

Transcripted Summary
What better way to start than to introduce you to machine learning and demystify it a bit?

Remember, as I said, machine learning is a deep and vast field. This is apparent by just looking at the different types, techniques, and problems in the space.

There are regression and clustering problems; learning types like supervised versus unsupervised, versus reinforcement…
Or even semi and self-supervised; training techniques like transfer learning and ensemble learning. versus federated learning…
And even bigger buckets that you're probably more familiar with, like Natural Language Processing and Computer Vision…
The list goes on and on.
Instead of going deep into these, which would be more data science and ML engineering anyway, we're going to look at these from a tester's perspective.
We don't need to know all these details to test things effectively, but we should understand the core concepts of AI and describe the process of training ML models. This is because as a tester, seeing what it takes to train a model will give you a lot of ideas of where risks are, how biases are introduced, and why good testers are highly sought after on ML teams.
# So, my first question: Is machine learning, actually artificial intelligence?
People seem to interchange ML and AI all the time. Most people think of AI as a machine thinking and behaving like a human.
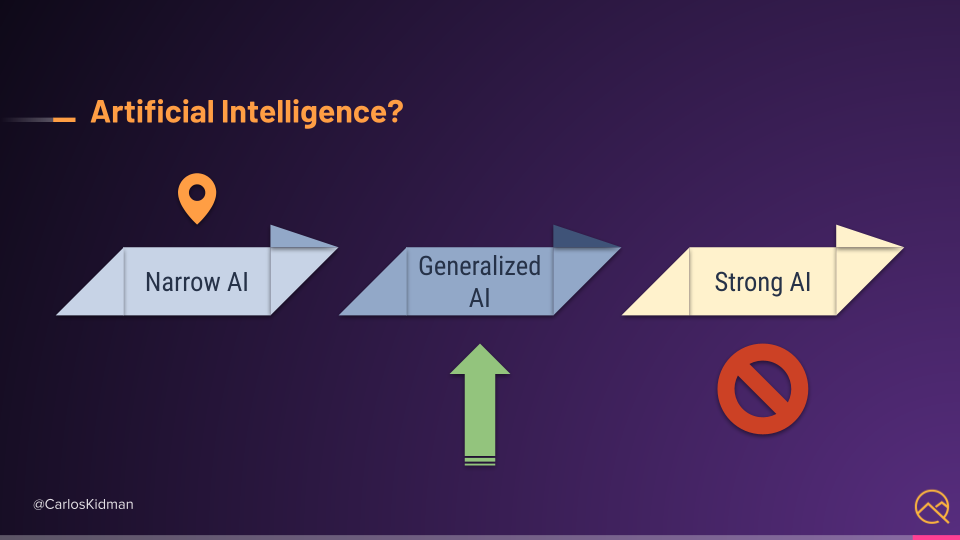
With that definition, which is also called Strong AI, I would say no. ML is not Strong AI.
Instead, we have Narrow AI, which is also known as Weak AI. It's narrow because we train ML models to solve a specific or narrow problem.
But even that's getting better with things like multitask models, where one model can solve many problems (Generalized AI), but I digress.
Even with narrow AI, I would still consider things like language translations, recommendations, and other ML applications as fairly intelligent, but that's just my opinion.
# Predicton with Machine Learning
To help demystify machine learning even further, let's take one of the many ML applications and break it down.
The most common ML application is prediction.

JLMR (Journal of Machine Learning Research) defined prediction as "predicting values based on patterns in other existing values."
The key part here is patterns in other existing values. I will use an oversimplified example to illustrate this.
Let's say we have this fresh produce store, and we want to predict how much we think people will spend.
We could do this for a lot of reasons, like making sure we don't under or overstock on certain items, especially perishables like fruit, vegetables, and milk. But let's keep it simple.
Let's say that the last 3 transactions at our store looked like this.

