

Transcripted Summary
In this chapter, we are going to understand how to do API response schema validations.
Most of the APIs these days use JSON as a data format.
In the absence of a dedicated contract test between the consumer as well as the producer, you might want to write a test on the live API response.
Essentially, something like, here is a schema, and I want the response to be validated - whether this matches this expected schema or not.
There are many libraries in the Python ecosystem to achieve this.
We will be taking a look at Cerberus, which is a very popular library for this purpose.
There are other options like JSON schema, Voluptuous, and even Pydantic.
If you just Google for Cerberus Python, you will come to their docs, and it is a very neatly documented tool - we'll see how it works.
Coming back to the project that we have been working on, I've already checked out the example/06_data_validation branch, which has this sample test that we are going to take a look at.
Let me walk you through how this test is exactly structured.
We want to make a read request for one person_id in the same people API that we have been looking at, and want the response to match an expected schema.
So, if we hit our people API with the person_id 1, we see that we get this response structure:
{
"fname": "Doug",
"lname": "Farrell",
"person_id": 1,
"timestamp": "2020-12-01T16:50:36.842997"
}
We have, essentially, an object with certain keys, like fname and a string value.
Similarly, lname with its string value, a person_id with a number, and a timestamp in a string format.
So, what we want is that when this API is hit, I want to check that the response matches the structure.
Cerberus is a tool that helps us do exactly that.
To ensure that it is set up, you need to make sure that the package is installed.
If you don't have it installed already, just do:
pipenv install cerberus
That should take care of it.
In our case, I've already installed Cerberus in the virtual environment that we have, so if you just take a look, it is already added as a dependency.
The main crux of Cerberus is actually the schema - it is a dictionary-like-structure that they define.
Cerberus defines its own sort of mini language to define the schemas, as well as their types.
Let's take a look at the example that we have been looking for in schema_test.py.
Essentially, we'll define our schema as our dictionary with all the keys specifying the actual keys in the response JSON.
schema = {
"fname": {'type': 'string'},
"lname": {'type': 'string'},
"person_id": {'type': 'integer'},
"timestamp": {'type': 'string'}
}
The value of these dictionaries are actually another dictionary with a set of additional parameters.
Here, we specify that the type of fname has to be string.
Similarly, lname has to be a string.
person_id has to be a number and timestamp also has to be a string.
So this is a very simple format of specifying what data type the specific key has to be.
Here is our simple test where we are making a get request.
def test_read_one_operation_has_expected_schema():
response = requests.get(f'{BASE_URI}/1')
person = json.loads(response.text)
validator = Validator(schema, require_all=True)
is_valid = validator.validate(person)
assert_that(is_valid, description=validator.errors).is_true()
We are converting that into a dictionary.
Now coming to the main logic of how Cerberus works, we create an object of a Validator class and pass it to the schema dictionary that we have already created.
Notice that I've given require_all as True - this is a global flag that I can set for this particular schema, specifying that all the keys in this response are required.
So, if for some reason, our API tomorrow skips timestamp as a field, we will get an error.
This gives us a validator object.
Also, if you want to specify this at a specific key level, you can always just add that.
schema = {
"fname": {'type': 'string', 'required': True},
"lname": {'type': 'string'},
"person_id": {'type': 'integer'},
"timestamp": {'type': 'string'}
}
You can set required as True or False.
Cerberus gives you the flexibility of specifying it at a field level, or even at a global schema level.
Once we get the validator object, we just need to call the validate function and pass it the actual Python object.
This gives us a return of whether the schema validation passed or failed.
Finally, we expect our schema validation to pass so we are expecting that is_valid should always be true, and if it fails, we want a description of what field actually failed, so we are printing validator.errors.
Let's run this test and see if this works.
We can see that our test passed.
Let's see how it looks if it fails.
What if I change the person_id from number to string, and then run the test again?
