

Transcripted Summary
This chapter is called Fair and Responsible AI, but what does that even mean?

To be honest, this chapter could be an entire course by itself, but I do think it's important enough to at least touch on in this introductory course.
As you've seen these, ML models are entirely dependent on the data they're being trained and evaluated on.
If there is a bias or skew in the data, the model will learn that bias and amplify it.
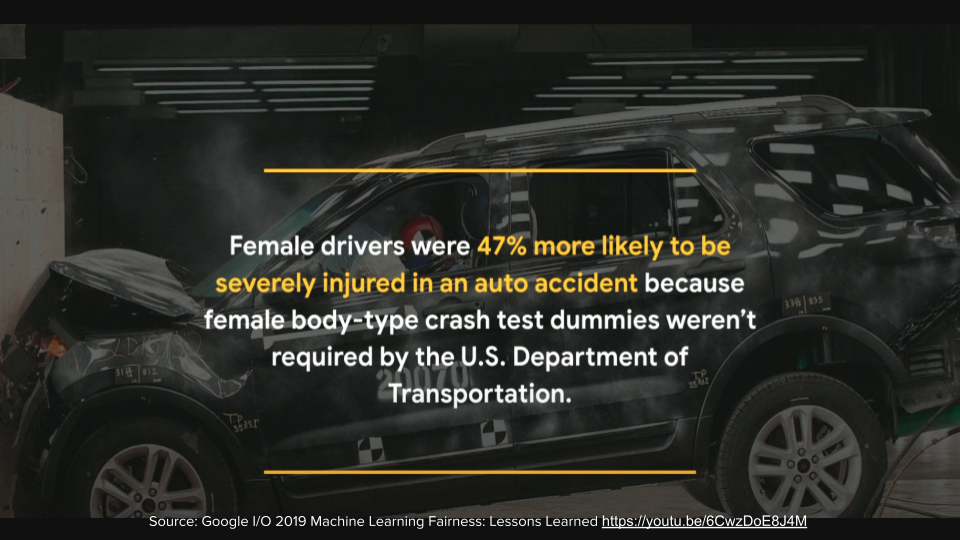
For example, female drivers were 47% more likely to be severely injured in an auto accident because female body-type crash test dummies weren't required by the US Department of Transportation.
Now, I don't think any data scientists or ML engineers are looking to build harmful ML systems, but we all have biases and we all have blind spots.
And not all biases are bad.
What makes a bias unfair or harmful and how can we identify and solve for them?

Let's start by looking at 5 biases that were nicely explained in this paper with actual examples and resources that were provided from this free Kaggle University course.
# Historical Bias
The first is historical bias. Historical bias occurs when the state of the world in which the data was generated is flawed.

For example, training a model and hiring decisions from the year 2000 is likely to amplify stereotypes and old or poor practices from that time.
As someone, without a university degree, I'm sure this model would've filtered me out.
# Representation Bias
Representation bias occurs when building data sets for training a model, if those data sets poorly represent the people that the model will serve.

For example, data collected through smartphone apps will underrepresent groups that are less likely to own smartphones. For instance, if collecting data in the USA, individuals over the age of 65 will be underrepresented.
If the data is used to inform design of a city transportation system, this will be disastrous since older people have important needs to ensure that the system is accessible.
# Measurement Bias
Measurement bias occurs when the accuracy of the data varies across groups.
For example, your local hospital uses a model to identify high-risk patients before they develop serious conditions, based on information like past diagnosis, medications, and demographic data.

The model uses this information to predict healthcare costs. The idea being that patients with higher costs likely correspond to high-risk patients.
Despite the fact that the model specifically excludes race, it seems to demonstrate racial discrimination. The algorithm is less likely to select eligible black patients. How can this be the case?
It is because cost was used as a proxy for risk. And the relationship between these variables varies with race. Black patients experience increased barriers to care, have less trust in the healthcare system, and therefore have lower medical costs on average, when compared to non-black patients with the same health conditions.
# Aggregation Bias
Aggregation bias occurs when groups are inappropriately resulting in a model that does not perform well for any group or only does well for the majority group.

For example, Hispanics have higher rates of diabetes and diabetes related complications then non-Hispanic whites.
If building AI to diagnose or monitor diabetes, it is important to make the system sensitive to these ethnic differences by either including ethnicity as a feature in the data or building separate models for different ethnic groups.
# Evaluation Bias
Evaluation bias occurs when evaluating a model, if the benchmark data, which is used to compare the model to other models that perform similar tasks does not represent the popular that the model will serve.

