

Transcripted Summary
In previous chapters, we've seen how to pass constant values as parameter values to our tests by providing them inline with some dedicated annotations that JUnit 5 provides.
How about if our tests require input data that is found in CSV files where the values are separated by some sort of delimiter?
For such tasks, we can use the @CsvFileSource annotation from JUnit 5, and we can provide all those values very easily by specifying the name of the file and the location of the file from where we need to read these values.
Let's start by creating our test data file.
I will go to the "Project" pane, and in the test folder I will create a "New" "Directory" - namely from the suggestions, the resources folder.
This is where I will create my file, and I will create a new folder inside here and I will call it params.
I will create a CSV file and let's say that we want to have a shopping list.
So we have some products, we have the prices, we have the quantities, and so on.
Therefore, I will name the file shoppinglist.csv.
I will specify a header so that we know what values we are inserting into this file.
I'm going to say name,price,quantity,unit of measure,provider, provider being who we wanted to buy these products from.
So let's start with some values.
I will just give some random values here.
So I will say tomato, and for "price" I would put it as 1.5 because I want to read a double value from this file.
For "quantity", let's say 2.
Let's also specify the "unit of measure" here after the "quantity" so that we know what we are referring to when we're saying 2.
For "unit of measure", I will say kg, which means kilograms, and as "provider", I will say grocery store.
Next, I want to buy carrots and I want them to be no more than 3 when it comes to the price.
Let's say, I want to buy 5, again in kg, and I want to buy them from a supermarket.
Then, I will want some cabbage, and I would like it to be no more than 1.2 in the currency we're using, and I want to buy 10 kg, and I want this again to be from the grocery store because that's where it's better.
Last but not least, let's say we want to buy some beetroot, and for this, we are willing to go up to 5 - whatever you have in your currency - and we need 1 kg of this product, and we want to buy it from the supermarket.
Okay, so we have created the values that we will want to pass to our test.
name,price,quantity,unit of measure,provider
tomato,1.5,2,kg,grocery store
carrot,3,5,kg,supermarket
cabbage,1.2,10,kg,grocery store
beetroot,5,1,kg,supermarket
Let's see how we will do that.
I will go back to my test class where I defined the previous parameterized test methods, and I will create a new @ParameterizedTest.
So I will, again, specify this @ParameterizedTest annotation, and then I will start creating the method signature.
I will say csvFileSource_, and the types that we want for our parameters will correspond to the values that we have in our CSV file.
So as you can see for the first parameter, we want it to be a string.
The second one needs to be a double.
The third one needs to be an int and the remaining ones will be strings.
So back in the class, I will name this method csvFileSource_StringDoubleIntStringString.
Again, in your tests, please give them relevant names.
The first parameter that we want to pass to this method will be the name of the product we're buying.
The second parameter will be a double - namely, the price.
The third one will be an int - namely, the quantity qty.
Then we will have a String unit of measure uom.
And then we will have a String with the provider value.
Again, in this test, we only want to output all of these values to the console.
But of course, in your tests, you will probably do something more interesting with them.
@ParameterizedTest
@CsvFileSource
void csvFileSource_StringDoubleIntStringString(String name, double price,
int qty, String uom,
String provider) {
System.out.println("name = " + name + ", price = " + price +
", qty = " + qty + ", uom = " + uom + ", provider = " + provider);
}
Now, how would we provide these values?
We know we've already created a file.
Therefore, we will be using a @CsvFileSource annotation, and here we will need to provide the location of the file we're using.
Because our file is inside the project, we'll go back to where we have it and I will just right-click on the file name, "Copy", "Copy Path".
Here we have several options, but the one we are interested in is the "Path From Content Root", so from the root of the project.