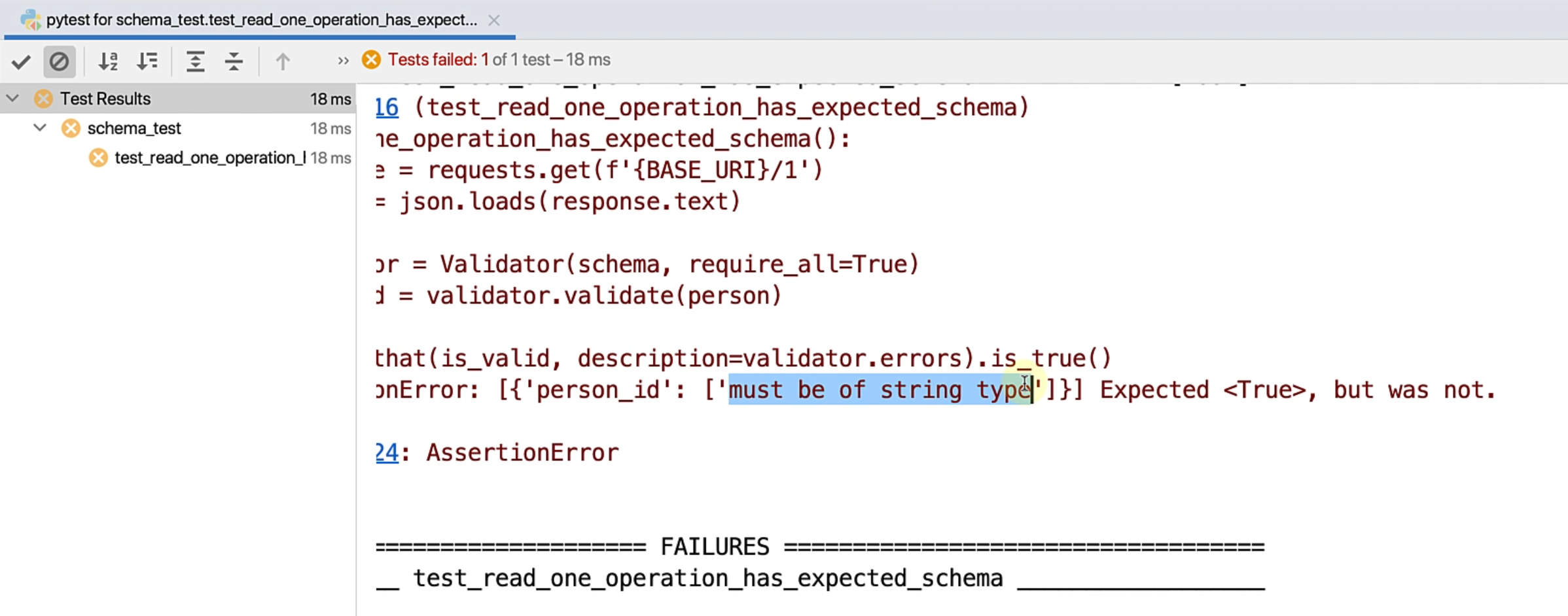
This time, you can see that the test fails as expected.
We get a very clear description that person_id must be of string type, wherein we expected True, but it was not.
So, this is a very neat way of doing some schema validation on your API responses.
What if we wanted to achieve this for all the people in the persons database?
If we hit our API, this essentially gives us a list of similar objects.
So, one way of achieving this could be, we could actually just iterate in the responses and then check whether it matches our needs or not.
Let's quickly write a test that achieves just that.
I'm going to make a copy of this and call the function test_read_all_operation_has_expected_schema().
We know that the URL doesn't have the person_id, so I'm going to remove that.
Now, what I want is after defining the schema, I want the same validation to be repeated for all the persons in the database.
So, let's just loop.
What we want is for the entire validation to be performed, and then fail in the end.
Let's wrap this with soft assertions, as you saw earlier.
def test_read_all_operation_has_expected_schema():
response = requests.get(f'{BASE_URI}')
persons = json.loads(response.text)
validator = Validator(schema, require_all=True)
with soft_assertions():
for person in persons:
is_valid = validator.validate(person)
assert_that(is_valid, description=validator.errors).is_true()
Let's just run this test.
