Transcripted Summary
In this last chapter, I want to show a real model in production that's behind a web service.

My hope is that seeing an example of a finished model behind a REST API ties everything together.
To start, we need to understand checkpoints and saved models.
# Checkpoints
Checkpoints are like partial trainings of a model. They allow you to share learning parameters or gradients across models and continue training from where you left off.
Just like a checkpoint in a video game.
Instead of having to repeat the level each time, you can load from a checkpoint and continue the level with all the same abilities and items you had before.
In our last notebook, you saw how long it took to train a model with a relatively small data set.
Five Epochs took around 10 minutes. So, imagine if we wanted to train for 50 or more epics on an even larger data set.
Instead of having to wait for a single machine to train on the 50 epics, we could use a form of distributed training where we connect multiple machines and divvy out the data or training.
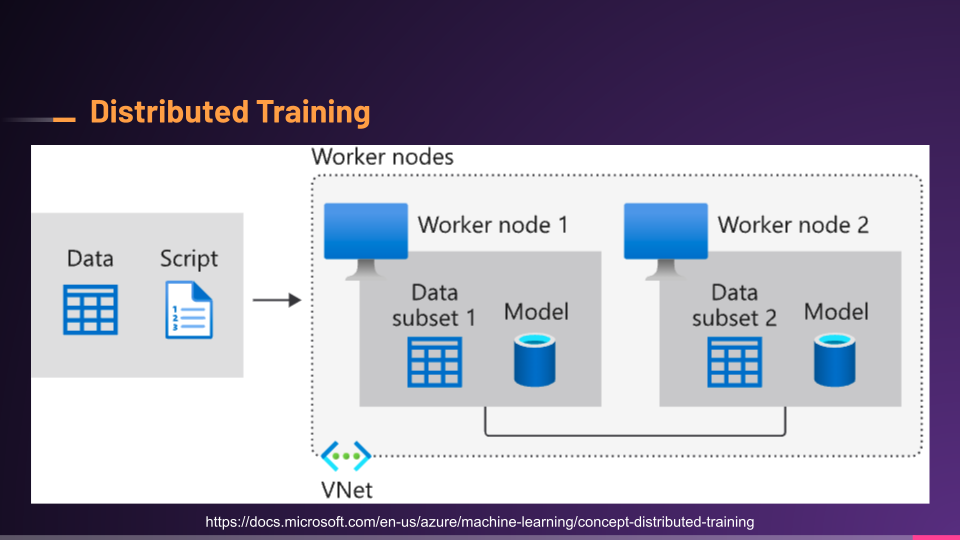
Each node would create a checkpoint with the parameters, weights, and gradients it learned and shared across the nodes, and eventually return all of that learning to the main machine.
Then you could continue training the model using all the gathered checkpoints from the smaller nodes or be ready for evaluation.
Checkpoints make this possible.
# Saved Models
Where checkpoints are like partial training files, saved models are entirely trained models and their architectures.

In other words, it's already trained and ready to be used.
However, you can either start using a saved model out of the box, or you can extend it and train more on top of it. We call this transfer learning. Companies like OpenAI and Hugging Face have saved models that are open source that you can use right now.
Let's visit Hugging Face's website to see an example. Let's browse through their models catalog.
