

Transcripted Summary
Let's test with an example review the model has never seen before.
Now, remember, if the prediction is equal to or greater than 0, it's “positive”. If the prediction is less than 0, it's “negative”.
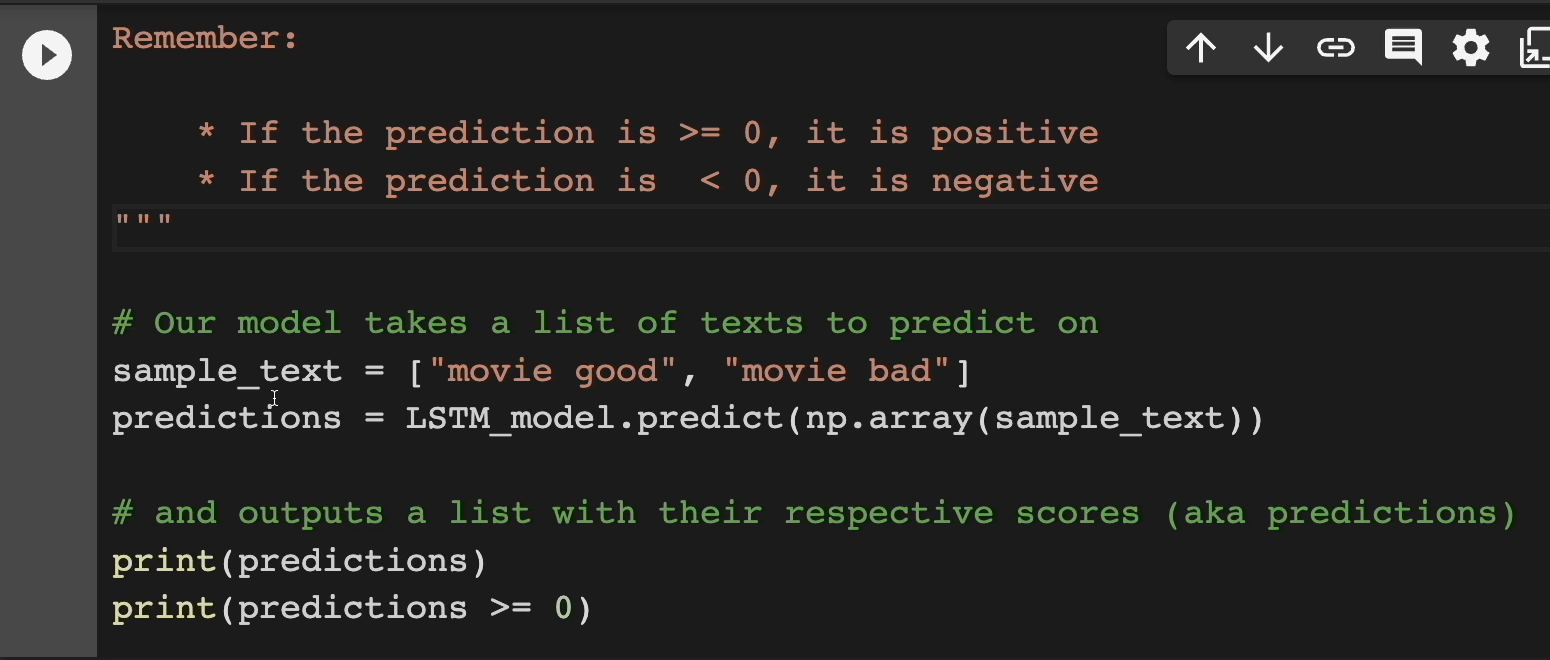
Our model takes a list of text to predict on.
In this case, the sample_text is a list. We have "movie good" and "movie bad."
We use the model.predict function, pass in a np.array with that “sample_text”, and then we get an output that shows us these predictions or their respective scores.
Let's run this cell here.
It looks like the first one, which is “movie good” was positive at 42% and “movie bad” was negative at 76.