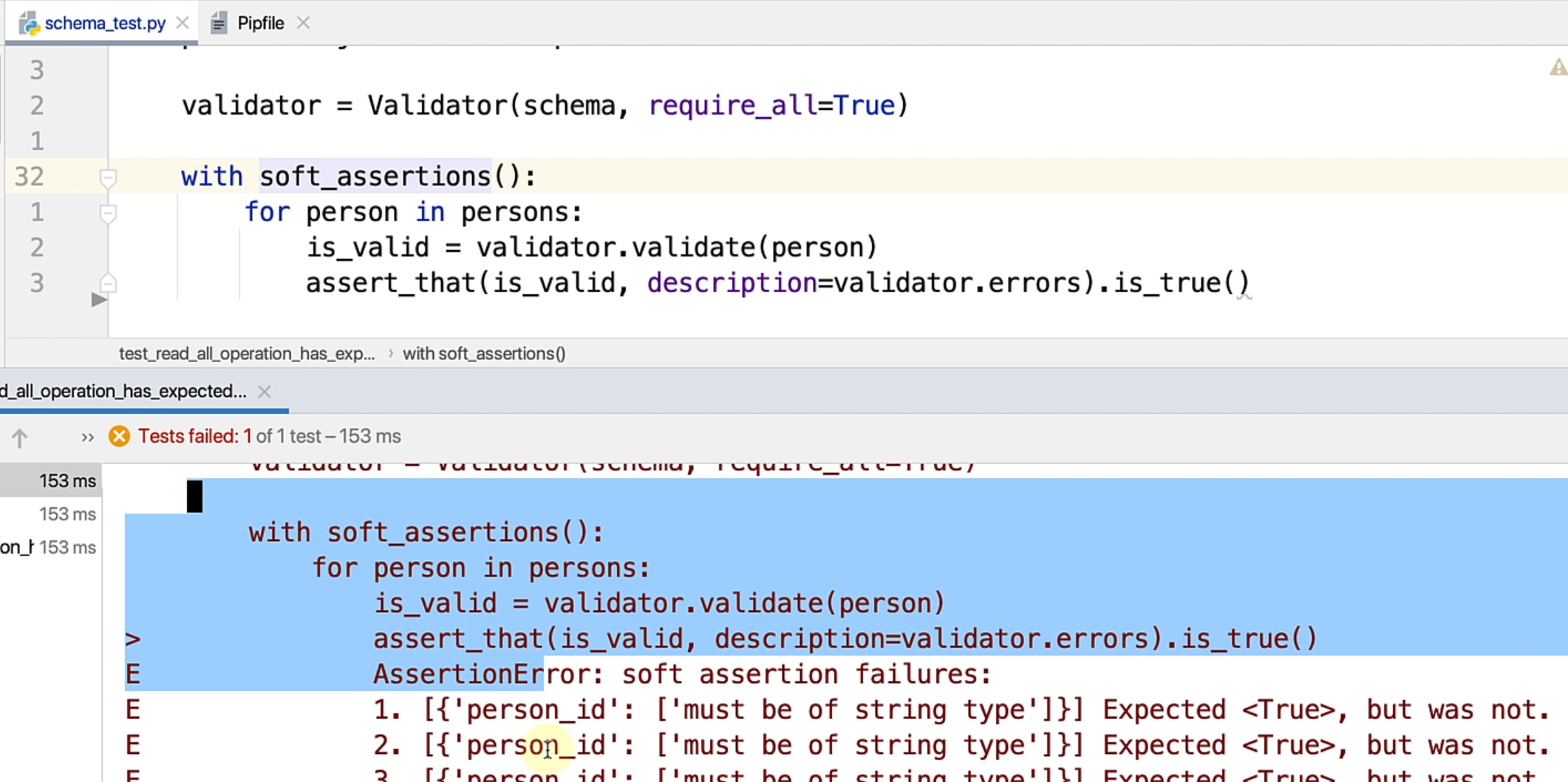
You see the test fails because we have not yet changed person_id to the expected value, and what you can see is it repeated the validation for all the persons in the list.
Let's just change this back and run the test again.
Now the test passes.
So, this is how Cerberus works for the most part.
You can actually go and read through the docs and see how the validation rules, as well as the schemas, are set up for all the different use cases that you might have.
