the create_person is now making a call to __create_person_with_unique_last_name, and I have deliberately prefixed it with double underscore to ensure that these functions are not visible to client classes - this is how you declare a private method in Python.
Private accessors
Essentially, if it has a single underscore, it would be accessible, and if it is double underscores, it would be name mangled and you won't be able to see it in any client classes.
Don't worry if that doesn't make sense for you if you are new to Python, you will get the hang of it once you become more familiar with the language.
This is nothing new.
It is similar code, however, notice some key differences.
In these particular functions, I am just returning the response.
I'm not taking a call whether that response has to be correct or failed.
Why is this a useful pattern?
Because you are essentially making this client very open, with just making a request to your APIs, and returning the response in the expected structure.
The test can actually decide whether that condition met its need or not.
This way you can use the same function to do a success scenario like a 2XX response code, or you can even pass in some bad input and see that the response is actually a bad one.
If you take a call in this particular class, you will have to write multiple functions, and that would just bloat this class.
You essentially want your concerns to be separated at the appropriate abstract level.
If you go to the people_test class, I have replaced all the calls for either the get, post or delete operations to methods in these clients.
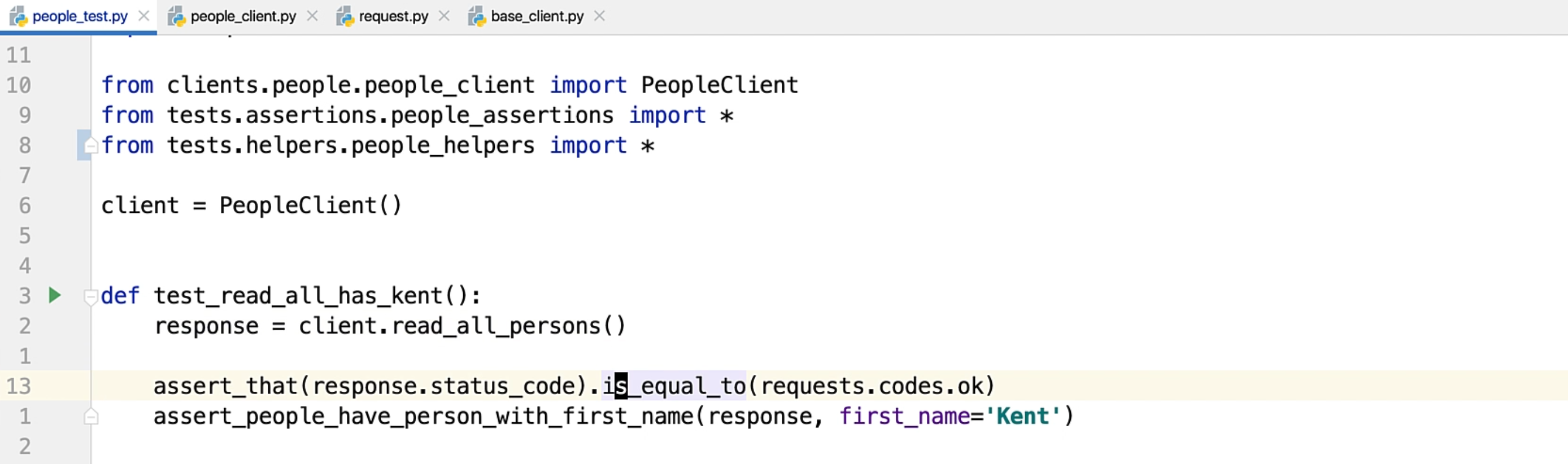
This looks slightly better organized.
If you compare it with the previous test file that we had, this is much more readable because it has lesser lines of code and it has abstracted the relevant functionalities into relevant bits.
Test Pattern
Essentially, every test is following a very simple pattern.
You are arranging something, you are acting on that, and then you are asserting.
In other words, this could also be interpreted as:
You set up something
You perform a singular action on your application
Assert that it met your expectations
Finally, just tear down
In some of these cases, the setup and teardown steps are not applicable.
# Abstract common assertions into their own module
For instance, a get request is not going to manipulate the database in any way, but if you are setting up your data, you might want to take care of that.
In most of these tests, see that I'm doing an operation using the client, and then I'm just asserting certain values.
While I have left the status code validations still intact the same way, I have taken the liberty of extracting other functional assertions into their own class.
