

Transcripted Summary
In the previous chapter, we used a Computer Vision model to demonstrate different adversarial attacking techniques.

In this chapter, we will use a Natural Language Processing model, or NLP, to demonstrate different behavioral testing techniques.
We're going to take the concepts explained in the Beyond Accuracy paper written in 2020, by Marco Tulio Ribeiro, et al, where they discussed designing checklists of test cases to test different behaviors and capabilities of the models past just the accuracy and loss metrics during modeling.

They discovered that defining the desired behaviors and capabilities, and writing tests for them during design and throughout modeling, made for better performing models.
They also learned that testing behaviors gave a more accurate picture of model performance.
They even have some user studies as evidence. For example, one team using this approach created twice as many tests and found almost 3 times as many bugs.
Here's one of the examples provided in the paper.
They defined 3 major linguistic capabilities the model should have: vocabulary, name entity recognition, and negation.

Then they used different types of tests and created test cases to see how the model performed against these capabilities.
This is a table of test cases with the input, the expected versus the actual output, and whether it passed or failed.
But wait, testing behaviors, example mapping, writing test cases, risk storming, exploratory design, defining baselines, capturing test metrics and app performance and all that and this, sounds super are familiar, right?
It should because that's exactly the kinds of things that we do as testers already.
Just like MLOps was inspired by DevOps, behavioral testing in the ML world was inspired by software testing and engineering.
# Types of Behavioral Testing
We'll go over 3 testing types they cover since they come from professional linguists and data scientists. And I'm sure we can learn something from it.

These are Minimum Functionality Tests (MFT) and Invariance Tests (INV) and Directional Expectation Tests (DET), which is also sometimes called DIR for “direction”. But don't worry, we'll use examples to dive deeper into each one real soon.
With all these different tests, it becomes much easier for us to measure and compare iterations of models, or even completely different models, to see which are better.
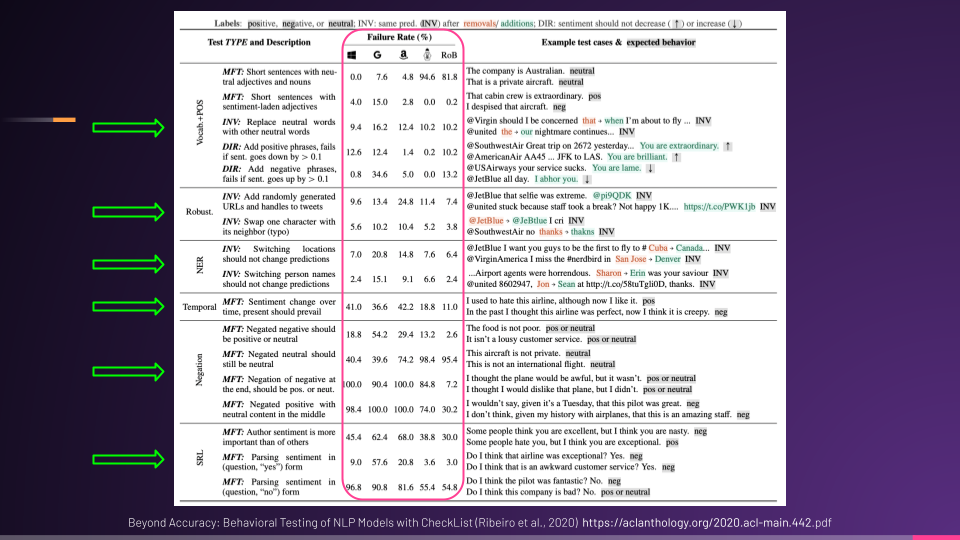
Each capability is put into a section with different types of tests against it. And then we can see the failure rates of different models as they go through these tests.
In this case, we have a model from Microsoft, Google, and Amazon, and also a BERT and RoBERTa model.
I'm sure these open-source models had great initial training and validation numbers, but using behavioral testing, we can see just how well these models perform against the behaviors and capabilities we need for our problem and solution.