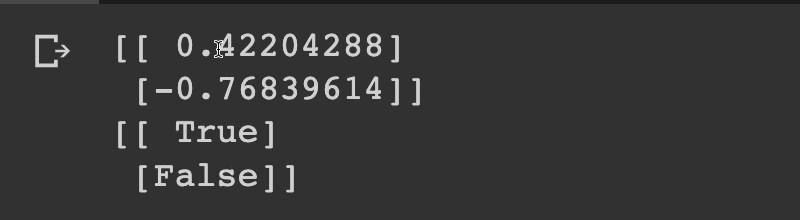
That's what this “True” and “False” is talking about. Positive, negative.
So, let's specify a capability, attribute, or behavior, and then define the test that will provide the evidence.
Here we have a table where we have our text example.
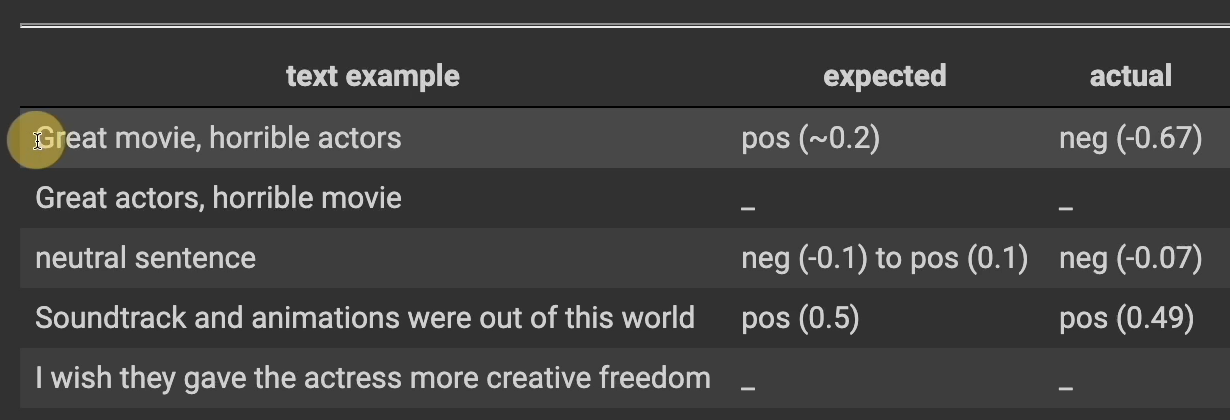
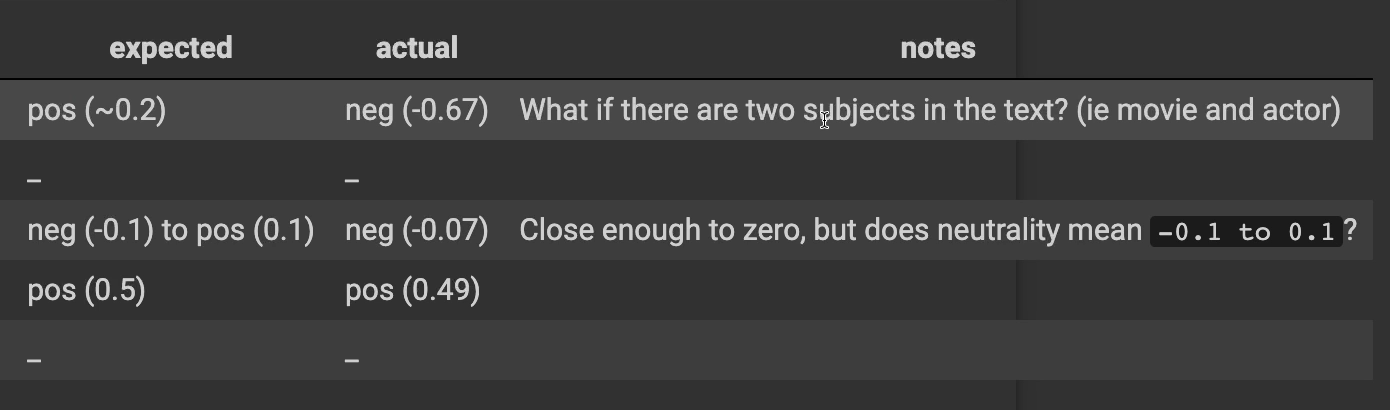
The first one here is, "Great movie, horrible actors." I expect this to be positive at around 20%. But when I ran a test, I actually got negative at 67%.