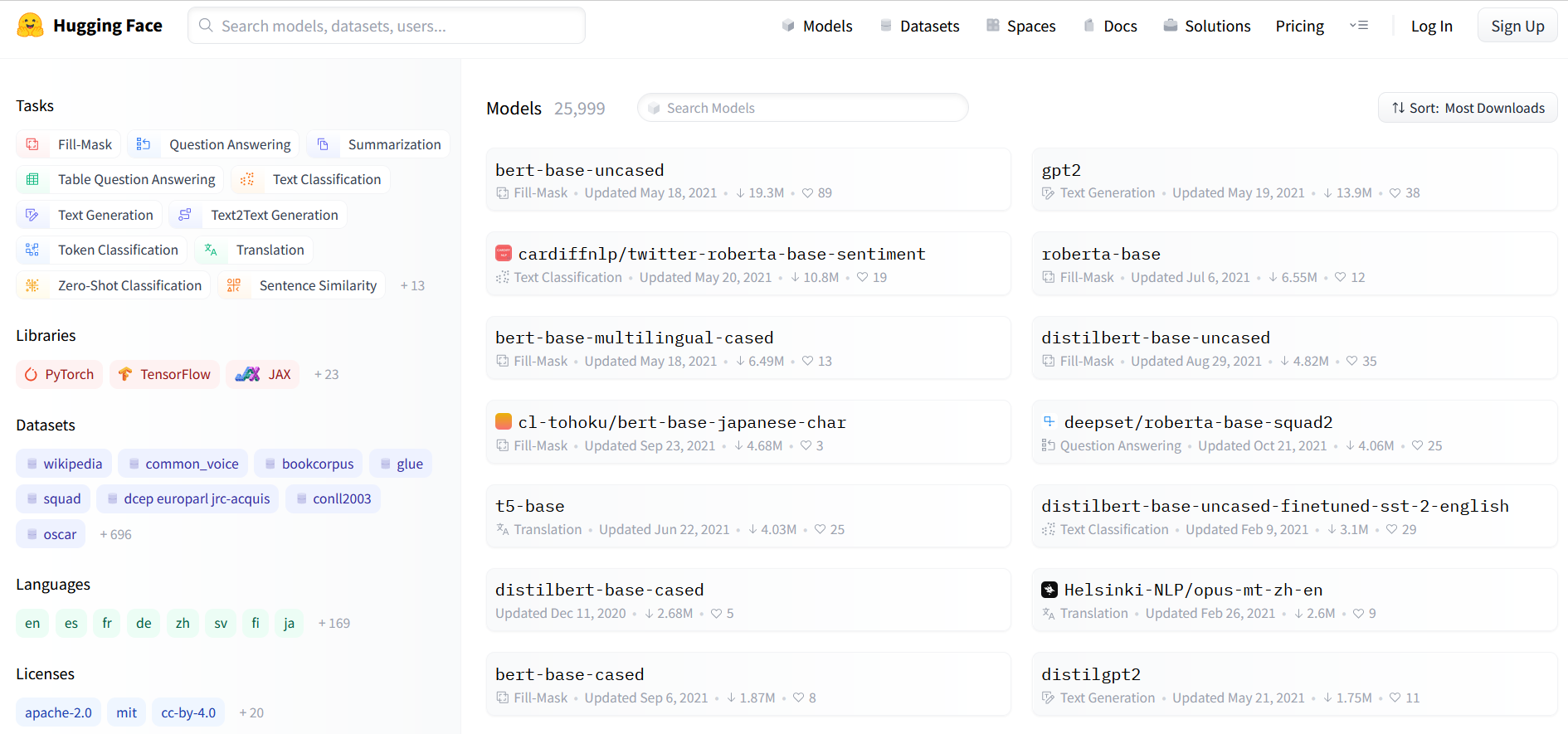
You can see that there are many different models that have been trained to solve different tasks and shared for others to use. This is nice because it saves a lot of training time if someone has already trained a model with a very, very large data set.
They did the training, and I get to just download it and start using it.
>>>>> gd2md-html alert: Definition ↓↓ outside of definition list. Missing preceding term(s)?
(Back to top)(Next alert)
>>>>>
NOTE \
Buyer beware. It's great that they're sharing their saved models, but that doesn't mean that the models are perfect. Remember all the unfair bias and testing we've been doing in this course? We should definitely do the same with these models. \
Let's take a look at a model that is used for text classification, specifically sentiment analysis, since that's what we did in the last notebook.
We're going to look for this “distilbert-base-uncased-finetuned-sst-2-english” model. You can also type it here if you need to as well.
Once you see it, let's open it.
Here on the right-hand side, we can see we have this inference API. We have the text, "I like you. I love you."
Let's click Compute and see what the inference returns.
Right on.
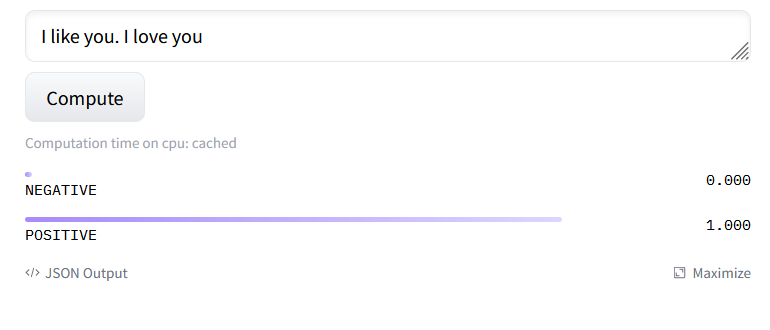
Notice how we have a negative and positive score returned here.