Okay, let's switch over to the Colab Notebook. The link is in the resources.
In this notebook, we're going to explore an NLP model that will perform Sentiment Analysis on IMDB movie reviews and apply behavioral testing techniques.
You can think of sentiment analysis as this: given a sentence, is it positive or negative?
We are going to be training a bigger model in this case, and so to show some of the capability of Colab, let's set up the notebook real quick.
We're going to change the Runtime to a GPU.
We do this by clicking on Runtime, go down here to Change Runtime Type.
Next, click on GPU, then Save.
All right, you're ready to go.
This first cell is going to load everything, all the functions, that we need for this. We're going to be using Tensor Flow again. And there's a lot of functions in here.
You don't have to know what they're all doing right now, so let's move on.
The first step here is collecting data.
Fortunately, the data has already been collected from IMDB and conveniently organized. But this is only true for the initial training. As more shows and movies come out and more reviews are added, we may want to retrain later with different data and/or more data.
Now, please note: this collection and re-collection will most likely be automated and is called a Data Pipeline.
You're going to hear that term quite a bit. And it can mean a lot of things. This usually consists of multiple pieces like services, transformations, and at least one database.
These pipelines are usually something you'll want to have tested since it's the lifeblood of your whole ML system.
For now, let's load the reviews and split it into a train and validation data set with this cell right here.
This may take a little bit of time. In my case, it took about one minute, but once it's done, let's move on.
Let's display the schema of the data, which is going to show the data that we're working with.
Each entry in the data set consists of the text, which is the review as a string, and the label, which is the sentiment value as an integer. In this case, zero is a negative review and one is a positive review.
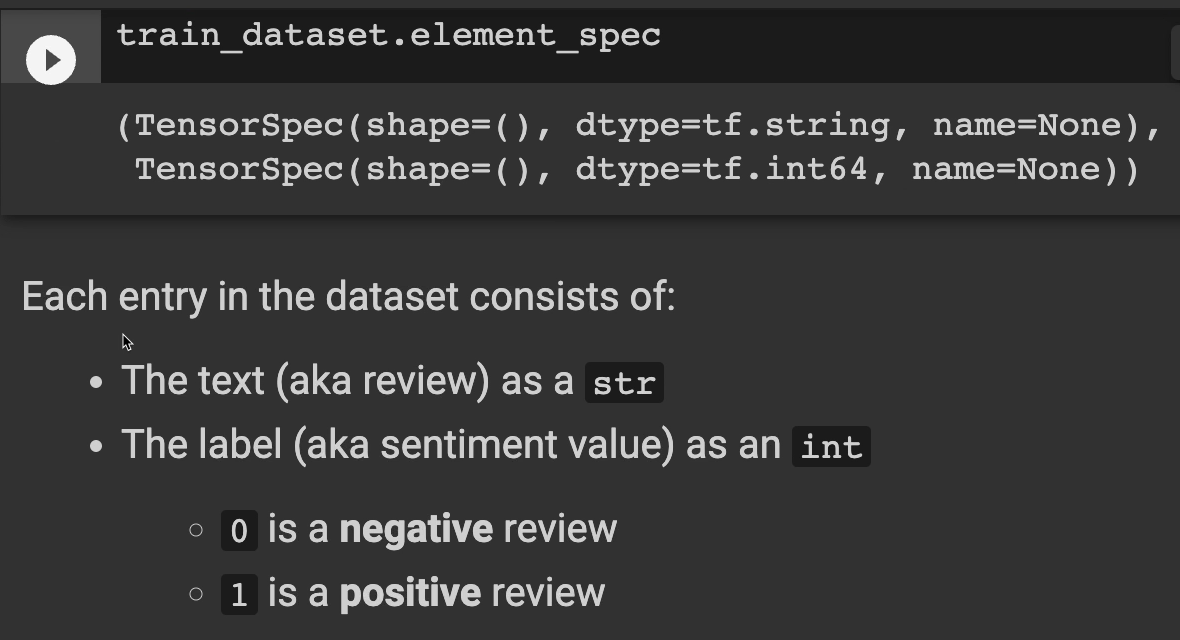
But let's take an actual entry here and let's see what it looks like.