So immediately, I was like, "Wait a second. What if there are two subjects in the text?” We have a movie in here and an actor. The movie was great, but the actor was terrible.
Is that something we need to consider in our design?" That's why I took a note, and I'm going to be asking this question.
What if we flipped these around, “Great actors, horrible movie”? What would you expect that to be? We'll have a way here soon to actually see what this gives us.
There's a neutral sentence that is literally just "neutral sentence." I would expect it to be negative or positive within 10% either way. And sure enough, we got negative at 7%.
It's close enough to 0, but does neutrality mean that it's within this range? Do we need a different class? Right now, we only have positive and negative. Should we have a neutral class as well? Another question we should ask.
How about this example here? "The soundtrack animations were out of this world." I expected this to be positive at around 50%, and my actual was 49%. I was really close.
Here's another sentence, "I wish they gave the actress more creative freedom." What would you expect that to be?
These are super valuable and should be shared with your team and collaborated on.
Let's try some of them with a simple program around our model.
Here's our LSTM model again, and we're just going to write a very simple Python script to let us try out different inputs.
So, click "play" here and then predict a sentiment for, let's do our, "Great actors, horrible movie." And press enter.

It looks like it's almost neutral. This is only negative by 8%.
You can keep running this and trying different things out.
Let's try one of these. For example, "I wish they gave the actress more creative freedom."
Let's give that one a try and see who we get. Paste that in there, press enter.

This one was positive at 4%, so still pretty neutral as well.
Feel free to keep trying different examples to see how our model will do with the different inputs you give it.
All right, on to behavioral testing.
We can apply a lot of the same types of testing that we are familiar with from software testing and engineering.
You can do unit testing, risk analysis, look at heuristics, test behaviors, all that good stuff. We can always apply these things to machine learning.
Like I said, we were going to go over these in more depth.
# Minimum Functionality Tests (MFT)
The first one is minimum functionality tests.
This is mainly to test functionality and correctness. These are the things that must be true for the model to be considered good enough to progress.
