

Transcripted Summary
In this chapter we are going to look at what the version control system Git is and how it differs from other version control systems.

Git is one out of many version control systems, but it is probably the most well-known and used one these days. This because it version controls the Linux kernel and the huge popularity of GitHub, GitLab, and Bitbucket.
Git arose out of the Linux development community, and in particular Linus Torvalds who invented it in 2005. It has matured and evolved a lot since then.
The major difference between Git and other version control systems is the way Git thinks about data.
Other version control systems like Subversion and PerForce think of the information they store as a set of files, and the changes made to each single file separately over time.
Git is very different to this. Whenever you create a new commit, Git takes a picture, a so-called snapshot, of all your files.

By taking a Snapshot, Git creates and compresses and stores three objects.
The snapshot itself, also called the Tree Object
The file or files which have to be versioned, called the Blob Object
The Commit Object.
The Snapshot Object holds a reference to the compressed file objects and the Commit Object holds a reference to the Snapshot.
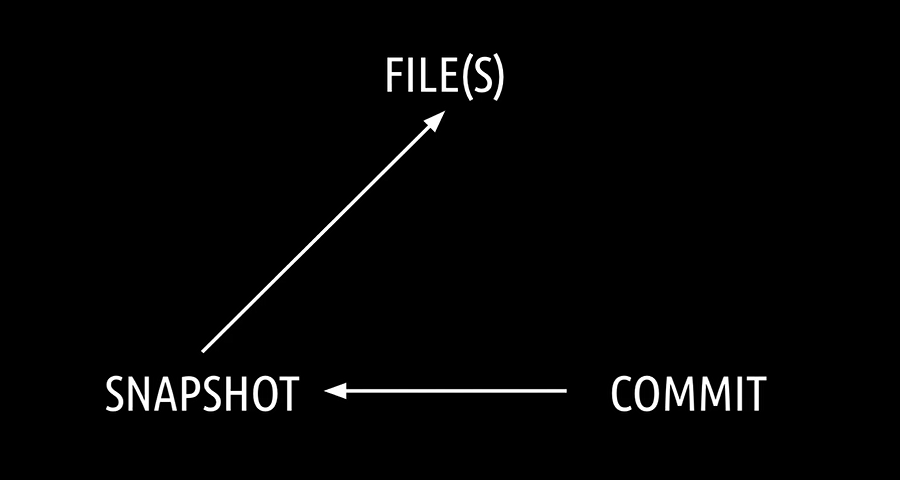
To be efficient, if the already existing files didn't change when committing something, Git simply adds the hash of the compressed files, Blob Objects to the new snapshot.
If the already existing files have changed, Git compresses these changed files, stores them, and adds the hash of these compressed files to the new snapshot.
Simply said, Git is a file based key value store.
You can insert any kind of content and get back a unique key. Every object in Git can thus be uniquely identified and referenced by its key.
But what does such a key look like?
Whenever Git creates one of these 3 objects, it is checksummed with a so-called SHA-1 Hash.

This hash represents the key of that particular object. The hash itself is composed of 40 hexadecimal characters, 0-9 and A-F, and calculated based on the content of the object.
So, we have the well-known commit hash, the snapshot hash and the file hash. With that mechanism in place, Git has integrity, which means it is impossible to change anything without Git knowing about it.
We will see in the next chapter where we can actually find these objects in Git.
# Distributed Version Control System
Git is a distributed version control system, short DVCS, which means that every committer on a project has always a copy of the whole repository on their machine. So, one can commit to the Git file system also in offline mode.
It doesn't actually matter where you go for hunting. You can work and commit any time on your machine as long as you have battery power of course.
Other version control systems, like Subversion or CVS, have a centralized repository model, and they're called centralized version control systems. They have a single database in place on a server and you need to be online and connected to it in order to be able to commit.
# Three States, Three Trees
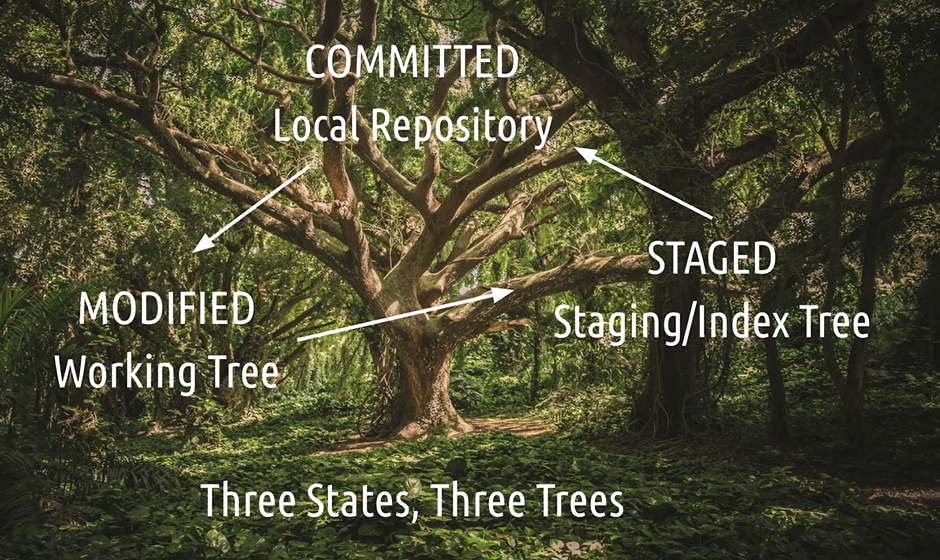
Git has three main states, also called trees, that your files can reside in.
Modified or newly created data is living in the Working Tree. This is the place where your actual files, which you can see, are on your desk.
Stage data that you have marked a search, which then goes into your next potential commit, lives in the Staging, or also called Index Tree. You can also see this tree as a kind of packaging station for your files. In reality, this is nothing else but a simple binary file.
Finally, there is the commit data, which goes into the object store, also called the Local Repository Tree.
Of course, there is also a connection between local repository tree and working tree. In the coming next chapters, you will see how they all interact with each other.