Let's run this cell.
Here's a review: "This was an absolutely terrible movie. Don't be lured in by Christopher Walkin or Michael Ironside. Both are great actors, but this must simply be their worst role in history…"
And they go on to say other negative things.
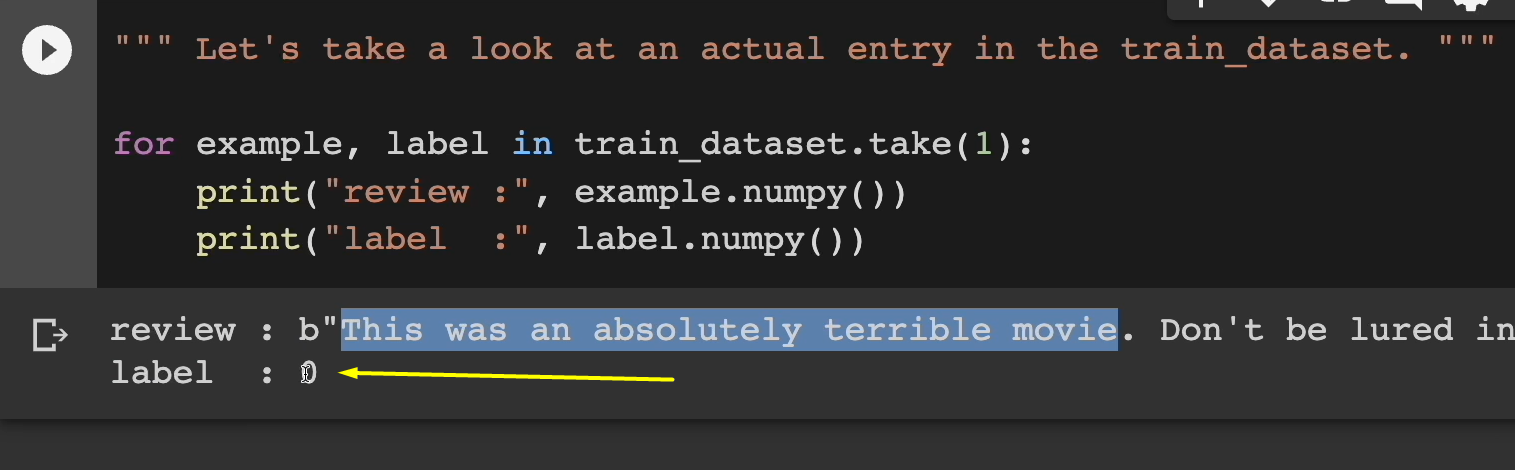
But as you can see, the label is appropriate here. It for sure is labeled as a “0” or negative review.
But let's pause for a second to make sure we understand sentiment.
What tells you that this is a positive or negative review?
This one right here. "Good movie." The word "good" has a positive sentiment, while movie has a neutral sentiment.
What about the next sentence here? "It's not a good movie." "Good" is positive, but "not" negates it. So, this is a negative review.
And what about this one? "This was a great movie." "Great" is more positive than "good" meaning that sentiment and the weights words have are a gradient, aka they fit on a spectrum that looks kind of like this.