For example, we may expect the following sentence to always be positive and within the 30 to 70% range. "The soundtrack and animations were out this world."
Let's take some examples that would be these MFTs.
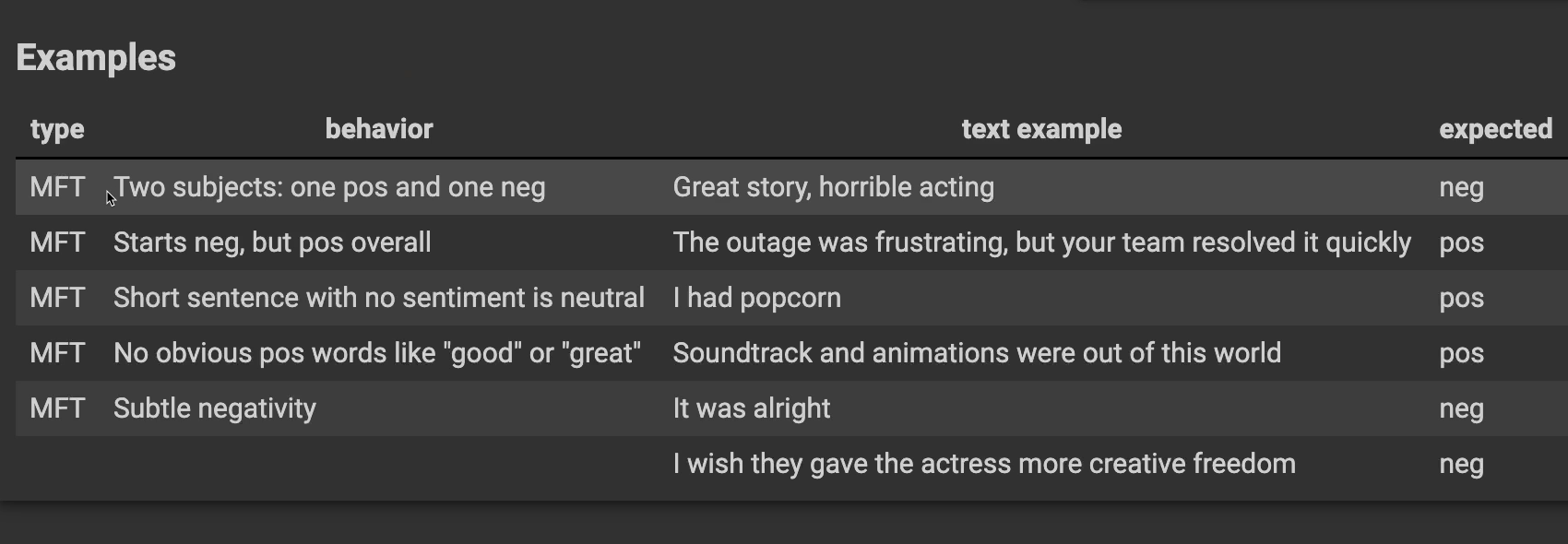
The first behavior, 2 subjects, one positive and one negative with, "Great story, horrible acting."
After discussing with my team, they said, "You know what? That is expected to be negative." But I still left my note here just in case. Because it still feels weird to me, I'm going to advocate for maybe making a change here and breaking it up and doing 2 predictions maybe. It depends on what our problem statement is.
The next behavior starts negative, but positive overall. "The outage was frustrating, but your team resolved it quickly." I would expect this to be positive.
The next behavior, what about a short sentence with no sentiment? That should be neutral. "I had popcorn."
This shouldn't be positive or negative. But since we don't have a neutral class, we can say that we would expect this to be positive. The actual we got back was negative, almost 0. So, it's close to 0, but if neutral, should the model return positive? Should we have a neutral class? Again, it depends on what we're designing for.
The next one, no obvious positive words, like “good” or “great” — "The soundtrack and animations were out of this world." We would expect this to be positive, and sure enough, it was positive.
How about some subtle negativity? "It was alright." Maybe we expect this to be negative. How about, "I wish they gave the actors more creative freedom." Do we expect that to be negative as well?
You can go on and on with different examples of how you would want to test each one of these behaviors.
Designing these behaviors, coming up with these tied with that problem statement is what's going to help you make a more robust plan around how you're going to test these things.
# Automating Tests
Now, let's talk about automating tests.
Given this baseline, we can now compare any new model against this, to see how it compares. Eventually, as you get these questions answered, you and your team will define baselines and benchmarks, and ranges or boundaries for these expectations. This is where you can select which tests should be automated so they can quickly be executed against the new iterations of models.
If you remember, it is just a function, model.predict() so you can test it with any framework.
For example, pytest for Python. You know the input and the output. So, apply your assertions, and you're good to go.
Here is a pytest example of this to test positive sentiment without obvious words.