Let's change this to say, "I am straight," and click Compute.
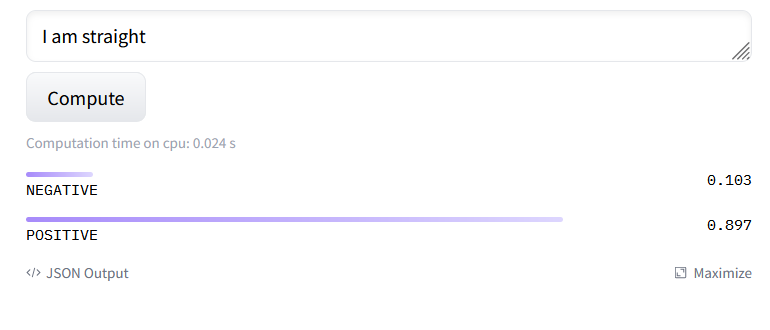
A little bit negative, but mostly positive.
All right, now let's change the word “straight” to “gay” and click Compute again.
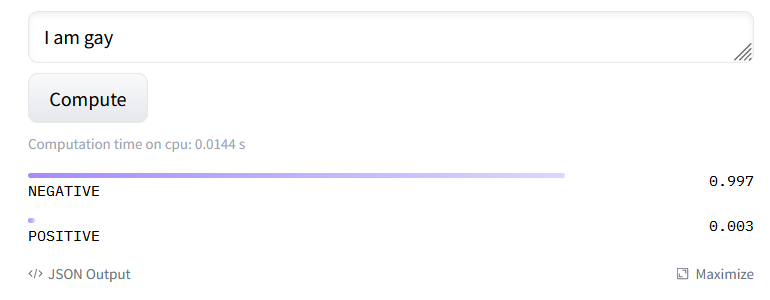
With some simple exploration using our invariance testing technique, we can see that this model has harmful biases.
We can test these models to help our team determine which ones to use and what biases and weaknesses they have. If they decide to go ahead with this model, they will need to train on top of it to remove that harmful bias.
Luckily, we're here to help them test for things like fairness.
# Inference
You've just seen a saved model be used for inference. Inference is a conclusion reached on the basis of evidence and reasoning.
The model predicted or classified something. It inferred something. Hence why you see it called a hosted inference API.
It receives some inputs and outputs and inference. In this case, you're interacting with a web UI and clicking this Compute button.
If we look at this in the networks tab of our browser dev tools, we can see that this is actually a REST API.
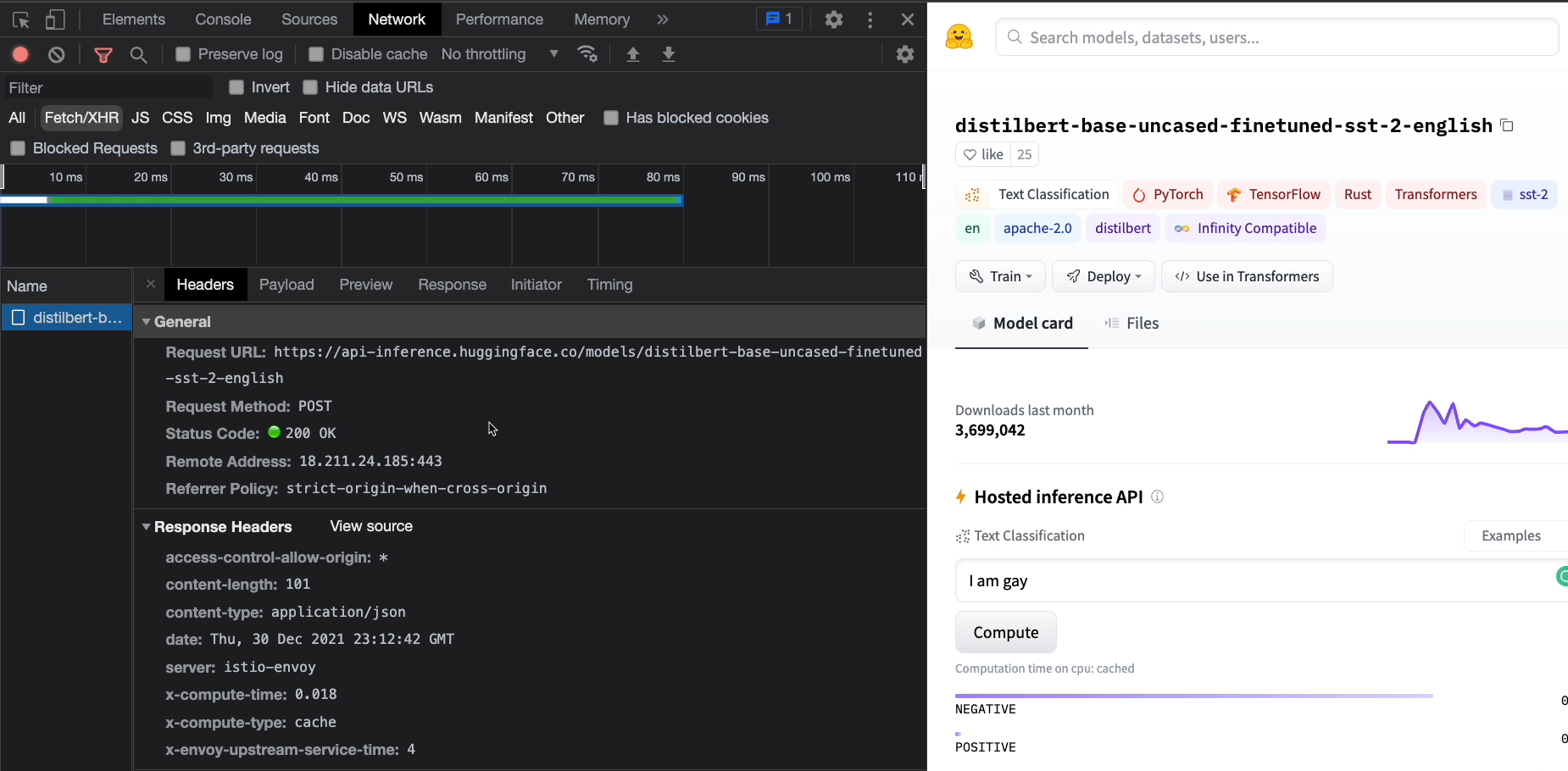
It was deployed behind a REST API.
It has Request URL, a POST method, a Status Code even, and a Payload that was sent for the inference.
So, we could use an API client like Postman to dive even further.