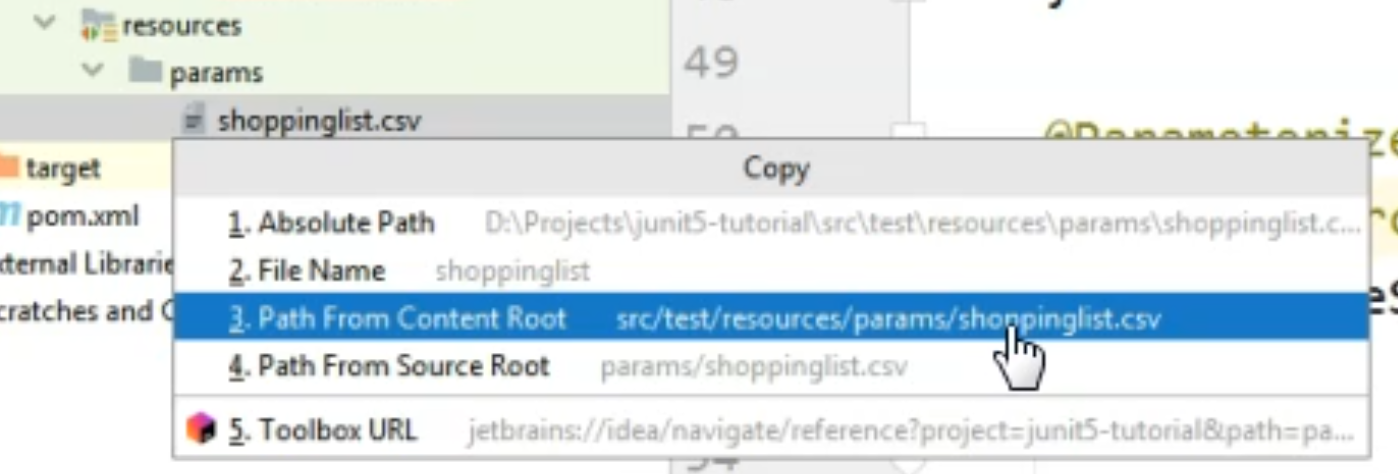
And that path is src/test/resources/params/shoppinglist.csv, so this is the one we are going to use.
Having the file in the project makes most sense when we want some test data.
So coming back to the @CsvFileSource annotation, I will just paste the path to where we can find the file.
Now, keep in mind that here, when the test data will be read from the file, a conversion will be made between those values that we specified there and the types that we specified for our parameters.
Each line will be read from the CSV file and each of those values will be transformed into these types.
Remember that on the first line of our file, we had the header, so we had the description of what each column represents.
In the case of the quantity and the price - on the first line, we don't have any ints or double values.
Therefore, we will have a conversion error unless we tell this annotation, the @CsvFileSource annotation, that this line is a header line, and so we are not going to read any parameter values from this line.
We just want to skip the first line of the file.
That can easily be done by going back to our test.
Additionally, in the @CsvFileSource annotation, we want to specify the number of lines to skip numLinesToSkip - so we want to skip the first line of the file.
In some cases, when you receive this file from different sources, you might need to skip several lines, not just the first one.
This attribute is very useful for that because you can specify an int number of lines to skip, so we can specify 1, 3, 5, or how many you need depending on that file.
@ParameterizedTest
@CsvFileSource(files = "src/test/resources/params/shoppinglist.csv",
numLinesToSkip = 1)
void csvFileSource_StringDoubleIntStringString(String name, double price,
int qty, String uom,
String provider) {
System.out.println("name = " + name + ", price = " + price +
", qty = " + qty + ", uom = " + uom + ", provider = " + provider);
}
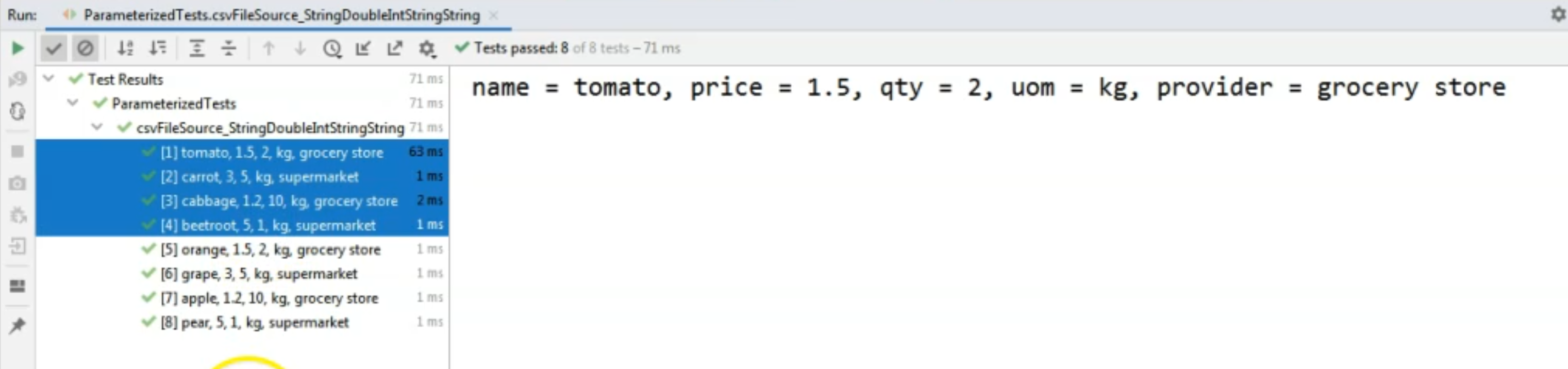
Now let's run the test to see the output at the console.