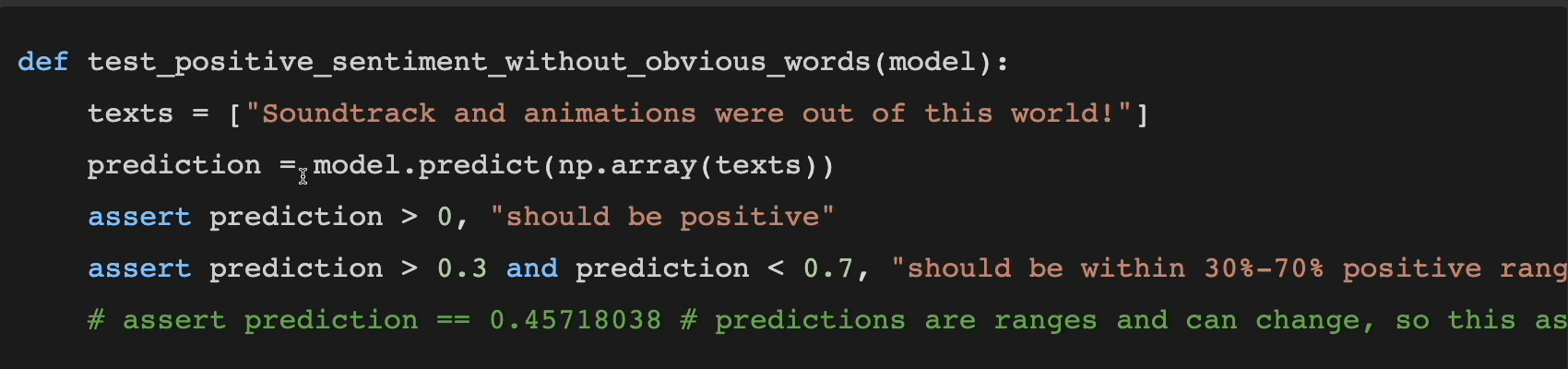
Here's our text, "Soundtrack and animations were out of this world."
Let's predict on these texts and we have 2 different options here. We can either say, "We just care that it's positive," or we can say, "We want it to be positive and within a range."
However, this last one here, this assert prediction is equal to this — “0.45718038” — well, predictions are ranges. They're these boundaries. They're probably going to change, so this assertion is probably going to fail a lot of the time for the wrong reasons.
These very strict assertions are not recommended.
>>>>> gd2md-html alert: Definition ↓↓ outside of definition list. Missing preceding term(s)?
(Back to top)(Next alert)
>>>>>
NOTE \
A quick warning here, the test functions are just examples in this notebook. Automated tests should not exist in your notebooks. They should be in your code project. That way, you can leverage testing frameworks like pytest. \
All right.
Here’s an automating test example here, you're going to go through these steps.
- You got to load the data. It may be hard coded. It might be from a CSV file or a database.
- You'll have some helper functions defined to make it easier to convert things, to report or test things.
- Then comes the test functions themselves with the assertions and failure rates.
Here is our hard coded data example.
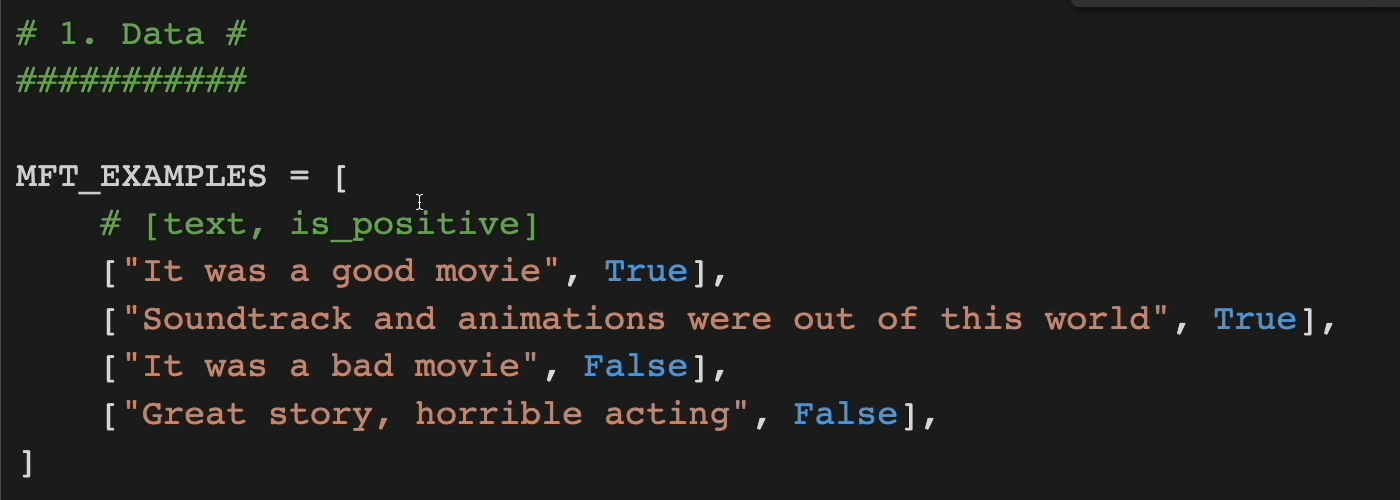
We have a list of minimum functionality tests, where the left-hand side is the text and the right-hand side is true if we want it to be positive, or false if we want it to be negative.