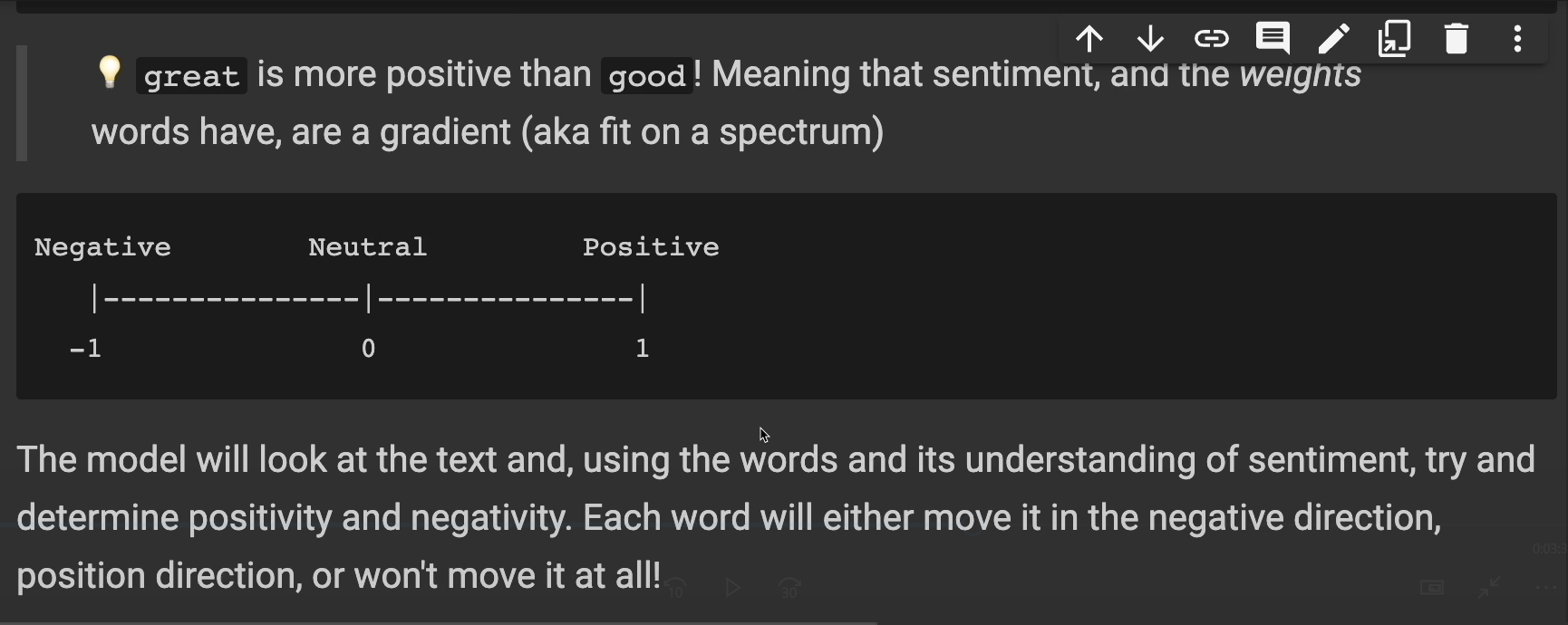
The model will look at the text and using the words and its understanding of sentiment try and determine positivity and negativity.
Each word will either move it in the negative direction or in the positive direction, or it may not move at all.
At the end, the model will output a score.
In our example, it's positive if the score is greater than or equal to 0. Otherwise, if the score is less than 0, the model is saying, "this is a negative review."
Next up, we've got to prepare the data.
In this case, since we're doing sentiment analysis, the model needs to have a vocabulary of words to learn.
There's a lot of methods here for doing all of this, but the whole thing is called preprocessing.