For example, the Gender Shades paper discovered that 2 widely used facial analysis benchmark data sets were primarily composed of lighter skin subjects.
Commercial gender classification AI showed state-of-the-art performance on these benchmarks but experienced disproportionately high error rates with people of color.
# Deployment Bias
Deployment bias occurs when the problem the model is intended to solve is different from the way it's actually used.
If the end users don't use the model the way it's supposed to be used, there is no guarantee that the model will perform well.

For example, the criminal justice system uses tools to predict the likelihood that a convicted criminal will relapse into criminal behavior. The predictions are not designed for judges when deciding appropriate punishments at the time of sentencing.
# Where Can Biases Occur?
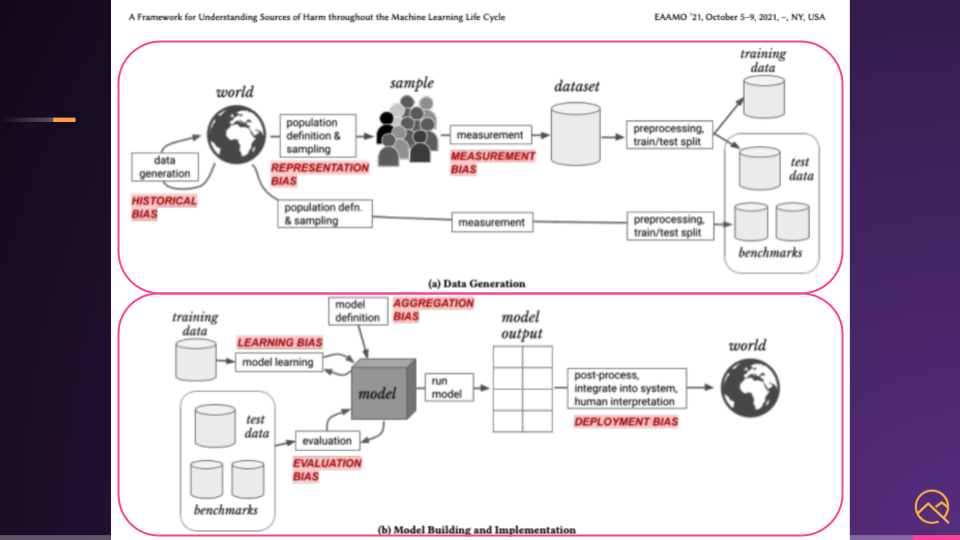
The paper then goes to show different places where the biases can happen in a typical ML workflow — from data collection and preparation, to training and evaluation, and into deployment.
Look at all that red.
Designing and testing for fairness is super important.
Now, Google has great YouTube videos, but also has resources on this topic at URLs like these.
They're not the only ones of course.
Let's go over some of the ways they've shared that we can design and test for fairness, diversity, and inclusivity.
# Fairness by Data
The first is fairness by data.
Models are trained and evaluated on data, so it must be diverse and inclusive.

Build training and eval datasets that represent all the nuances of your target. The validation and testing data sets are just as important as the training data.
Reflect on who or what your target might leave out.
- What are the blind spots and biases in your data?
- Do you even have a way to identify them?
How will your data grow and change over time?
Your data does change over time. And if you don't have a handle on that data drift, then you'll eventually introduce a historical bias, right? Reminds me of that Zillow problem.
# Fairness by Measurement and Modeling
Next is fairness by measurement and modeling.
Just because you have a perfectly balanced dataset doesn't mean your model systems' output will be perfectly fair. It's also difficult to look at a large amount of data and identify problems in it.
This is where having people like data engineers and data analysts are super helpful in making sure we have high quality data and high quality models.