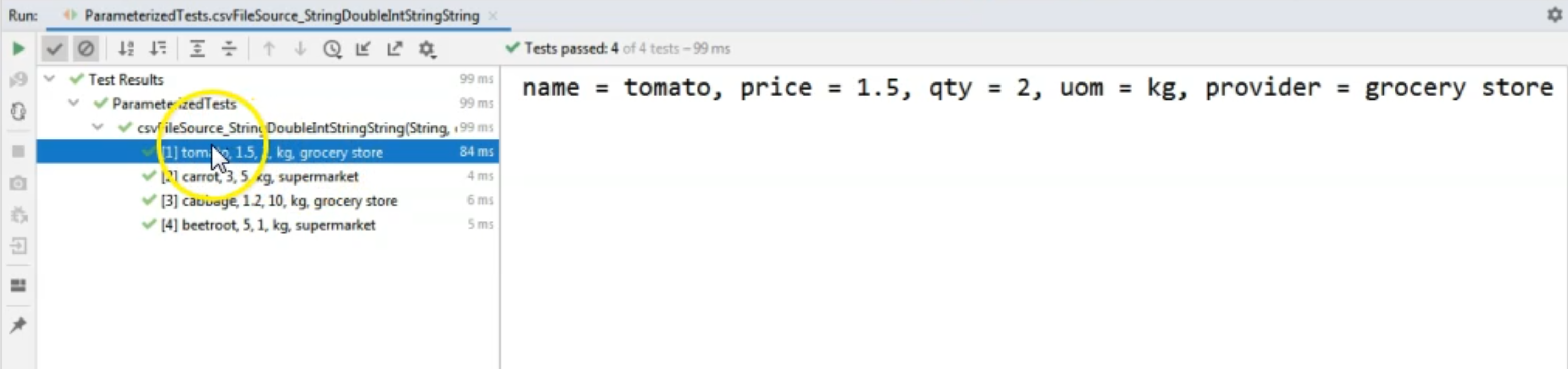
As you can see on the left-hand side, we ran this method and the values that were read from the file are correct.
So for example, for the first test method invocation we read "tomato", "1.5" which was the price, "2" which was the quantity, in "kg" that we wanted to buy and the fact that we want to buy this from the "grocery store".
On the right-hand side, again, you can see that the output of the test is also correct, so the values that were read from the file were correct.
So this is great - this is a very easy way to read these values from a comma-separated values file.
An awesome feature when it comes to this annotation is that you can specify not just one file, but even more files if you want to.
In order to do that, you would have to provide the location of these files as an array, so you will need to provide an array of CSV files to this annotation.
So let's quickly show how that can be done.
I will just go to my initial CSV file and I will copy this file and I will paste it and name it shoppinglist2.
I will only quickly change the name of the products.
So I'm going to say orange, grape, apple, and pear.
This is, again, just so we can see that when we run the test, there are different values there.
name,price,quantity,unit of measure,provider
orange,1.5,2,kg,grocery store
grape,3,5,kg,supermarket
apple,1.2,10,kg,grocery store
pear,5,1,kg,supermarket
So we're actually reading from two different files. Now, I will just copy and paste, again, the path of the initial file, and I will change that to be the second file.