I have introduced a people_assertions.py.
Under the tests directory, I now have an assertions package, which has a people_assertions.py module.
from assertpy import assert_that
def assert_people_have_person_with_first_name(response, first_name):
assert_that(response.as_dict).extracting('fname').is_not_empty().contains(first_name)
def assert_person_is_present(is_new_user_created):
assert_that(is_new_user_created).is_not_empty()
This has the root level functions without the need for a class - this is also another pattern you might want to consider.
It's always not necessary to wrap everything into a class within the Python ecosystem - you might be just okay with having the root level functions, if it satisfies your needs.
Here, you can see that these are the same functions that I had in my test files earlier, and now I have abstracted them into some functions which clarify the intent.
I now have a function that checks if the people response has a person with a first name.
This is much more readable and better than having this line of code in your test function, which is a lot of cognitive overhead.
assert_that(response.as_dict).extracting('fname').is_not_empty().contains(first_name)
Ensuring that your test functions are readable and they clarify the intent is very important.
If you notice, I have followed a similar pattern in all the other tests, and I've actually refactored them.
# Abstract helper methods into their own class/module
Also, coming to the test test_person_can_be_added_with_a_json_template, notice that I have also abstracted the function to search for nodes with a JSONPath into its own helper function.
result = search_nodes_using_json_path(peoples, json_path="$.[*].lname")
You can see I've introduced a helpers package with people_helpers.py, with some of these common operations that the tests might need.
from jsonpath_ng import parse
def search_created_user_in(peoples, last_name):
return [person for person in peoples if person['lname'] == last_name][0]
def search_nodes_using_json_path(peoples, json_path):
jsonpath_expr = parse(json_path)
return [match.value for match in jsonpath_expr.find(peoples)]
Over a period of time, if we need sophisticated functionality for JSONPath, we might want to extract it into its own dedicated module.
Here is another neat tip for framework development and design.
Do not do a big design upfront
Do just enough design, which is sufficient to give you an idea of the structure that you are going to work with, and when the tests or your classes are taking shape, decide what pieces of functionality actually are better suited for certain modules or classes, as we have done in these particular cases.
This ensures that you are able to build your framework incrementally, without having something that you are never going to use.
Also, ensure that you only create functionality that you really need in your framework - having dead code is a very bad practice.
One final thing that I would like to show you is, if you'd notice in the people_test class, we had this function where we were reading from the json template and actually getting a create_data.
def test_person_can_be_added_with_a_json_template(create_data):
client.create_person(create_data)
response = client.read_all_persons()
peoples = response.as_dict
result = search_nodes_using_json_path(peoples, json_path="$.[*].lname")
expected_last_name = create_data['lname']
assert_that(result).contains(expected_last_name)
But if you can see, the setup fixture that we created is not present here.
# Extract fixtures into conftest.py file
I've taken the liberty of moving the setup fixture into a conftest.py, and this is a Pytest pattern wherein if you have a conftest.py at a specific module hierarchy, these fixtures will be automatically discoverable by your test.
import random
import pytest
from utils.file_reader import read_file
@pytest.fixture
def create_data():
payload = read_file('create_person.json')
random_no = random.randint(0, 1000)
last_name = f'Olabini{random_no}'
payload['lname'] = last_name
yield payload
This ensures that your setup and teardown code is separated from your test function and ensures that you have a more readable function, without having too much cognitive overload with multiple lines of code and whatnot.
That's it for this refactoring.
I have only done this for the people_test class for now.
You might want to take this ahead and think more about what relevant structures and framework components you can build for your own framework, and then go from there.
To practice, you can check out an earlier commit from this branch and then try this on your own.
Another exercise for you could be, you can see if you can refactor the covid_test that we created inline with the above changes and see how your framework changes with XML in place now.
Also, you can try it out for your schema tests that we just created.
In conclusion, this is the final thought I want to leave you with - try to **think a bit ahead **on how your classes and your functions are going to be used.
Try to **minimize duplication **if possible, and try to identify relevant data structures, classes as well as methods, which make sense for you and are reusable and extendable.
Do not couple too much logic together, wherein if you have to make a change you have to touch a lot of places in your code, and that is essentially one of the good design principles to follow.
That's it for this chapter, I'll see you in the next one.
