

Transcripted Summary
Now that you've seen a workflow for building a Machine Learning model and trained to model yourself, let's take a step back to ask the question where do testers fit in Machine Learning?

You saw a simple model for predicting house prices, but ML systems are already being used in a wide range of applications that you most likely experience every day.
You have assistance like Alexa, Google, and Siri.
Applications for images and video, including things like filters and optimization in your phone camera and apps.
Personalization for more targeted and curated experiences like Netflix’s recommendations.
Security for applications like fraud prevention and email spam detection.
Fields like agriculture and medicine are using Machine Learning more and more.

ML and AI are truly amazing and are making awesome strides forward in many areas. And that's exciting.
But each one of these is an entire product with multiple dependencies and integrations, not just the single model stuck in a Colab notebook. And each of these products and applications needs good testing.
But not everything is smiles and success.
ML and AI are difficult applications to design and implement. And it's rare that the product will have a single ML model.
Let's take a relatively recent example of an ML system that went terribly wrong.
Zillow is an online real estate company. They had a house flipping business where they would buy a property with the intention to resell it at a higher price and make that money.
In other words, the idea is to buy a property at a low price, resell it for higher, and make a profit.
With that technique in mind, they applied multiple models that worked together to automate this process.
At first, the models they trained had great training and validation numbers, high precision, low air rates, all that good stuff.
So, what happened?
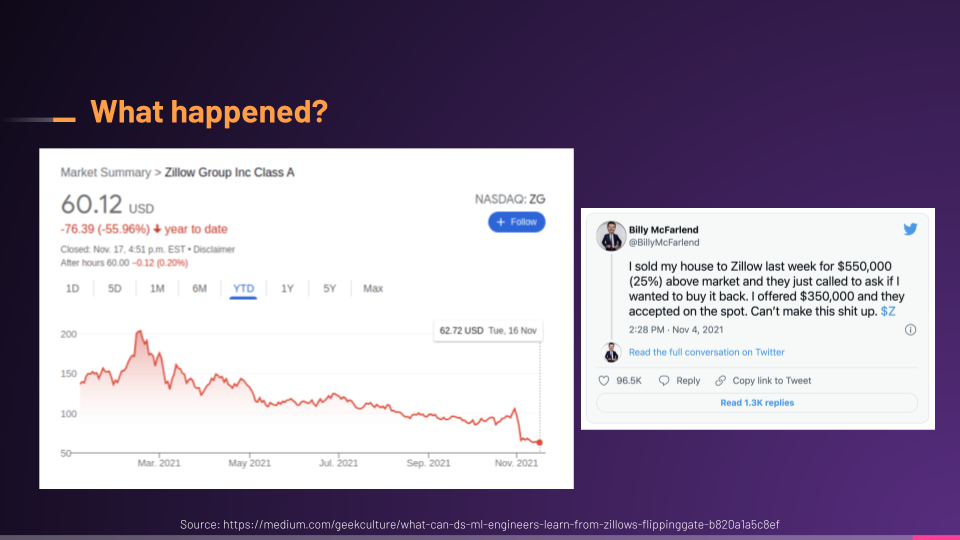
Well, the model's performance began to degrade over time, so much so that the ML system began buying properties at prices much higher than the market value, which is opposite of what we want in this formula.
I won't dive too much into the details since this article does a great job of that, but you can see that their flipping business flopped, and ended up costing them millions of dollars and cutting the workforce by 25%. No bueno.
At the end of the article, the author goes over 5 lessons learned that made this a low-quality ML system and overall solution.
I think these are valuable to think about as testers as well.