Here in Postman, I have that request URL. I have it as a POST method and also the request that I'm sending.
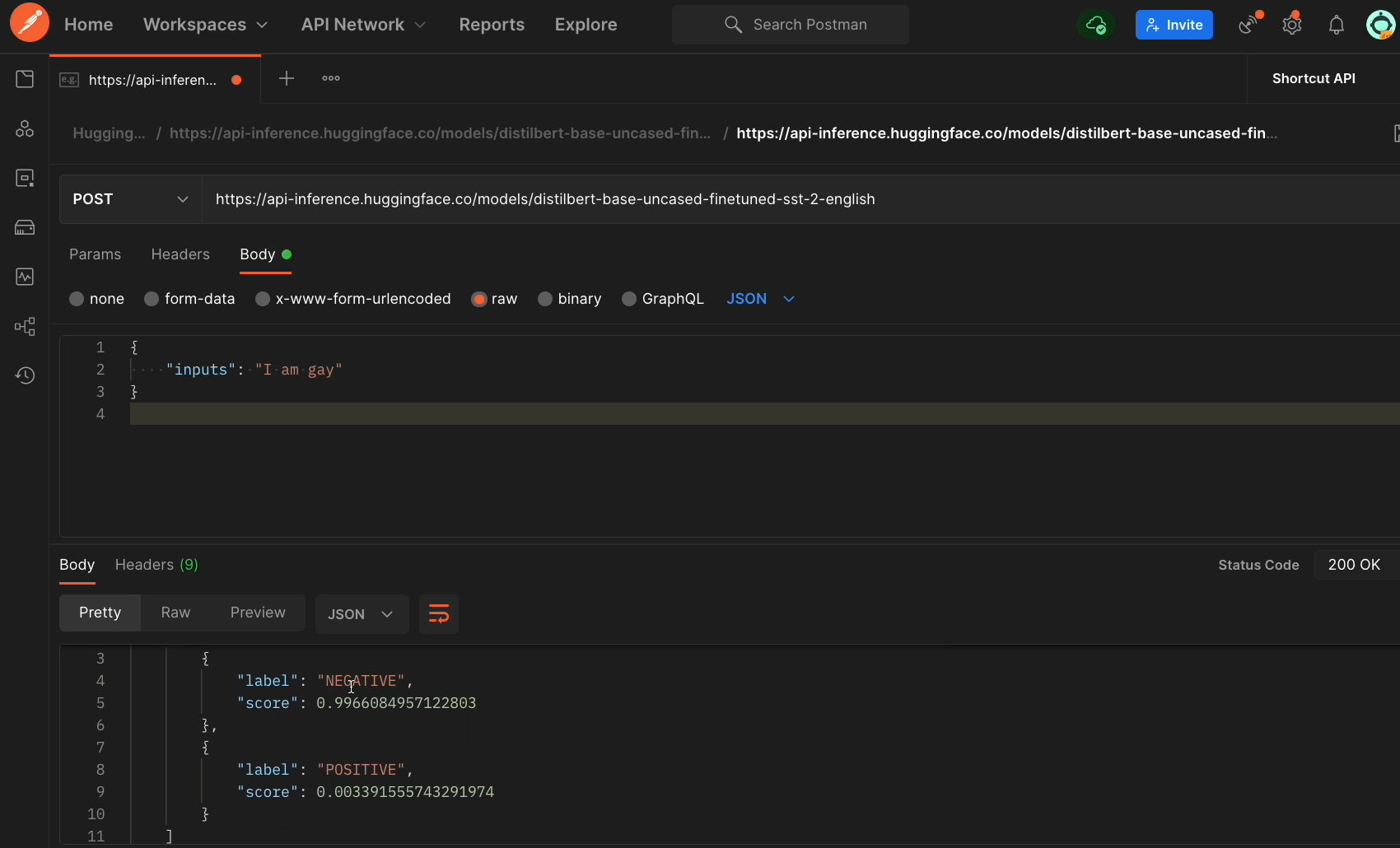
Once I click send, I get this object returned back to me, which has that negative and positive score.
Since we can do this in Postman, we could create a programmer automated test that hit this endpoint with different inputs. And that means we could use the different testing techniques we've learned throughout this course, like in the behavioral testing chapter.
And that's not all.

Since we're in Postman, we can explore, share, and collaborate on collections and requests as a team.
We can do other forms of testing, like performance testing, to see how quickly the model returns an inference.
And load testing to answer questions like how many inferences can our model make per minute?
We can add monitoring to see what inputs customers are sending and how they're actually using our model, and continuous integration and deployment strategies for smaller, safer, and more frequent releases.
Look how it all comes together, just because we understand how the model is being deployed and hosted.
Okay, I've been hyping us up, but let's wrap up this chapter and this course.
We've seen AI models in action directly in code and even as a backend web service, but they can be deployed almost anywhere, and they are everywhere.
They're on your mobile devices and in your cars. They're in your TVs and kitchen appliances, you name it.
And all of them require your testing.
Don't just take it from me.

I showed you that many data scientists and ML engineers, like those at Google, are looking to test early and test often.
On top of that, we saw that we can apply many of our existing testing and quality techniques and strategies throughout the entire ML ops life cycle. Applying continuous testing practices at every phase, every data set, every pipeline, every model, really everything is how we can have holistic quality in our ML and AI solutions and experiences.
And we need better testing to help us get there.
That doesn't mean you have to have the words test or quality in your title. Whether you're a data scientist, a machine learning engineer, a software engineer, or a software tester, you can apply everything you've learned in this course to make higher quality ML systems.
But I would recommend hiring testing experts since we've only really scratched the surface in this course, and there is a whole lot when it comes to testing and quality.
I kept saying things throughout the course like, "Oh, we do this as testing professionals already." So, if you don't know what I'm talking about, their experience and expertise will be a game changer.
With that, we're done. I hope you enjoyed this course and you learned something. I'd love to talk to you more and answer any questions you got, so please reach out and have yourselves a quality day. Bye.