So, test early and test often. Sounds like continuous testing to me, which is something we do in software testing and engineering. You should apply the same ideas and concepts here.
Develop multiple metrics for measuring the scale of each problem. Monitoring and observability come to mind, but measuring helps your testing and quality, especially as things change over time.
Take proactive steps in modeling that are aware of production constraints.
Let's take a look at the example that Google provided at the Google IO Conference presentation called Machine Learning Fairness: Lessons Learned.
This was one of the results from a model back in 2017, that was meant to identify toxicity online.
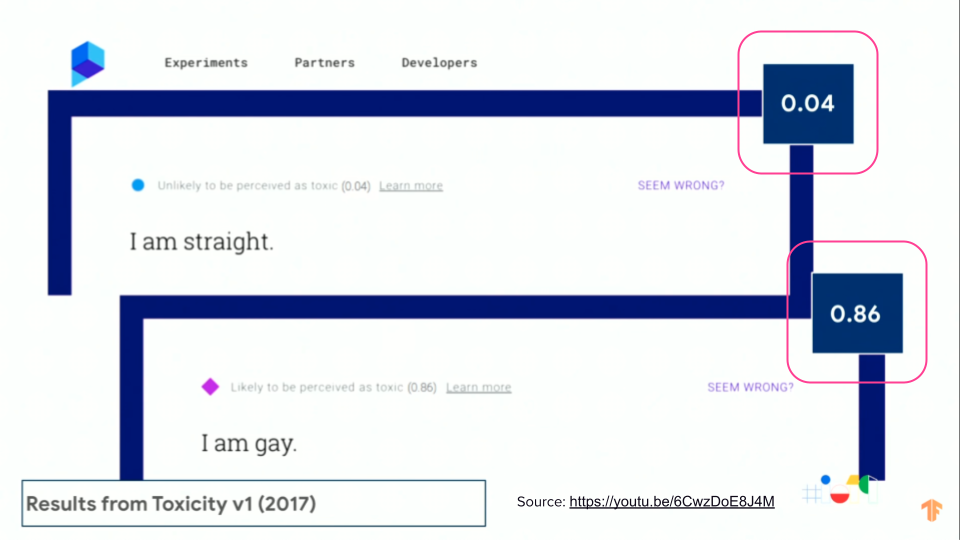
The model saw the phrase “I am straight” as 4% toxic, where the phrase “I am gay” was predicted to be 86% toxic, which is a huge difference and a harmful bias.
This leads us to representational harm. These are when a model showcases an offensive stereotype or harmful association.
This was the representation bias we discussed earlier from that Kaggle University course.
Look at their question — “How would the prediction change if the identity token discussed in the example were something else?”.

This is an exact use case for invariance testing, which we discussed in the behavioral testing chapter before.
Notice how only changing a single word drastically impacts the score.
So, you can use the behavioral testing techniques we learned to help you test for fairness and catch these harmful behaviors.
Disproportional performance is when the model works great for one group, but not as well for another.
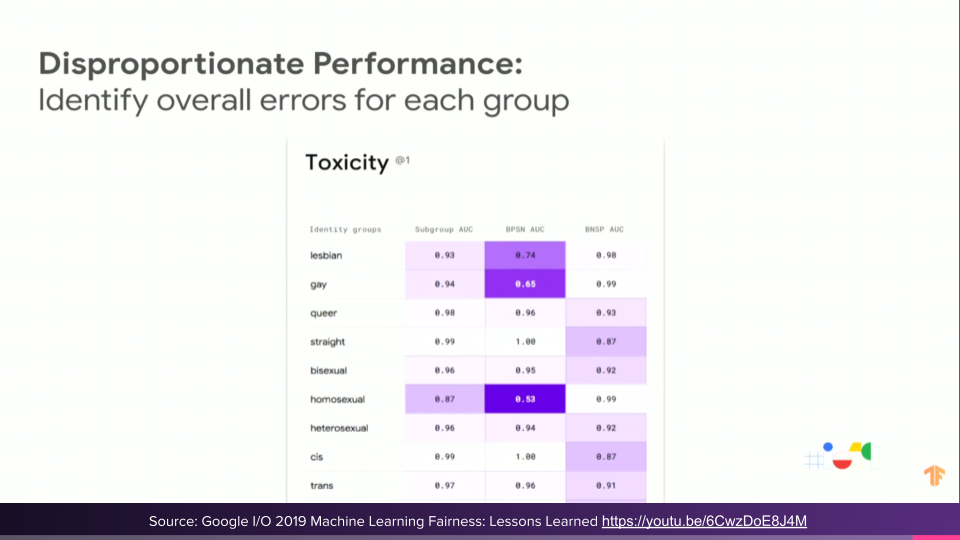
This was the measurement bias.
You can collect and measure your test results to compare models, but also see how subsets or groups of people are affected. It's common in testing to define funnels or personas to change the way we test and approach a system or application.
Again, you can apply the same ideas and concepts in machine learning and AI. In this table, the darker numbers show poor performance from the model.
# Fairness by Design
And lastly, we have fairness by design. The usability and experience the user has with a product goes beyond the performance of the model system.