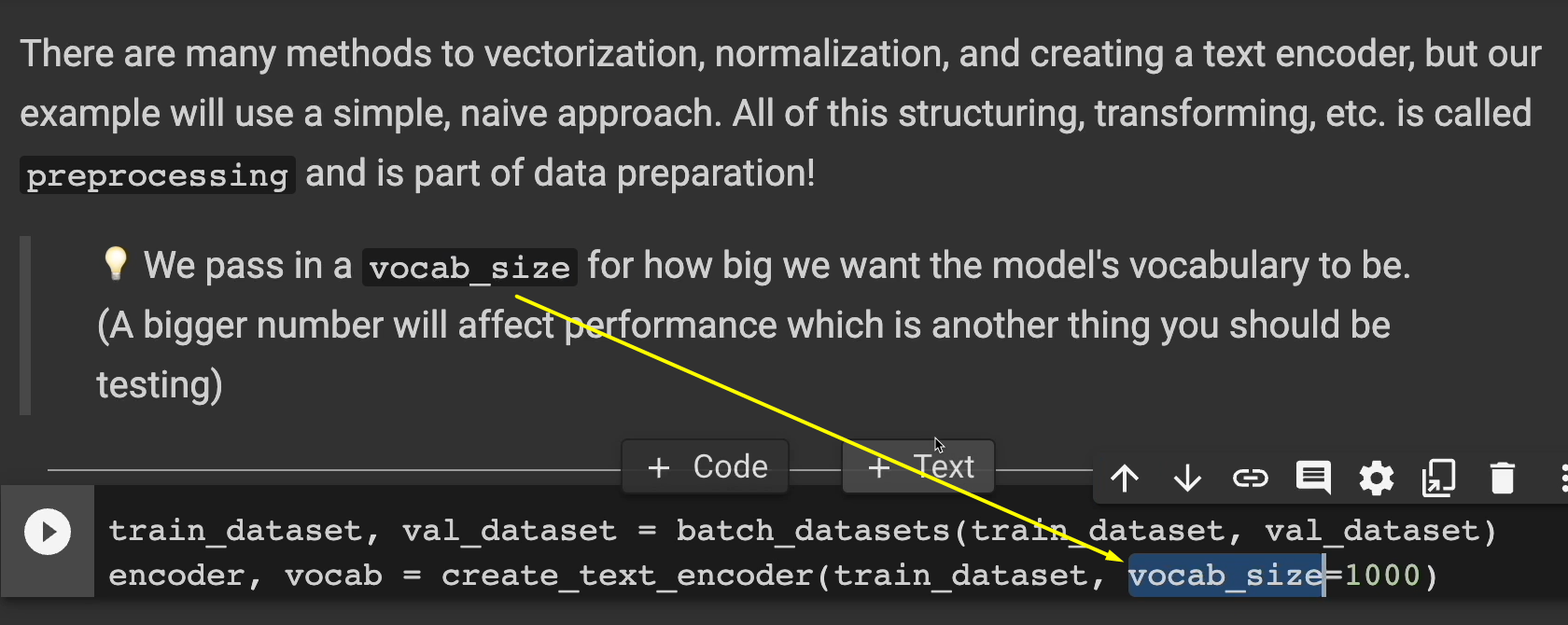
In our example, we're going to be passing in a vocab size right here of 1000.
That's how many words we want the model to know.
Let's run this cell here and let's see the first 20 words at the beginning and end of the vocabulary.
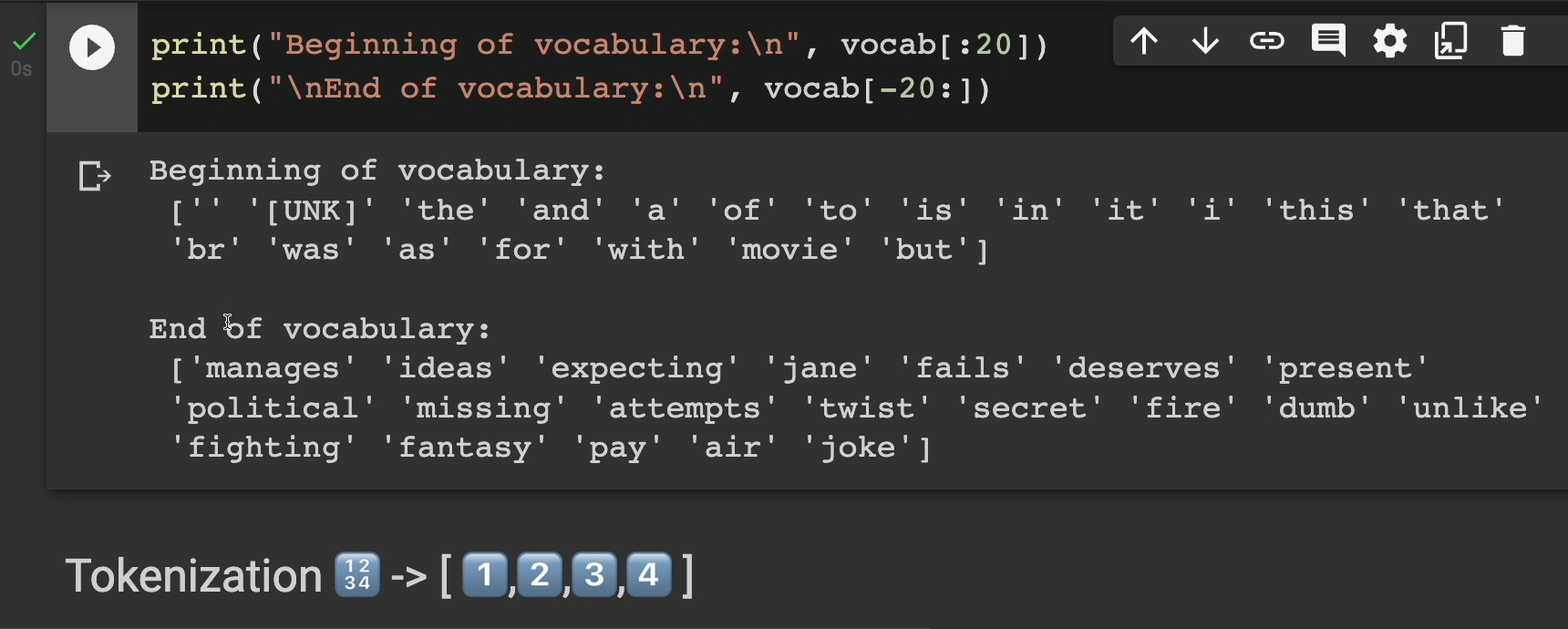
Starting out we have an empty space. We have this “[UNK]” looking thing. There's the word "the". We have "and" and "with".
There's “movie”, that's important.
We have “but”, "it", "this", "that". even a break for “br”.
At the end of the vocabulary, probably words that are a little more important, like "manages", "political", "fighting", "fantasy", "pay"… All these other ones as well.
Grabbing all of this and breaking it apart is what we call tokenization.
Our simple approach made all the words lowercase and removed all punctuation. Then it split each review into a list of words (aka tokens) and added them to the overall vocabulary.
>>>>> gd2md-html alert: Definition ↓↓ outside of definition list. Missing preceding term(s)?
(Back to top)(Next alert)
>>>>>
NOTE \
We have lots of filler words like “a”, “of”, and “as”. We could probably remove those filler words and it's usually recommended to do so, but that's out of the scope of this notebook. \
We also have this UNK token, which stands for “Unknown”.
This token is reserved for any token that the vocabulary or a model doesn't know. Remember, it can only hold 1000 tokens. Any token outside of those 1000 will be replaced with the UNK token. So, I doubt that our model has been trained with the word "indubitably," so "indubitably" is going to be converted to this UNK token.
With a little bit of that knowledge, let's go and train a model.
In this case, we're going to train a single LSTM layer model.

This is going to take a while because epoch is going to take 1 to 2 minutes to do. And we're only going to do it 5 times, so be ready for an almost 10-minute training cycle. I'm going to run it for now and fast-forward, so you don't have to watch.
All right, about 11 minutes later, it finally finished. Let's scroll down here and let's see our results.
Our accuracy started about 57% and ended around 85%. The validation though, said that it ended around 80%.