@ParameterizedTest
@CsvFileSource(files = {"src/test/resources/params/shoppinglist.csv",
"src/test/resources/params/shoppinglist2.csv"},
numLinesToSkip = 1)
void csvFileSource_StringDoubleIntStringString(String name, double price,
int qty, String uom,
String provider) {
System.out.println("name = " + name + ", price = " + price +
", qty = " + qty + ", uom = " + uom + ", provider = " + provider);
}
Now, as you can see, we are passing in two CSV files, each having the exact same structure, so they have the same header and they have the same information inside them.
So we are, again, talking about the name, the price, quantity, unit of measurement, and provider of some products.
If we run this test, we will now see that instead of the initial values that we had, we will now have the values from both of the files - so now instead of four test runs, as we had initially, we have eight, one corresponding to each line in both of the files that we provided as a resource.
Now how about if our CSV file is not separated by a comma, but instead by some other separator?
No problem - we are just going to go to the shopping list and I will make a shoppinglist3 here. Of course, copy and pasting it.
Here, I will just replace the comma with, let's say, a special delimiter.
I will just say underscore underscore underscore ___ - so this is basically a string, not a character.
name___price___quantity___unit of measure___provider
tomato___1.5___2___kg___""
carrot___3___5___kg___
cabbage___1.2___10___kg___grocery store
beetroot___5___1___kg___supermarket
In this case, I will go back to the test and I will just copy paste the test that we had initially so that we don't have to write it again.
I will name this one csvFileSource_StringDoubleIntStringStringSpecifiedDelimiter.
I will just use one file as an input in this case, not two - so just the file with number 3 at the end of the name.
What I will also do here is that I will say that the delimiterString is "___".
Sometimes our files have a character as a separator, so in that case, we can use the delimiter attribute and specify that delimiter - for example, ;, if that is what we have - but we cannot use delimiterString and delimiter at the same time for the same file.
So let's just go with delimiterString for now, and I will run this test.
@ParameterizedTest
@CsvFileSource(files = "src/test/resources/params/shoppinglist3.csv",
numLinesToSkip = 1, delimiterString = "___")
void csvFileSource_StringDoubleIntStringStringSpecifiedDelimiter(String name, double price,
int qty, String uom,
String provider) {
System.out.println("name = " + name + ", price = " + price +
", qty = " + qty + ", uom = " + uom + ", provider = " + provider);
}
And we will now see that we are reading the values correctly from the input file - namely, the product that we had in that file.
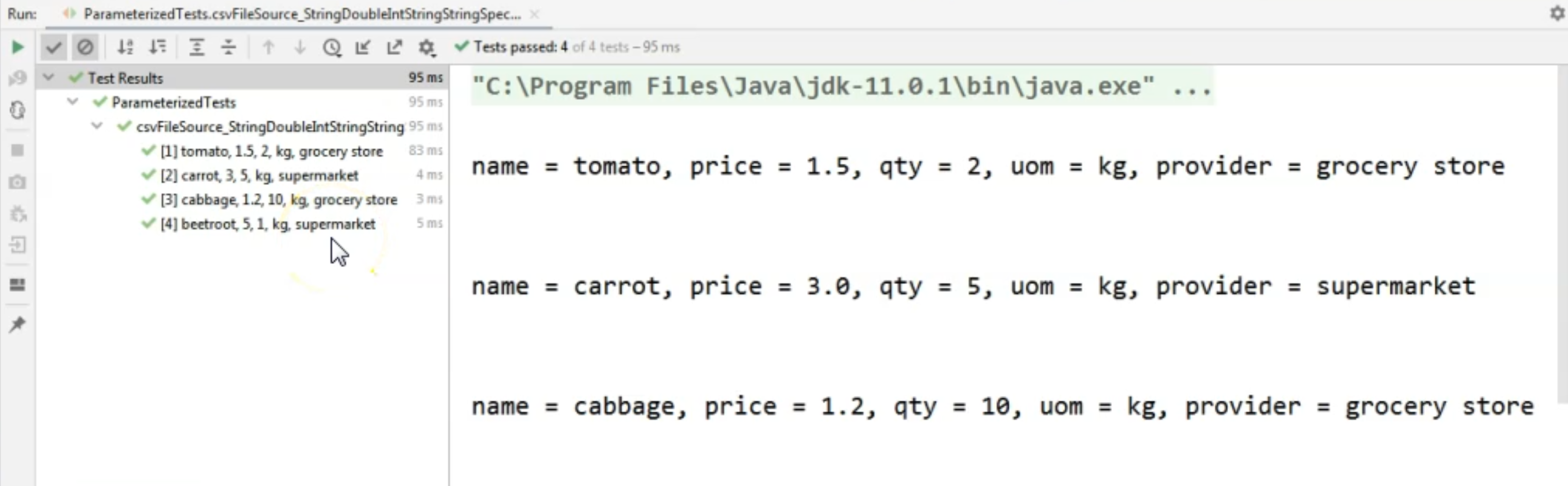
Now, one quick thing to mention regarding strings - if we have string values in the files and we want those values to be an empty string or a null value...