Context is key. Without context, it's difficult for the model to predict the right thing. We'll see an example soon.
Ensure feedback from diverse users. Even if you feel that you have perfectly tested the system, there is still more feedback and learning to be had. Make sure you have processes and tools in place to collect this feedback. Don't just rely on bug reports.
Identify ways to enable multiple experiences. Forcing everyone to go through a single AI driven experience may be harmful. For example, self-driving cars have a mode for the driver to be in control.
Zillow, on the other hand, had their AI do all the buying and decision making.
Google Translate had an issue with this.
Turkish doesn't have gender in their vocabulary, where languages like my Spanish do.
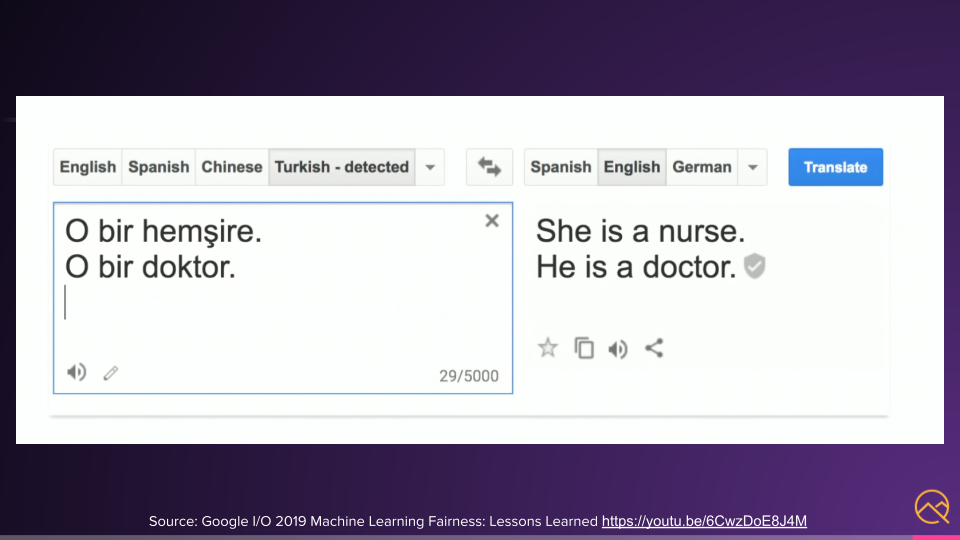
However, when translated to English, the model skewed woman for nurse and man for doctor showing a clear bias.
In this example below, how do we know if Casey is male, female, or non-binary?
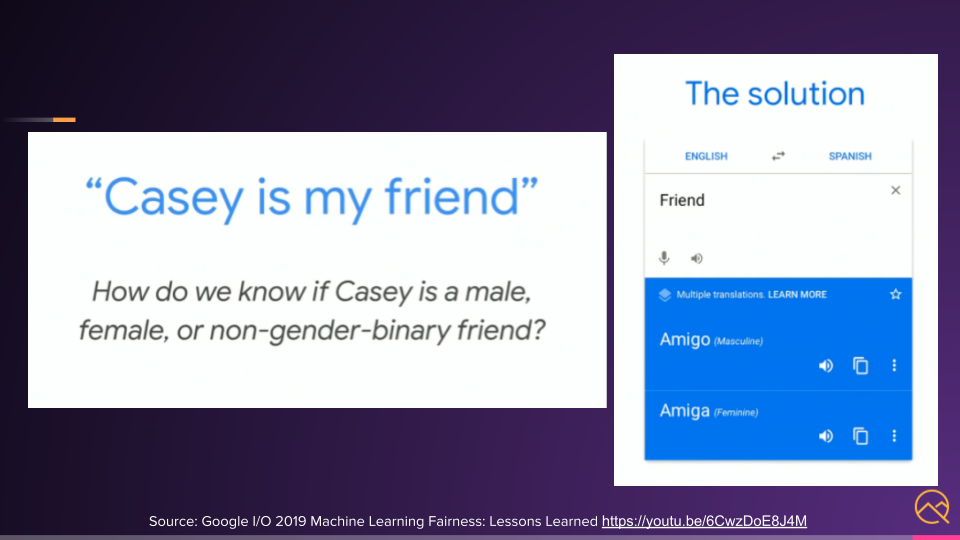
We don't have that context. So even a high-quality model would be wrong.
Instead, we should design our product in a way that fills in the context of those gaps. For example, we can show the user different results and they can select the answer that fits their context. Fairness by design.
I have included links to all the videos and resources you've seen throughout this chapter in the resources.
I highly recommend you take some time to watch and go through them. We need testers just like you to help design and build fair, ethical, and responsible AI for the good of everyone.
Resources
A Framework for Understanding Sources of Harm throughout the Machine Learning Life Cycle
Machine Learning Fairness: Lessons Learned (TensorFlow video)