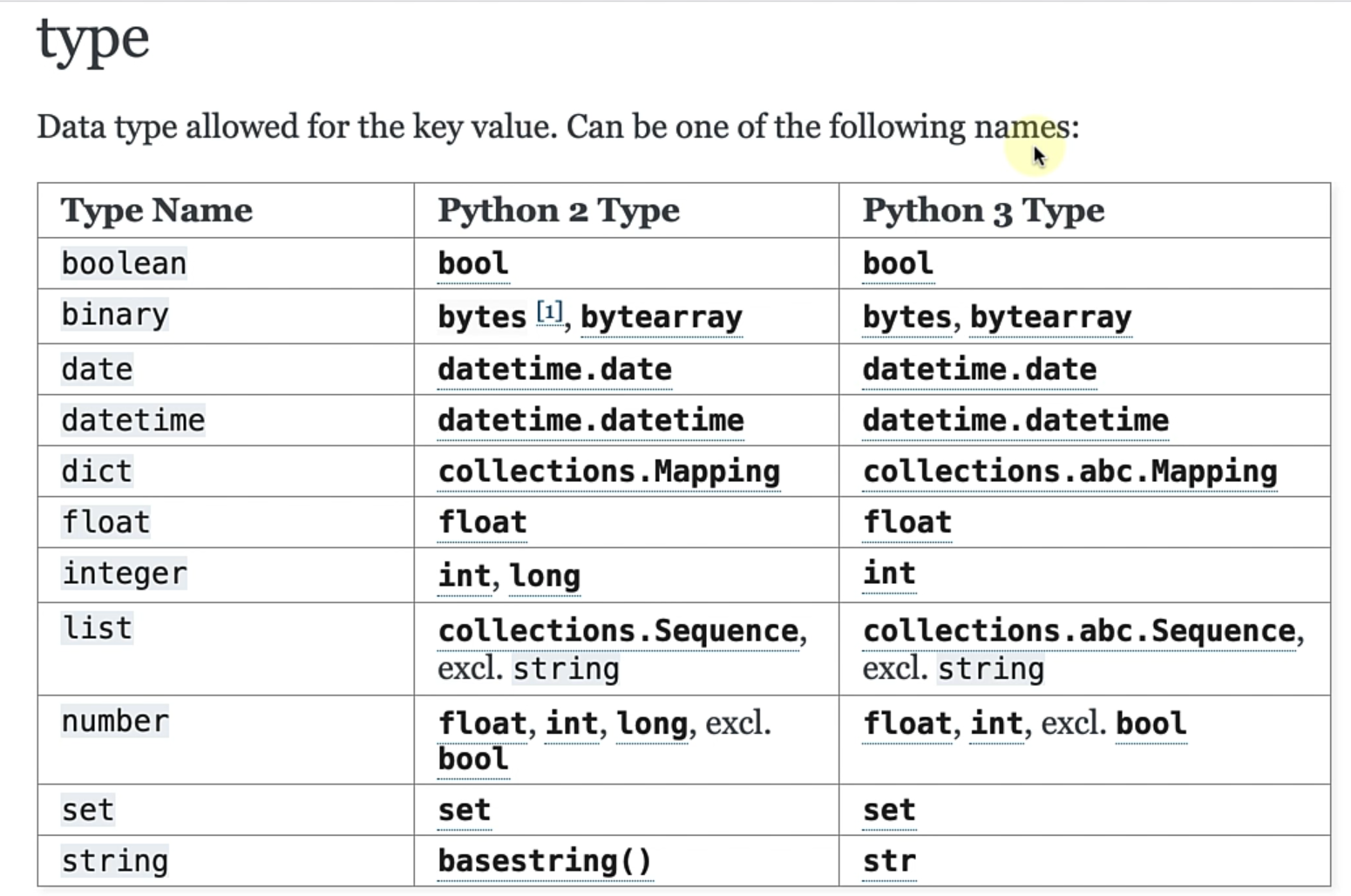
If you go to the validation rules, you will find a section where it specifies all the data types that Cerberus actually supports, and how it matches to a Python 2 or a Python 3 data type.
In conclusion, API response schema validation is an important component to build into your frameworks.
I hope that you will explore Cerberus or an equal tool to build this coverage into your framework.
That's it for this chapter, I'll see you in the next one.