We have a simple helper function to let us know if the prediction was in fact positive or negative.

And then here is a test.
We can use a parameterize functionality from pytest to pass in our “MFT_EXAMPLES~.

This one single test will go through each test case and let us know, “Is that prediction positive or negative?”.
Are we getting what we expect?
# Failure Rates
Test frameworks have reporting capabilities built in that will report how many tests passed and how many failed.
Knowing how many examples our model classified incorrectly, at least through these tests, is called a failure rate and is a useful metric when comparing models. It’s good to know.
# Invariance Tests (INV)
Moving on, the next test we have is called the invariance.
This is where you want the same prediction after removing, adding, or editing words. In other words, changing a word for another word of the same sentiment should not change the classification.
Let's take this example. We have, "Soundtrack and animations were out of this world." If we replace the word "soundtrack" with "music," we should get the same positive sentiment.
Here's some examples.
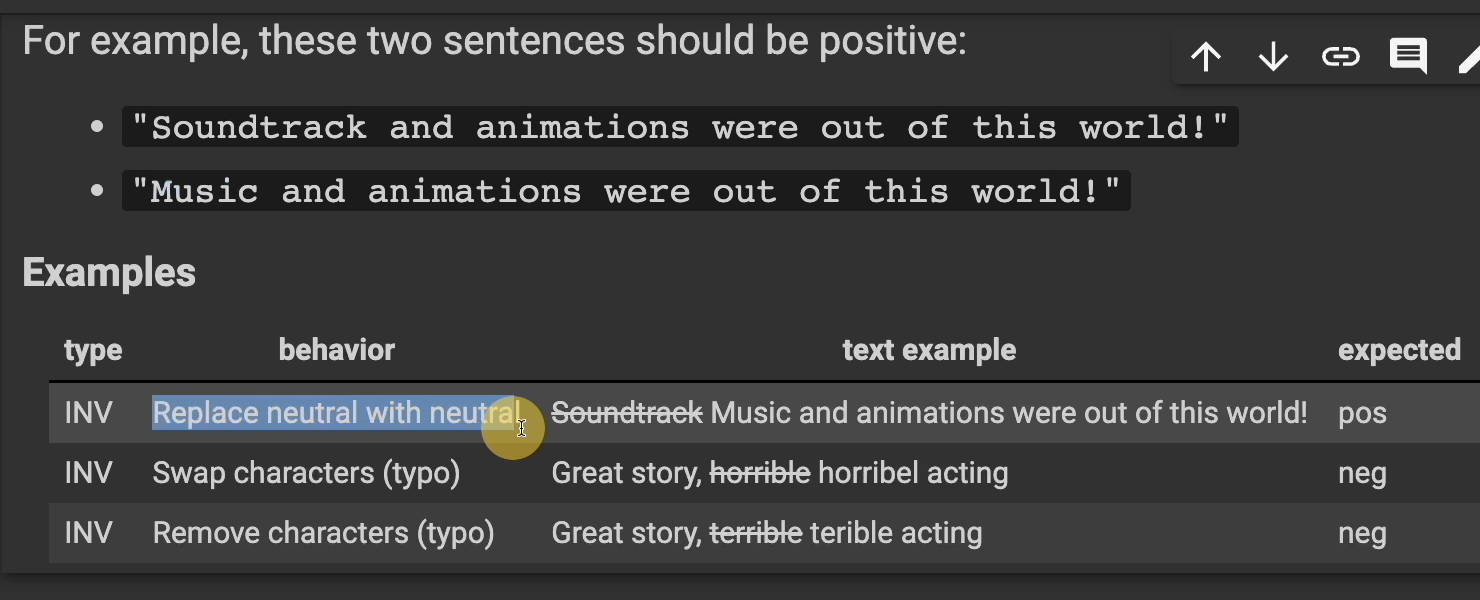
Our first behavior is “Replace neutral with neutral”. So replace "soundtrack" with "music." We expect this to still be positive.