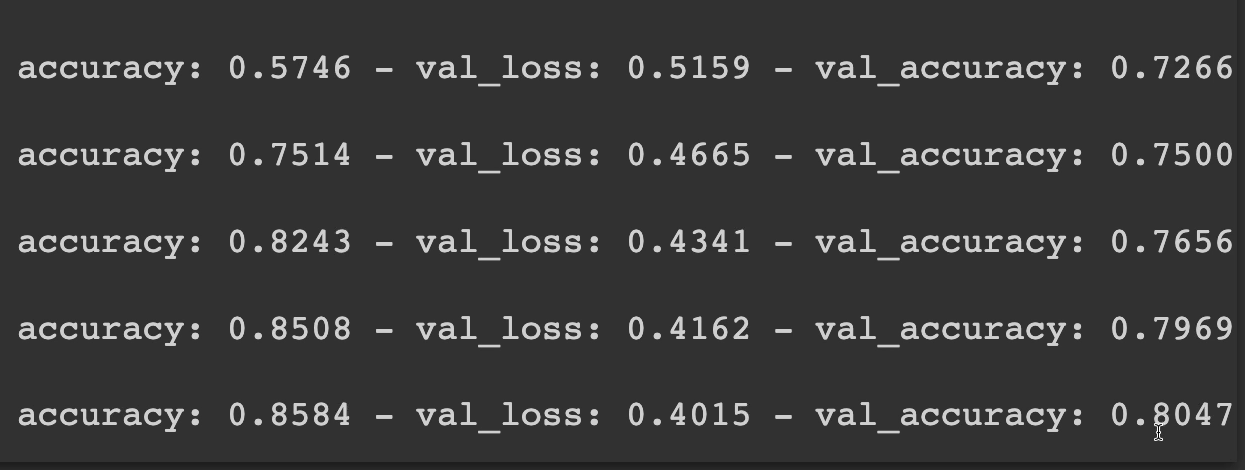
So at least our accuracy was improving, but 80% still isn't the best, but that's okay.
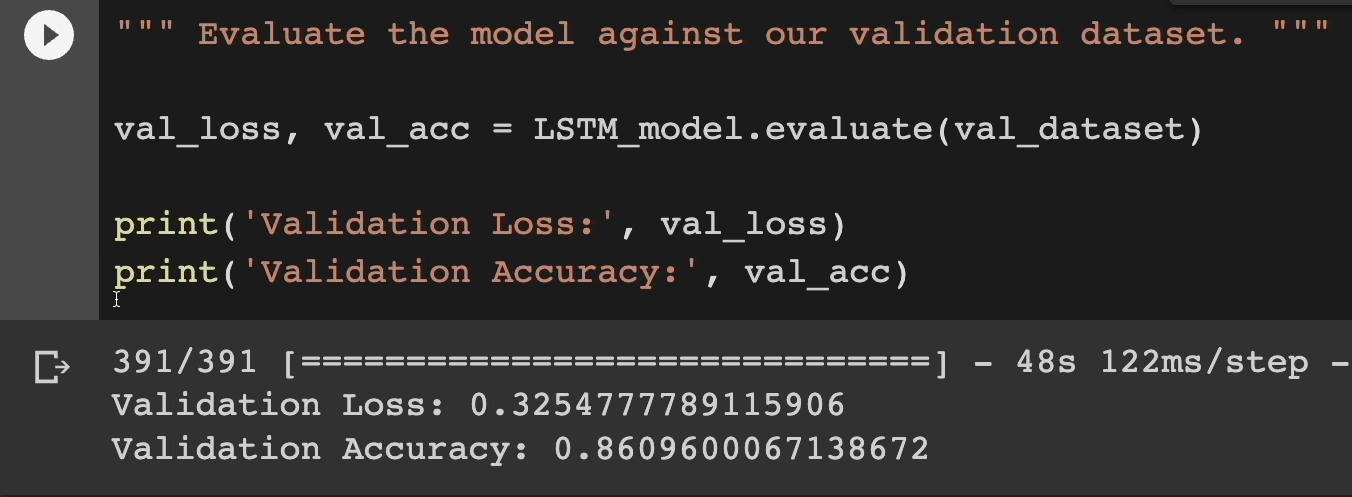
**Let's move on and evaluate our model. **
All right, it looks like against our validation dataset, we had a loss of 32 and an accuracy of 86.