Let's go back to the third file that we have here.
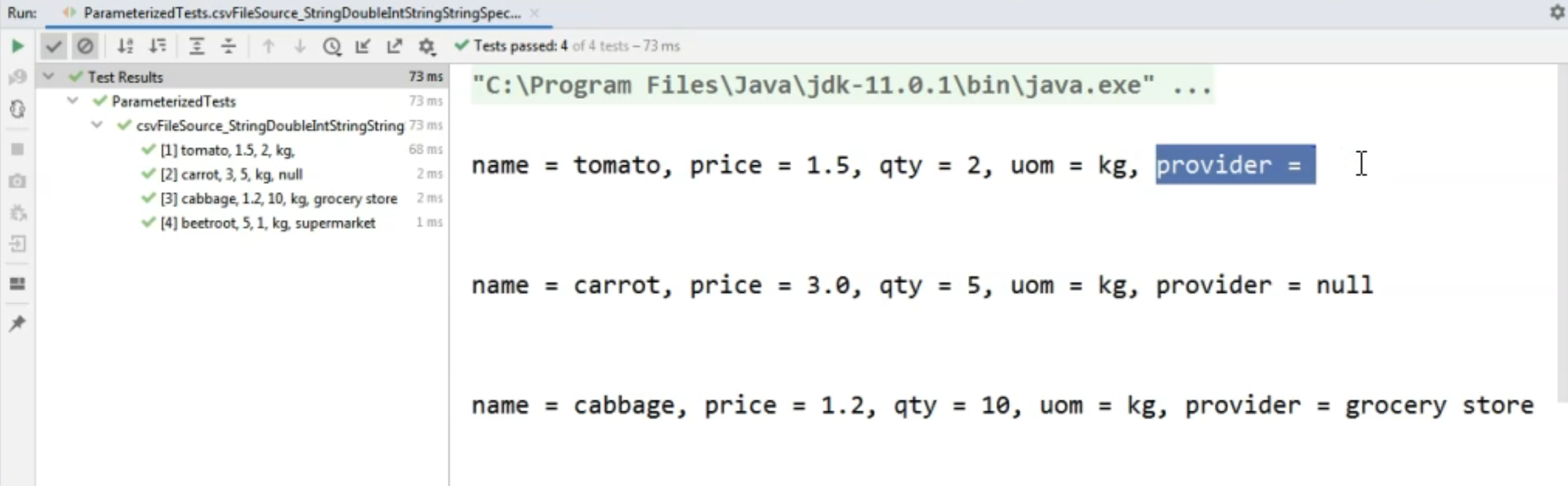
So if we want to specify an empty string, we will need to put it between double quotes.
If we want to pass in, instead of a string, a null value, we will just leave it empty.
So empty value for a string parameter means null and double quotes with nothing between them is an empty string.
Now running the test again, let's see the output of the test and we will see that, for the first line where we specify the double quotes, the provider is indeed an empty string, whereas for the line where the string was not specified at all, we have a null value.
So this is how the @CsvFileSource annotation works and it's very useful when we have our data stored in CSV files that we're either getting from somewhere or that get generated by some other code and are just passed to us as test inputs.