One person came in and spent $10. Then, a group of 2 people came in and spent $20. Then, a group of four came in and spent $40.
Knowing this, how much would you predict 3 people would spend? I bet you can guess the answer.
If you guessed $30, you're right.
You now understand the core concept behind how many ML applications work. You found the pattern, right?
You found a number that described the relationship between the number of people and the total amount they spent. By multiplying the number of people by 10, you could predict how much 3 people would spend given the existing data, even though we've never had a group of 3 people before now.
Does that mean that 3 people coming in into our store are guaranteed to spend only $30? Not at all.
They might spend $28 or $33, but that's one of the key differences between machine learning and traditional programming, and what makes testing these models a bit more spicy.
We're dealing with predictions and probabilities that aren't always meant to be 100% accurate, because well, how could we predict the future with 100% accuracy every time? Yeah, it's not going to happen.
# Differences Between Machine Learning and Traditional Programming
Let's visualize the difference between ML and traditional programming a tiny bit more.
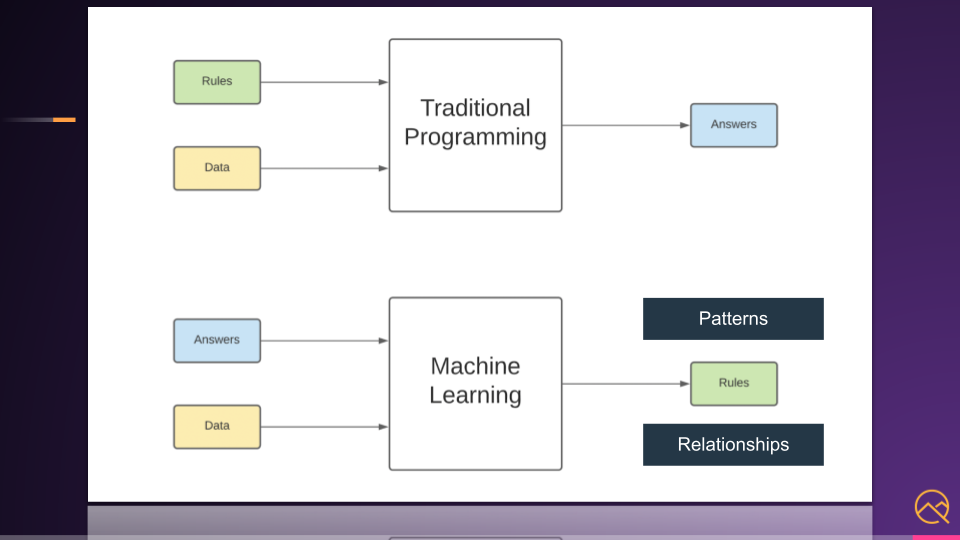
Traditional programming is where you provide the rules and data as inputs into a function or program, then it outputs the answers.
Machine learning takes the answers and data as inputs instead, then it outputs the rules, just like the patterns and relationships we just saw with prediction.
# Machine Learning Terminology
Before moving on, there is some terminology that we should cover really quick.
The left column of our supermarket example, which has values for the number of people, are called features. This is the data that our model will use to infer prediction.
The right column with the answers are called labels. These are the values associated with the values we'd like to predict.
This whole table is called a dataset.
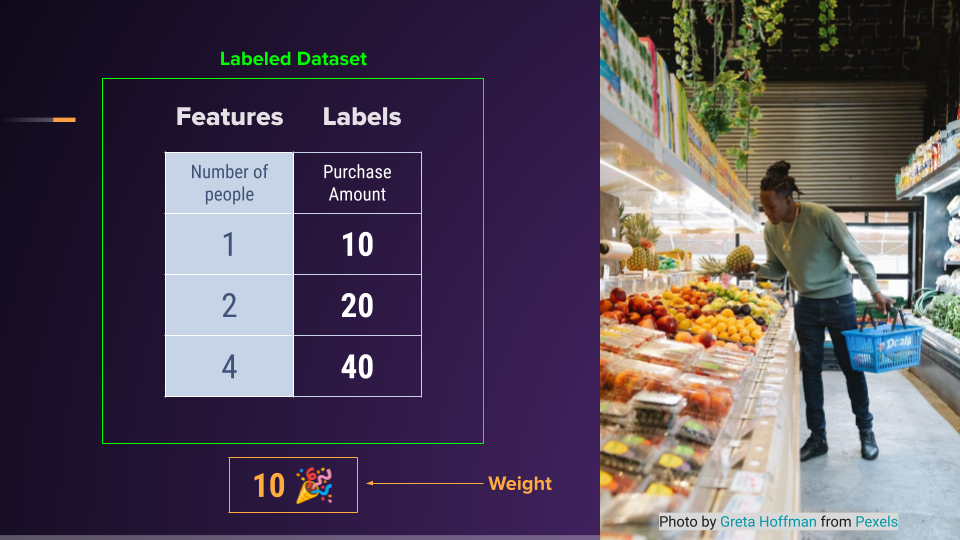
In this case, it's a labeled dataset because we have labels.
And lastly, this magic number of 10 that helped us describe the relationship is called a weight, or in some cases, a parameter.
So, once our model is trained and deployed, the input would be a dataset with a feature or features that is fed into the model.
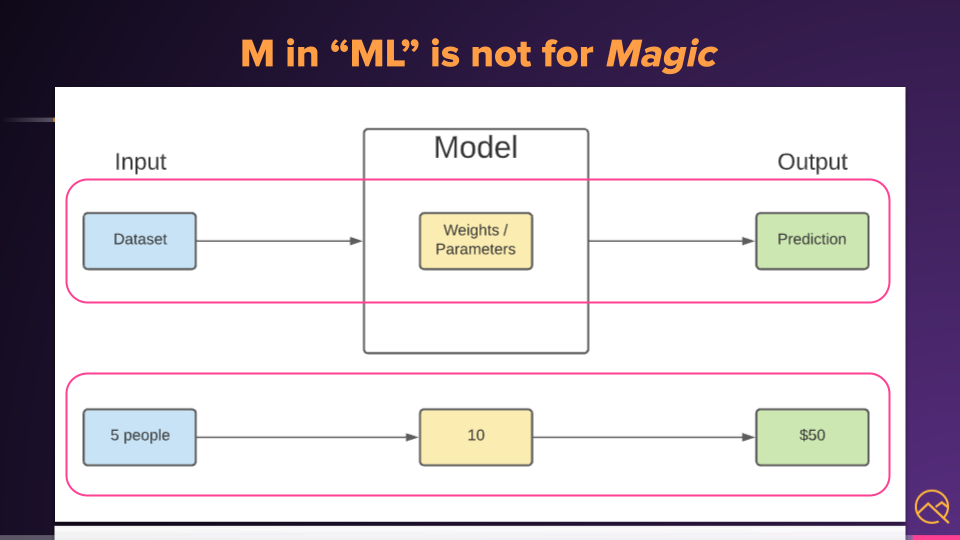
The model uses the weights it has learned against the data, and then infers an output.
In our example, this was a prediction. If we asked our model to predict for 5 people, it would multiply that by the weight, which is 10, and output a prediction, which is $50.
As you can see, machine learning is not magic.
In the next chapter, we'll go over an example of how models are trained. This will be good to see because there is a lot of exploration, analysis, experimentation, and testing that is done before and during training especially around the data. I want you to get an idea of what that looks like.