Now we can plot this as well if you want to get a visualization of the history.
On the left-hand side, we can see the accuracy as it goes up and starts to plateau a little bit around 85 and the validation had a nice steady incline.
This right-hand side is the loss. We see the loss going down as it should. Same with the validation as well.
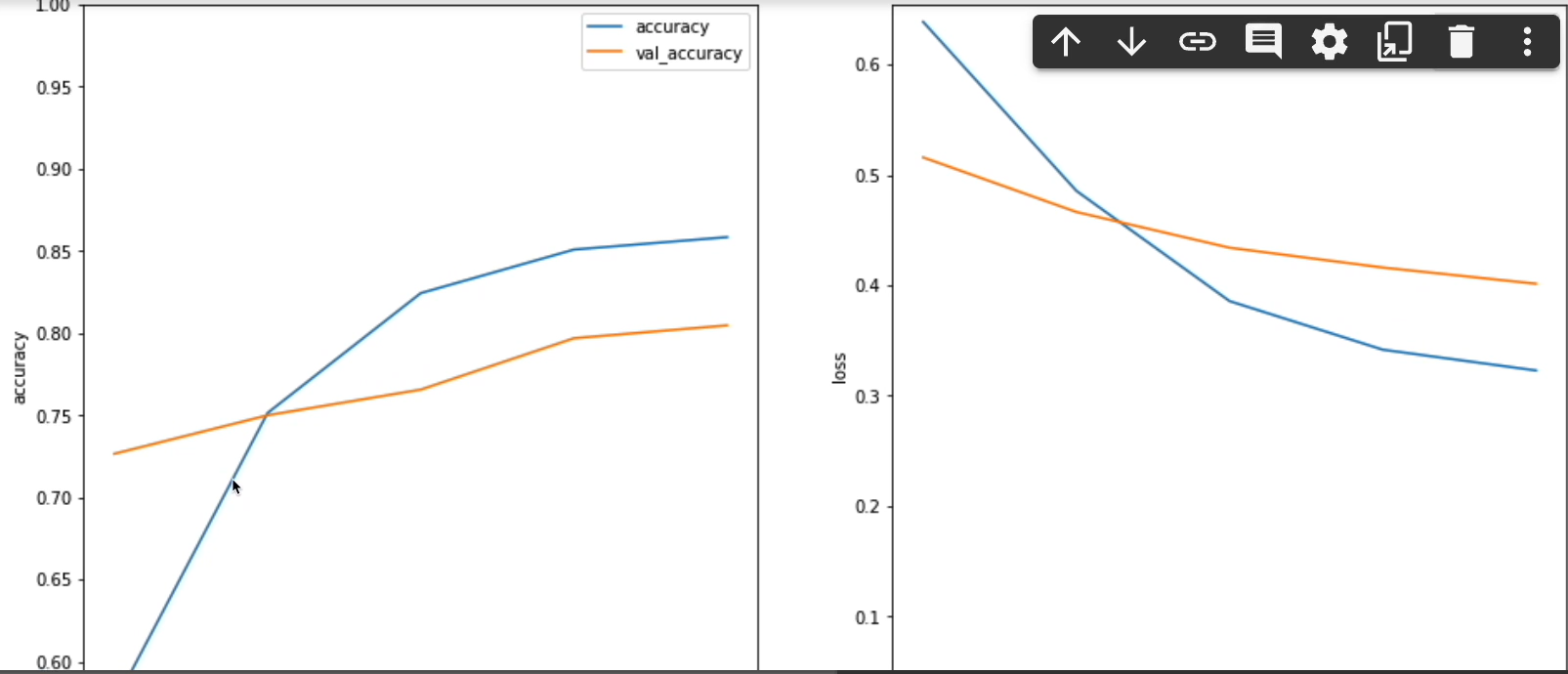
So, it definitely looks like there's room for improvement, but for now, let's get to testing the models.
Resources
Quiz
The quiz for this chapter can be found in Chapter 5.2.