Right from the go, before training even, the data is already suspect because part of their data was shared by users and publicly available data sets.
That would make it easier to gain the system since a few users or properties could drive the prices of the predictions. If a few houses in the neighborhood are priced high enough, that would greatly affect the median and thus the output of the models.
But worse, the design of the ML system was flawed as well. Zillow was completely dependent on the models and would let the models buy houses automatically for them. Instead of using models to augment and assist the experts, they took their hands completely off the steering wheel and let AI buy everything.
Biases were introduced because the focus was entirely on the prices and predictions of the houses and excluded any perspective of the buyers. It's as if they removed the human aspect of flipping completely from the design.
To top it all off, external risks played a part in this as well. Things like COVID greatly affected the housing market. Also, since most of the system was automated, they were buying more houses than they were selling, which drove up other prices like renovation budgets much higher than anticipated.
Another lesson I took away from the story was that the models were performing well at first, but started to degrade as these events, risks, and data changed over time.
This leads nicely to the topic of MLOps.
Without continuous testing, measuring, and iterating, you get exactly the problem Zillow faced, a promising product that blows up and your face, enter MLOps.

Wikipedia defined it like this, a set of practices that aims to deploy and maintain ML models in production reliably and efficiently.
At first, I was like, great, another Ops buzzword, but after my research on MLOps, the idea's simple. Take the ideas and practices from DevOps and apply them to the ML and AI domain.
In other words, combine ML and DevOps together.
Doing so creates an infinity loop that looks like this, where you have the data side and the ML side, but software engineering, like infrastructure and automation, is the glue.
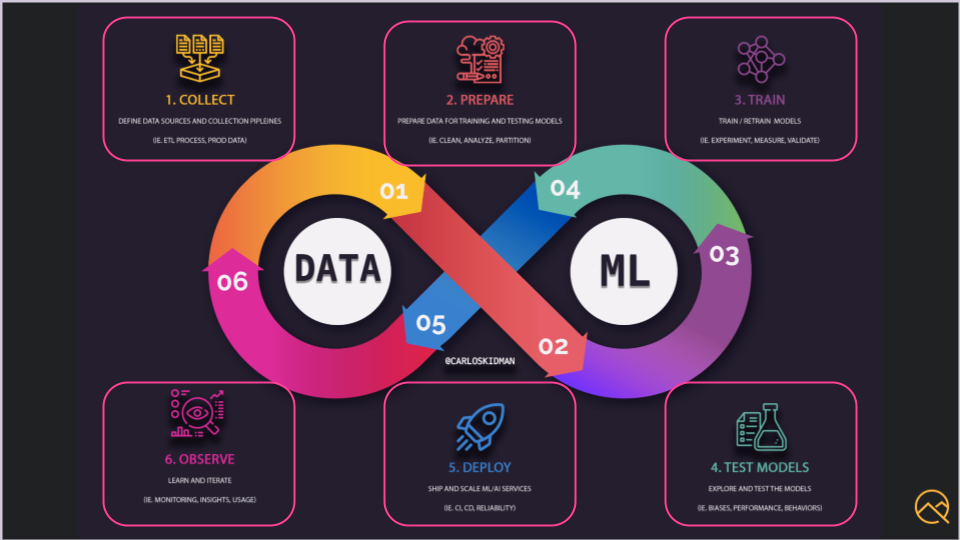
There are a lot of MLOps diagrams out there, but I condensed it down to 6 major phases and the life cycle that we touched on a bit in a previous chapter.
If you remember, we had to collect the data, then prepare the data, train the models, test those models, and deploy the ML system, and then observe. And we do this over and over.
So where does testing fit in MLOps? The answer? In every single phase.
You continue to hear me say ML system because the products or applications are very rarely a single Machine Learning model. No.
Instead, there are streams and funnels that collect data, cloud services that get and move data, scripts or jobs that transform and manipulate the data, training and retraining processes, tests, checks, benchmarks, and more, multiple models that help each other yield a better result, pipelines that test and deploy these models and services, feature flags, observability tools.
The list goes on.
The point is high-quality MLOps and DevOps, for that matter, requires good testing throughout.

In the next chapter, we'll dive into code again to see how we can test the resiliency of ML models, using a technique called adversarial attacks.