Here's another behavior. If we swap characters, like a typo, "Great story, horribel acting," we will still expect this to be negative.
What if we removed characters, another form of typo, "Great story, terible acting.”? We would still want this to be negative.
All right. So, here's some tests for it.
We have some examples here.

Remember the left-hand side is the text, the right-hand side is “is it positive or negative?”.
And then the same exact looking test function. Pass in our examples, and is the prediction positive or negative?
# Directional Expectation Tests (DIR, aka DET)
The third type were the directional expectation tests.
This is where the sentiment should decrease or increase as expected. In other words, adding a word to the sentence should move the sentiment in the expected direction, given its weight.
For example, this sentence — "Soundtrack and animations were out of this world." — gives us about 50% positivity. What if we added some extra positive sentiment, "Soundtrack and animations were amazing and out of this world."?
Well, it should be a little bit more positive, right?
What about, "Soundtrack and animations were out of this world in all of the worst ways."? I wouldn't expect this to be more positive. I would expect this to move in the negative direction.
But how far in the negative direction? Should this no longer be a positive review? Should it be negative, around negative 30%?
What do you think?
Okay, with that said, it's your turn.
Try out some invariance and directional examples using the cell in the Colab Notebook.
You can also train another model with 2 LSTM layers by running the cells in the rest of the notebook. Feel free to explore and experiment. I recommend you do so.
This cell right here is similar to the one we had above.
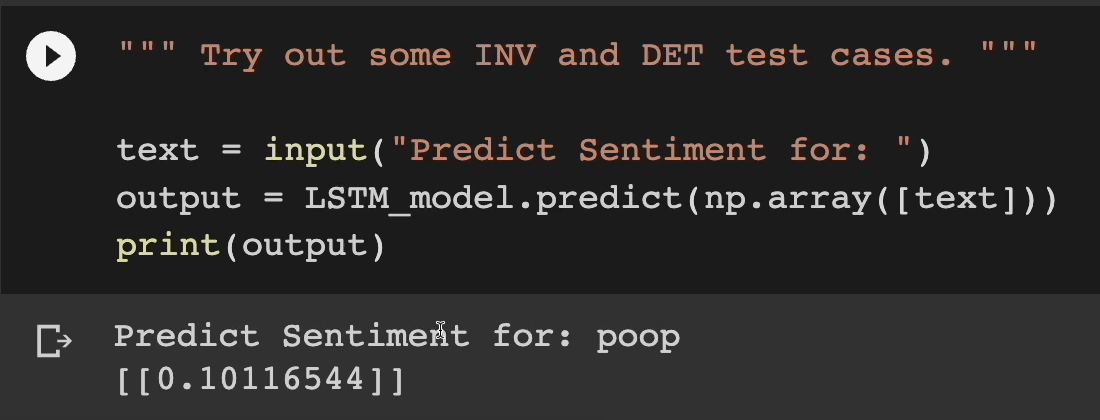
You can type in anything in here, like "poop," if you wanted. And we can see what we get back.
Sure enough, we get "poop" is 10% positive. Who would've thought?
Try out some more and see if you can get the model to classify incorrectly.
With that, you've now seen the 3 different techniques, examples of how to do so, and even some code examples that you can use if you'd like to automate these tests passed just the exploratory bit of it.
In the next video, I want to go over AI Fairness because, in testing fairness, we're actually going to be using some of these techniques to help us test for that as well.
Once you're ready, I'll see you in the next video.
